








































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)










































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)









































































.webp?#)


























































































![Here’s the first live demo of Android XR on Google’s prototype smart glasses [Video]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/04/google-android-xr-ted-glasses-demo-3.png?resize=1200%2C628&quality=82&strip=all&ssl=1)













![New Beats USB-C Charging Cables Now Available on Amazon [Video]](https://www.iclarified.com/images/news/97060/97060/97060-640.jpg)

![Apple M4 13-inch iPad Pro On Sale for $200 Off [Deal]](https://www.iclarified.com/images/news/97056/97056/97056-640.jpg)


















































































































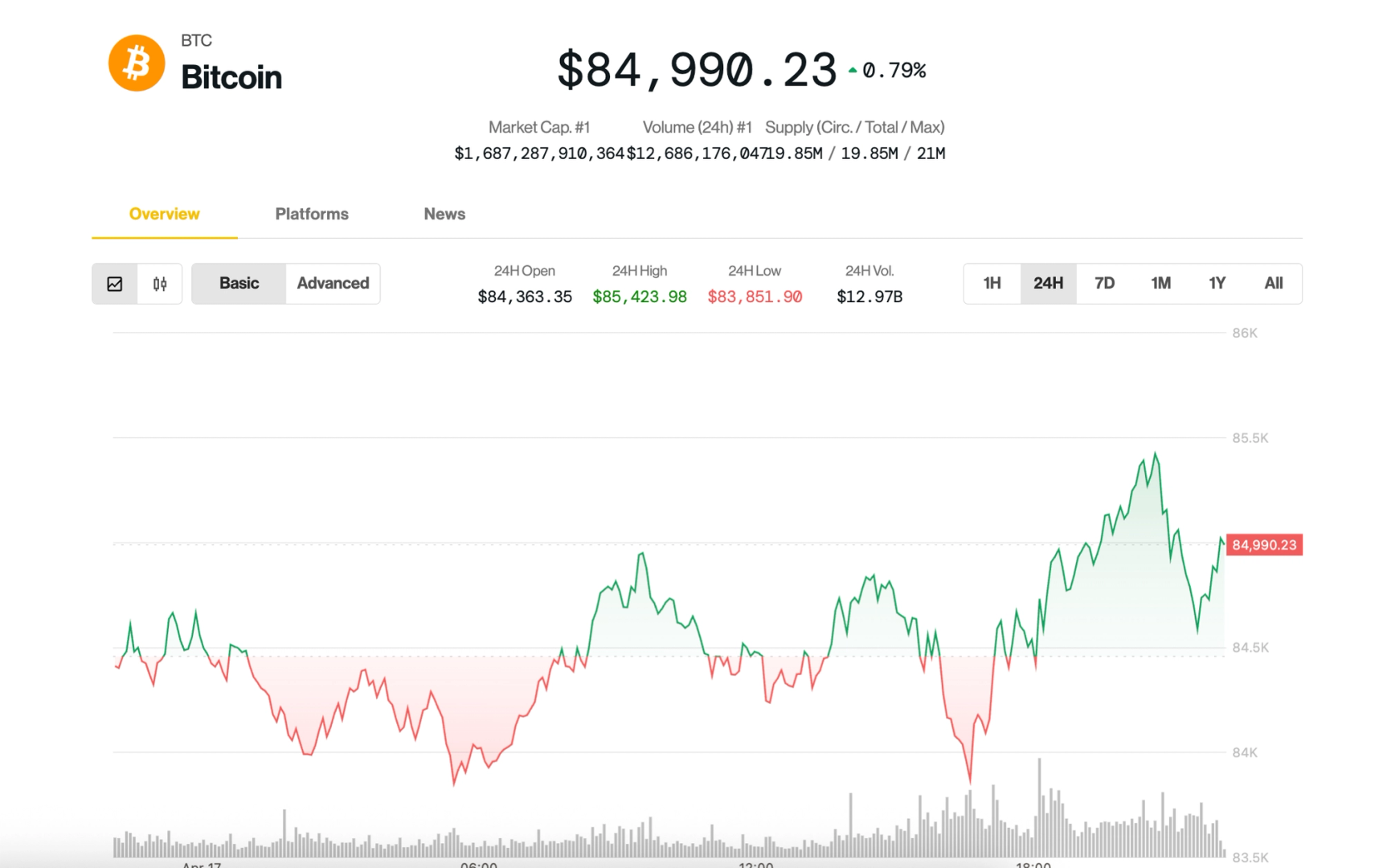


How Billions of Username Lookups Have Handled
When you sign up for a new app and see a message like "This username is already taken," it feels like a tiny inconvenience. But behind the scenes, this simple check is a massive engineering challenge, especially when dealing with billions of users. So how do companies like Google, Amazon, and Meta check username availability instantly without hammering their databases? Let’s dive into the smart strategies and data structures they use to make this process lightning-fast and scalable. 1. Redis Hashmaps: Speedy In-Memory Lookups Redis hashmaps are a favorite for exact match lookups. In this structure, each username is stored as a field with a lightweight value like a user ID. A query checks whether the username exists in this in-memory store — delivering results in microseconds. However, memory is finite, so Redis hashmaps are typically used to cache only frequently accessed or recent usernames. 2. Tries: Perfect for Prefix Matching If you need autocomplete or want to suggest alternative usernames, tries (prefix trees) are a better choice. Tries store characters as paths, allowing searches to scale with the length of the string rather than the total dataset size. They also naturally support prefix queries. To optimize memory, systems often use compressed tries like Radix Trees or limit tries to hot or recently entered usernames. 