![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






















































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)



























































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



























































































![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)
































































































































GPT-4.1 vs Claude 3.7 Sonnet vs Gemini 2.5 Pro Comparison
OpenAI has recently announced a new class of GPT models for their API, known as the GPT-4.1 series. This series includes the standard GPT-4.1, a smaller version called 4.1-mini, and OpenAI’s first-ever 'nano' model, the 4.1-nano. These models feature larger context windows, capable of supporting up to 1 million context tokens, and are designed to enhance long-context comprehension. OpenAI promises improvements in areas such as coding and instruction-following, among others. In light of this announcement, it's worth comparing the GPT-4.1 models with Claude and Google’s flagship models, Claude 3.7 Sonnet and Gemini 2.5 Pro, respectively. Here’s an in-depth comparison of GPT-4.1. But first, let's explore the details of the GPT-4.1 release and what it has to offer. OpenAI GPT-4.1 Overview What is GPT-4.1? GPT-4.1 is OpenAI’s latest step in advancing AI for practical applications, with a strong focus on coding and instruction-following this time. Available through OpenAI’s API, it comes in three variants—GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano—each tailored for different scales of use, from large projects to lightweight tasks. Unlike its predecessors, GPT-4.1 is not accessible via ChatGPT. GPT-4.1 Key Features Massive Context Window: GPT-4.1 can handle 1,047,576 tokens, roughly 750,000 words, allowing it to process entire codebases or lengthy documents in one go. This is ideal for complex software projects where context is critical. Multimodal Input: It accepts both text and images, enabling tasks like analyzing diagrams alongside code or generating descriptions from visual inputs. Coding Optimization: OpenAI designed GPT-4.1 with developer feedback in mind, improving its ability to generate clean code, adhere to formats, and make fewer unnecessary edits, particularly for frontend development. Instruction Following: The model excels at understanding and executing detailed instructions, making it versatile for tasks beyond coding, such as drafting technical documentation or automating workflows. Pricing: At $2 per million input tokens (cached input: $0.50) and $8 per million output tokens, it’s competitively priced for its capabilities, with cheaper options for the mini ($0.40 input) and nano ($0.10 input) variants (OpenAI Platform). Comparing GPT-4.1 with Claude 3.7 Sonnet and Gemini 2.5 Pro To understand how GPT-4.1 stacks up, let’s introduce its competitors and compare them across key areas: coding performance, context window, multimodal capabilities, pricing, and unique features. GPT-4.1 vs Claude 3.7 Sonnet Claude 3.7 Sonnet, released in February 2025, is billed as the company’s most intelligent model yet. It’s a hybrid reasoning model, which means it can switch between quick responses for general tasks and a “Thinking Mode” for step-by-step problem-solving. This makes it particularly strong in coding, content generation, and data analysis. Overall, Claude 3.7 Sonnet is better