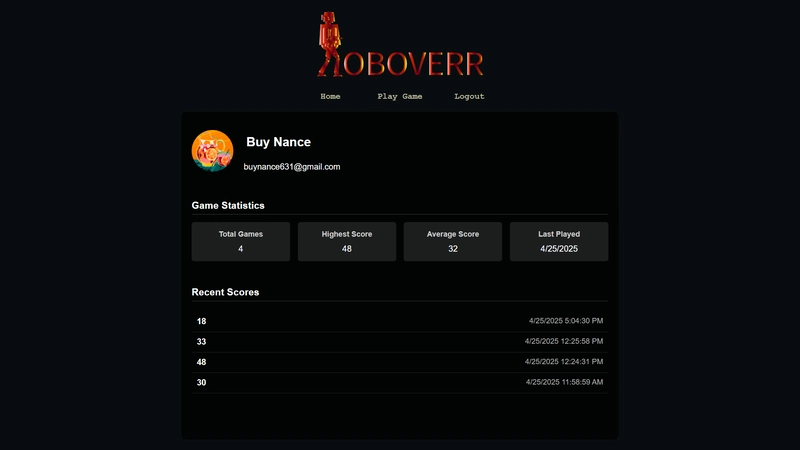
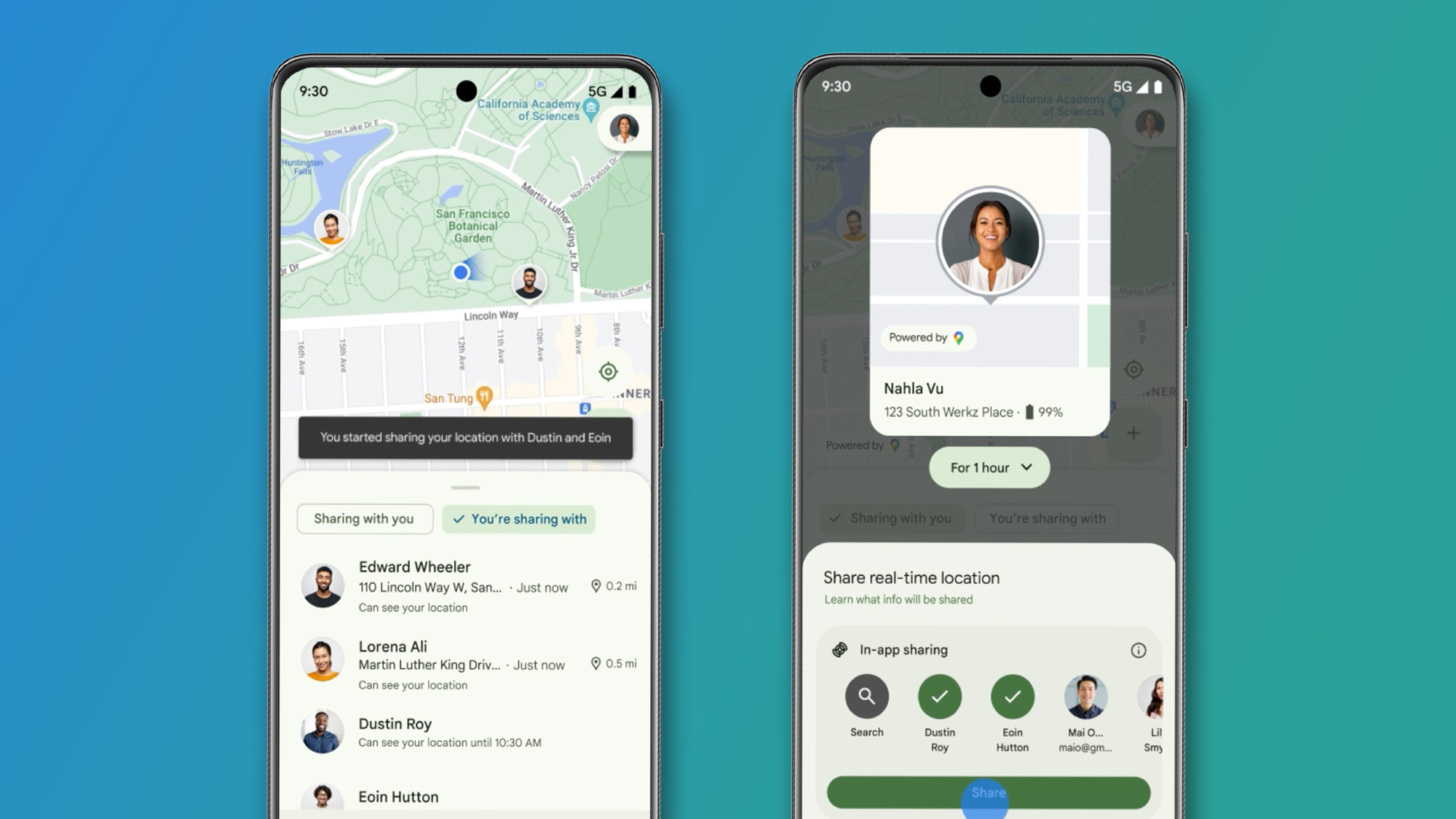
![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)
























