3. B+ Trees: Efficient Ordered Lookups B+ trees are common in relational databases for indexing. They support fast, sorted lookups in O(log n) time and are ideal for queries that need range or alphabetical order, like finding the next available username. Here's how: Ordered Traversal: B+ trees store data in a sorted order and keep all values in the leaf nodes linked together. This allows the system to perform fast range queries and in-order traversal. Next Best Option: If a desired username (e.g., alex) is taken, the system can quickly traverse to the next lexicographically available usernames (like alex1, alex_, alex123, etc.) without scanning the entire dataset. Prefix Search: B+ trees can also support partial matches. For example, to suggest usernames starting with john, the system can navigate directly to the leaf node where entries like john1, john_doe, or johnny reside. Efficient Suggestions: Since B+ trees maintain balance and logarithmic lookup times, even on massive datasets, they’re a great fit for generating sorted and relevant suggestions quickly. Databases like MySQL, MongoDB, and Google Cloud Spanner use B+ trees (or similar structures) to power high-performance queries over massive datasets. 4. Bloom Filters: The First Line of Defense Bloom filters are a probabilistic, memory-efficient way to check if a username might exist. If a Bloom filter says a name isn’t present, you can be sure it’s not. If it might be present, you do a deeper check in the database. They use very little memory (e.g., 1.2 GB for 1 billion usernames with 1% false positives), making them perfect for large-scale systems. Systems like Cassandra use them to avoid unnecessary disk lookups. The Power of Layering: System Architecture in Action In practice, companies combine all these tools: Load Balancing: Global (DNS-based like AWS Route 53) and local (like NGINX or AWS ELB) load balancers route requests efficiently. Bloom Filters: Fast, in-memory filters weed out usernames that definitely don’t exist. Caches (Redis/Memcached): Recently checked usernames are stored here for instant access. Distributed Databases (Cassandra/DynamoDB): If all else fails, the system queries the authoritative source. This tiered architecture minimizes latency, distributes load, and scales effortlessly across billions of users. What seems like a simple check — "Is this username taken?" — is powered by a beautiful mix of computer science and engineering. From Bloom filters and tries to Redis caches and distributed databases, every component plays a role in delivering a seamless user experience. Next time you pick a username, remember the complex machinery behind that instant response. Inspired by a brilliant system design breakdown on YouTube. Want to dive deeper into similar topics? Let me know what you'd like to explore next!