than GPT-4.1 for coding-related tasks or otherwise. GPT-4.1 Gemini 2.5 Pro Google’s Gemini 2.5 Pro, launched in March 2025, is an experimental reasoning model designed for complex tasks like coding, math, and logic. It supports a wide range of inputs—text, images, audio, and video—and leads several benchmarks, positioning it as a versatile and powerful option. When compared with GPT-4.1, the results are more complicated, let’s see how: Showdown: GPT-4.1 vs Claude 3.7 Sonnet vs Gemini 2.5 Pro Coding Performance Coding is a core strength for all three models, but their performance varies based on benchmarks and real-world tests. Gemini 2.5 Pro: Tops the SWE-bench Verified benchmark at 63.8%, suggesting it handles coding challenges with high accuracy. In practical tests, it created a fully functional flight simulator and a Rubik’s Cube solver in one attempt, showcasing its ability to generate complex, working code. Claude 3.7 Sonnet: Scores 62.3% on SWE-bench, with a boosted 70.3% when using a custom scaffold, indicating potential for optimization. However, it struggled in some tests, like producing a faulty flight simulator and failing to solve a Rubik’s Cube correctly. Its Thinking Mode helps break down problems, which can be a boon for debugging. GPT-4.1: At 52–54.6%, it lags behind but still outperforms older OpenAI models. Its design focuses on frontend coding and format adherence, making it reliable for specific tasks. While specific coding examples are less documented, its large context window suggests it can handle extensive codebases effectively. Benchmarks like SWE-bench measure how well models fix real-world coding issues, but they don’t capture everything. Gemini’s edge may reflect better optimization for these tests, while Claude’s Thinking Mode and GPT-4.1’s context capacity could shine in different scenarios. Context Window The context window determines how much information a model can process at once, crucial for large projects. GPT-4.1 and Gemini 2.5 Pro: Both offer over 1 million tokens, equiv
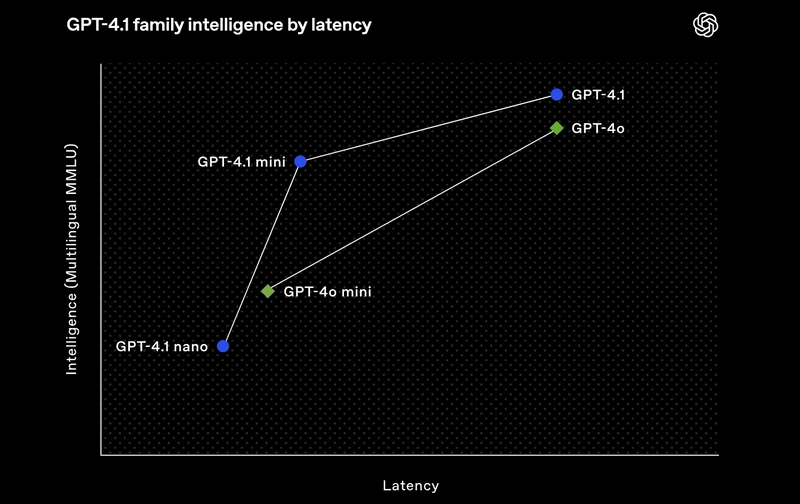
OpenAI has recently announced a new class of GPT models for their API, known as the GPT-4.1 series. This series includes the standard GPT-4.1, a smaller version called 4.1-mini, and OpenAI’s first-ever 'nano' model, the 4.1-nano. These models feature larger context windows, capable of supporting up to 1 million context tokens, and are designed to enhance long-context comprehension. OpenAI promises improvements in areas such as coding and instruction-following, among others.
In light of this announcement, it's worth comparing the GPT-4.1 models with Claude and Google’s flagship models, Claude 3.7 Sonnet and Gemini 2.5 Pro, respectively. Here’s an in-depth comparison of GPT-4.1.
But first, let's explore the details of the GPT-4.1 release and what it has to offer.
OpenAI GPT-4.1 Overview
What is GPT-4.1?
GPT-4.1 is OpenAI’s latest step in advancing AI for practical applications, with a strong focus on coding and instruction-following this time. Available through OpenAI’s API, it comes in three variants—GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano—each tailored for different scales of use, from large projects to lightweight tasks. Unlike its predecessors, GPT-4.1 is not accessible via ChatGPT.
GPT-4.1 Key Features
- Massive Context Window: GPT-4.1 can handle 1,047,576 tokens, roughly 750,000 words, allowing it to process entire codebases or lengthy documents in one go. This is ideal for complex software projects where context is critical.