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)























































































































_roibu_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





 CISO’s Core Focus.webp?#)




































































































![M4 MacBook Air Drops to Just $849 - Act Fast! [Lowest Price Ever]](https://www.iclarified.com/images/news/97140/97140/97140-640.jpg)
![Apple Smart Glasses Not Close to Being Ready as Meta Targets 2025 [Gurman]](https://www.iclarified.com/images/news/97139/97139/97139-640.jpg)
![iPadOS 19 May Introduce Menu Bar, iOS 19 to Support External Displays [Rumor]](https://www.iclarified.com/images/news/97137/97137/97137-640.jpg)































































































How to Find and Extract All URLs from a Website Using Olostep Maps API and Streamlit
Introduction When building web crawlers, competitive analysis, SEO audits, or AI agents, one of the first critical tasks is finding all the URLs on a website. While traditional methods like Google search tricks, sitemap exploration, and SEO tools work, there's a faster, modern way: using Olostep Maps API. In this guide, we'll: Introduce the challenge of URL discovery Show how to build a live Streamlit app to scrape all URLs Compare it with traditional techniques (like sitemap.xml and robots.txt) Provide complete runnable Python code Target Audience: Developers, Growth Engineers, Data Scientists, SEO specialists, and Founders who need structured, scalable scraping. Why Extract All URLs? Finding every page on a website can help you: Analyze site structure (for SEO) Scrape website content efficiently Find hidden gems like orphan pages Monitor website changes Prepare data for AI agents and automation Traditional Methods (Before Olostep) 1. Sitemaps (XML Files) Webmasters often create XML sitemaps to help Google index their sites. Here's an example: https://example.com https://example.com/about To find sitemaps: Visit /sitemap.xml (e.g., https://example.com/sitemap.xml) Check /robots.txt (it usually links to the sitemap) Other possible sitemap locations: /sitemap.xml.gz /sitemap_index.xml /sitemap.php You can also Google: site:example.com filetype:xml Problems: Some websites don't maintain updated sitemaps. Not all pages may be listed. Dynamic websites (heavy JavaScript) often leave out many pages. 2. Robots.txt Example: User-agent: * Sitemap: https://example.com/sitemap.xml Disallow: /admin Good for finding disallowed URLs and sitemap links, but again not comprehensive. The Modern Solution: Olostep Maps API ✅ Find up to 100,000 URLs in seconds. ✅ No need to manually find sitemap or robots.txt. ✅ Simple API call. ✅ No server maintenance or IP bans.

Introduction
When building web crawlers, competitive analysis, SEO audits, or AI agents, one of the first critical tasks is finding all the URLs on a website.
While traditional methods like Google search tricks, sitemap exploration, and SEO tools work, there's a faster, modern way: using Olostep Maps API.
In this guide, we'll:
- Introduce the challenge of URL discovery
- Show how to build a live Streamlit app to scrape all URLs
- Compare it with traditional techniques (like sitemap.xml and robots.txt)
- Provide complete runnable Python code
Target Audience: Developers, Growth Engineers, Data Scientists, SEO specialists, and Founders who need structured, scalable scraping.
Why Extract All URLs?
Finding every page on a website can help you:
- Analyze site structure (for SEO)
- Scrape website content efficiently
- Find hidden gems like orphan pages
- Monitor website changes
- Prepare data for AI agents and automation
Traditional Methods (Before Olostep)
1. Sitemaps (XML Files)
Webmasters often create XML sitemaps to help Google index their sites. Here's an example:
To find sitemaps:
- Visit
/sitemap.xml(e.g., https://example.com/sitemap.xml) - Check
/robots.txt(it usually links to the sitemap)
Other possible sitemap locations:
/sitemap.xml.gz/sitemap_index.xml/sitemap.php
You can also Google:
site:example.com filetype:xml
Problems:
- Some websites don't maintain updated sitemaps.
- Not all pages may be listed.
- Dynamic websites (heavy JavaScript) often leave out many pages.
2. Robots.txt
Example:
User-agent: *
Sitemap: https://example.com/sitemap.xml
Disallow: /admin
Good for finding disallowed URLs and sitemap links, but again not comprehensive.
The Modern Solution: Olostep Maps API
✅ Find up to 100,000 URLs in seconds.
✅ No need to manually find sitemap or robots.txt.
✅ Simple API call.
✅ No server maintenance or IP bans.
![Oracle 23ai on ARM [ Release 23.0.0.0.0 - Develop, Learn, and Run for Free ]](https://media2.dev.to/dynamic/image/width%3D1000,height%3D500,fit%3Dcover,gravity%3Dauto,format%3Dauto/https:%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fusxsb9j32kk2td3uvt5s.png)