When you sign up for a new app and see a message like "This username is already taken," it feels like a tiny inconvenience. But behind the scenes, this simple check is a massive engineering challenge, especially when dealing with billions of users.
So how do companies like Google, Amazon, and Meta check username availability instantly without hammering their databases? Let’s dive into the smart strategies and data structures they use to make this process lightning-fast and scalable.
1. Redis Hashmaps: Speedy In-Memory Lookups
Redis hashmaps are a favorite for exact match lookups. In this structure, each username is stored as a field with a lightweight value like a user ID. A query checks whether the username exists in this in-memory store — delivering results in microseconds.
However, memory is finite, so Redis hashmaps are typically used to cache only frequently accessed or recent usernames.
2. Tries: Perfect for Prefix Matching
If you need autocomplete or want to suggest alternative usernames, tries (prefix trees) are a better choice. Tries store characters as paths, allowing searches to scale with the length of the string rather than the total dataset size. They also naturally support prefix queries.
To optimize memory, systems often use compressed tries like Radix Trees or limit tries to hot or recently entered usernames.
3. B+ Trees: Efficient Ordered Lookups
B+ trees are common in relational databases for indexing. They support fast, sorted lookups in O(log n) time and are ideal for queries that need range or alphabetical order, like finding the next available username.
Here's how:
- Ordered Traversal: B+ trees store data in a sorted order and keep all values in the leaf nodes linked together. This allows the system to perform fast range queries and in-order traversal.
- Next Best Option: If a desired username (e.g., alex) is taken, the system can quickly traverse to the next lexicographically available usernames (like alex1, alex_, alex123, etc.) without scanning the entire dataset.
- Prefix Search: B+ trees can also support partial matches. For example, to suggest usernames starting with john, the system can navigate directly to the leaf node where entries like john1, john_doe, or johnny reside.
- Efficient Suggestions: Since B+ trees maintain balance and logarithmic lookup times, even on massive datasets, they’re a great fit for generating sorted and relevant suggestions quickly.
Databases like MySQL, MongoDB, and Google Cloud Spanner use B+ trees (or similar structures) to power high-performance queries over massive datasets.
4. Bloom Filters: The First Line of Defense
Bloom filters are a probabilistic, memory-efficient way to check if a username might exist. If a Bloom filter says a name isn’t present, you can be sure it’s not. If it might be present, you do a deeper check in the database.
They use very little memory (e.g., 1.2 GB for 1 billion usernames with 1% false positives), making them perfect for large-scale systems. Systems like Cassandra use them to avoid unnecessary disk lookups.
The Power of Layering: System Architecture in Action
In practice, companies combine all these tools:
- Load Balancing: Global (DNS-based like AWS Route 53) and local (like NGINX or AWS ELB) load balancers route requests efficiently.
- Bloom Filters: Fast, in-memory filters weed out usernames that definitely don’t exist.
- Caches (Redis/Memcached): Recently checked usernames are stored here for instant access.
- Distributed Databases (Cassandra/DynamoDB): If all else fails, the system queries the authoritative source.
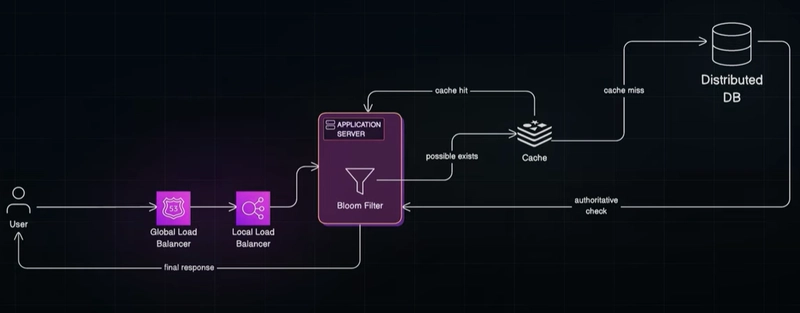
This tiered architecture minimizes latency, distributes load, and scales effortlessly across billions of users.
What seems like a simple check — "Is this username taken?" — is powered by a beautiful mix of computer science and engineering. From Bloom filters and tries to Redis caches and distributed databases, every component plays a role in delivering a seamless user experience.
Next time you pick a username, remember the complex machinery behind that instant response.
Inspired by a brilliant system design breakdown on YouTube. Want to dive deeper into similar topics? Let me know what you'd like to explore next!