- Multimodal Input: It accepts both text and images, enabling tasks like analyzing diagrams alongside code or generating descriptions from visual inputs.
- Coding Optimization: OpenAI designed GPT-4.1 with developer feedback in mind, improving its ability to generate clean code, adhere to formats, and make fewer unnecessary edits, particularly for frontend development.
- Instruction Following: The model excels at understanding and executing detailed instructions, making it versatile for tasks beyond coding, such as drafting technical documentation or automating workflows.
- Pricing: At $2 per million input tokens (cached input: $0.50) and $8 per million output tokens, it’s competitively priced for its capabilities, with cheaper options for the mini ($0.40 input) and nano ($0.10 input) variants (OpenAI Platform).
Comparing GPT-4.1 with Claude 3.7 Sonnet and Gemini 2.5 Pro
To understand how GPT-4.1 stacks up, let’s introduce its competitors and compare them across key areas: coding performance, context window, multimodal capabilities, pricing, and unique features.
GPT-4.1 vs Claude 3.7 Sonnet
Claude 3.7 Sonnet, released in February 2025, is billed as the company’s most intelligent model yet. It’s a hybrid reasoning model, which means it can switch between quick responses for general tasks and a “Thinking Mode” for step-by-step problem-solving. This makes it particularly strong in coding, content generation, and data analysis. Overall, Claude 3.7 Sonnet is better than GPT-4.1 for coding-related tasks or otherwise.
GPT-4.1 Gemini 2.5 Pro
Google’s Gemini 2.5 Pro, launched in March 2025, is an experimental reasoning model designed for complex tasks like coding, math, and logic. It supports a wide range of inputs—text, images, audio, and video—and leads several benchmarks, positioning it as a versatile and powerful option. When compared with GPT-4.1, the results are more complicated, let’s see how:
Showdown: GPT-4.1 vs Claude 3.7 Sonnet vs Gemini 2.5 Pro
Coding Performance
Coding is a core strength for all three models, but their performance varies based on benchmarks and real-world tests.
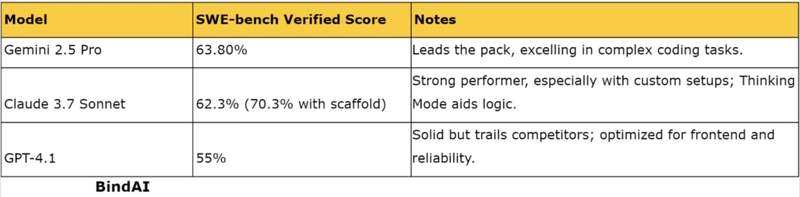
- Gemini 2.5 Pro: Tops the SWE-bench Verified benchmark at 63.8%, suggesting it handles coding challenges with high accuracy. In practical tests, it created a fully functional flight simulator and a Rubik’s Cube solver in one attempt, showcasing its ability to generate complex, working code.
- Claude 3.7 Sonnet: Scores 62.3% on SWE-bench, with a boosted 70.3% when using a custom scaffold, indicating potential for optimization. However, it struggled in some tests, like producing a faulty flight simulator and failing to solve a Rubik’s Cube correctly. Its Thinking Mode helps break down problems, which can be a boon for debugging.
- GPT-4.1: At 52–54.6%, it lags behind but still outperforms older OpenAI models. Its design focuses on frontend coding and format adherence, making it reliable for specific tasks. While specific coding examples are less documented, its large context window suggests it can handle extensive codebases effectively.
Benchmarks like SWE-bench measure how well models fix real-world coding issues, but they don’t capture everything. Gemini’s edge may reflect better optimization for these tests, while Claude’s Thinking Mode and GPT-4.1’s context capacity could shine in different scenarios.
Context Window
The context window determines how much information a model can process at once, crucial for large projects.

- GPT-4.1 and Gemini 2.5 Pro: Both offer over 1 million tokens, equivalent to processing a novel like War and Peace multiple times. This makes them ideal for understanding entire codebases or lengthy documents without losing context.
- Claude 3.7 Sonnet: At 200,000 tokens, it’s significantly smaller but still substantial, capable of handling large files or projects, though it may need more segmentation for massive tasks.
For developers working on sprawling software, GPT-4.1 and Gemini have a clear advantage, but Claude’s capacity is sufficient for most practical needs.
Multimodal Capabilities
Multimodal support allows models to process different data types, enhancing their versatility.

- Gemini 2.5 Pro: Its ability to handle text, images, audio, and video makes it uniquely versatile, useful for tasks like analyzing multimedia alongside code or generating interactive simulations.
- GPT-4.1: Supports text and images, which is sufficient for tasks like interpreting diagrams or UI mockups in coding projects but less broad than Gemini.
- Claude 3.7 Sonnet: Primarily text-focused with some vision capabilities, it’s less flexible for multimedia but excels in text-based reasoning and coding.
Gemini’s multimodal edge could be a game-changer for projects involving diverse data, while GPT-4.1 and Claude are more specialized for text-driven tasks.
GPT-4.1 Pricing Comparison vs Claude 3.7 Sonnet and Gemini 2.5 Pro
Cost is a key factor for developers and businesses integrating these models.
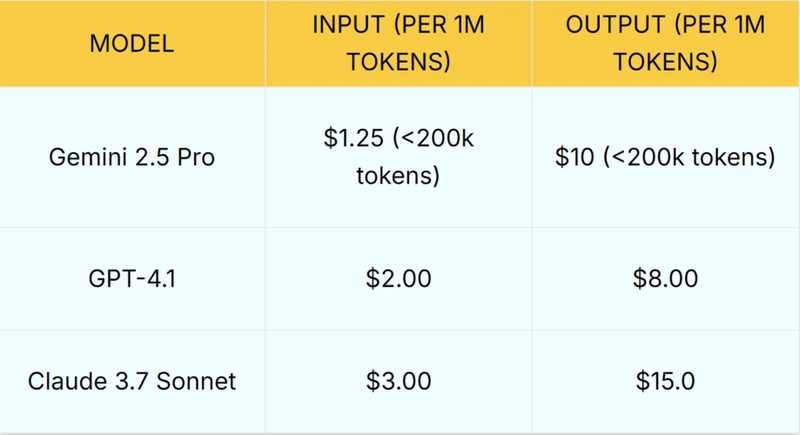
- Gemini 2.5 Pro: The most cost-effective for smaller prompts @$1.25 for input and $10 for output, though prices rise for inputs over 200,000 tokens ($2.50 input, $15 output). This makes it attractive for frequent, smaller tasks.
- GPT-4.1: GPT-4.1 costs $2 for input and $8 for output tokens, and a 50% discount for batch API, offering a balanced cost, cheaper than Claude for both input and output, and more predictable than Gemini for large inputs. Its mini and nano variants are even more affordable.
- Claude 3.7 Sonnet: The priciest, especially for outputs ($15/million tokens), though features like prompt caching can reduce costs by up to 90%. Its Thinking Mode, however, requires a paid subscription for full access.
Budget-conscious developers might lean toward Gemini or GPT-4.1, while Claude’s higher cost may be justified for its reasoning features in specific cases.
Unique Features
Each model has distinct capabilities that set it apart.
- GPT-4.1: Its optimization for frontend coding and reliable format adherence makes it a go-to for web development tasks. The large context window supports comprehensive project analysis, and its API integration is robust for custom applications.
- Claude 3.7 Sonnet: The Thinking Mode is a standout, allowing users to see the model’s reasoning process, which is invaluable for complex coding or debugging. It also offers a command-line tool, Claude Code, for direct coding tasks (Anthropic).
- Gemini 2.5 Pro: Its multimodal support and top benchmark performance make it versatile for both coding and creative tasks, like generating interactive simulations or animations from simple prompts. It’s also free in its experimental phase, broadening access.
These features mean your choice depends on whether you prioritize transparency (Claude), versatility (Gemini), or coding reliability (GPT-4.1).
GPT-4.1 Coding Comparison with Claude 3.7 Sonnet and Gemini 2.5 Pro
Coding is a critical application for these models, so let’s explore how they perform in code generation, debugging, and understanding codebases.
Code Generation
Generating accurate, functional code from natural language prompts is a key test.
- Gemini 2.5 Pro: Excels here, producing a working flight simulator with a Minecraft-style city and a 3D Rubik’s Cube solver in single attempts. It also handled a complex JavaScript visualization of a ball bouncing in a 4D tesseract flawlessly, highlighting collision points as requested (Composio).
- Claude 3.7 Sonnet: Performed well in some tasks, like the 4D tesseract visualization, but faltered in others, producing a sideways plane in the flight simulator and incorrect colors in the Rubik’s Cube solver. Its Thinking Mode can help refine prompts, but it’s less consistent than Gemini.
- GPT-4.1: While specific examples are fewer, its SWE-bench score and developer-focused design suggest it generates reliable code, especially for frontend tasks. Its large context window ensures it understands detailed requirements, reducing errors in complex projects.
Gemini appears to lead in raw generation accuracy, but GPT-4.1’s context capacity and Claude’s reasoning could shine with tailored prompts.
Debugging
Identifying and fixing code errors is another vital skill.
- Claude 3.7 Sonnet: Thinking Mode is a major asset, allowing the model to walk through code step by step, pinpointing issues logically. This transparency can make debugging more intuitive, especially for intricate bugs.
- Gemini 2.5 Pro: Its strong reasoning capabilities help it suggest fixes by analyzing code context, as seen in its high SWE-bench score. It’s likely effective at catching errors in diverse programming scenarios.
- GPT-4.1: With its instruction-following prowess, it can debug effectively when given clear error descriptions. Its ability to process large code snippets ensures it considers the full context, reducing oversight.
Claude’s visible reasoning gives it an edge for teaching or collaborative debugging, while Gemini and GPT-4.1 are robust for quick fixes.
Understanding Code
Understanding existing code is essential for maintenance, refactoring, or extending projects.
- GPT-4.1: Its 1-million-token context window allows it to ingest entire codebases, making it adept at answering questions about structure, dependencies, or functionality. This is particularly useful for legacy systems or large-scale software.
- Gemini 2.5 Pro: Similarly equipped with a massive context window, it can analyze code comprehensively and even integrate multimedia inputs, like UI designs, to provide richer insights.
- Claude 3.7 Sonnet: Though limited to 200,000 tokens, it can still handle significant codebases. Its reasoning mode helps explain code logic clearly, which is valuable for onboarding new developers or auditing projects.
For massive projects, GPT-4.1 and Gemini have the upper hand, but Claude’s explanations are unmatched for clarity.
GPT-4.1 Prompts to Test
Here are some coding and ‘instruction-following’ NLP prompts that you can use to test GPT-4.1 capabilities and compare them with Gemini 2.5 Pro and Claude 3.7 Sonnet here:
- Write a Python function that accepts a string and returns a new string where each character is repeated twice. For example, ‘abc’ should become ‘aabbcc’.
- Implement a binary search algorithm in Python that finds an element in a sorted list. Ensure the code handles the case where the element is not found.
- Create a Python class Person with attributes for name, age, and gender, and include a method that prints out a personalized greeting based on the attributes.
- Explain how to use Git to clone a repository, create a new branch, and push changes to the remote repository.
- Given a list of dictionary objects representing employees, write a Python function that sorts them by age in descending order.
- Describe the steps to deploy a basic Django app to Heroku, including setting up a PostgreSQL database and managing static files.
Conclusion
GPT-4.1, Claude 3.7 Sonnet, and Gemini 2.5 Pro are at the forefront of AI technology, each pushing the boundaries in coding and beyond. GPT-4.1 provides a solid foundation for developers with its strong focus on coding and extensive context capacity. Claude 3.7 Sonnet emphasizes transparency and reasoning, while Gemini 2.5 Pro excels in benchmark performance and multimodal flexibility.
You can try GPT-4.1 on the OpenAI API playground, access Gemini 2.5 Pro on its website, and explore Claude 3.7 Sonnet here.