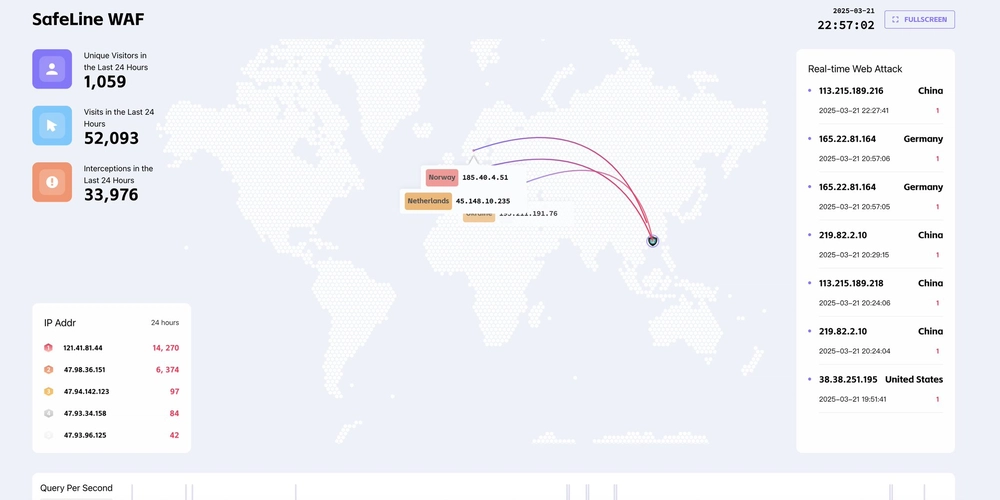












































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)





























































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)









































































































.png?#)




.jpg?#)
































_Christophe_Coat_Alamy.jpg?#)
































































































![Rapidus in Talks With Apple as It Accelerates Toward 2nm Chip Production [Report]](https://www.iclarified.com/images/news/96937/96937/96937-640.jpg)




























































































































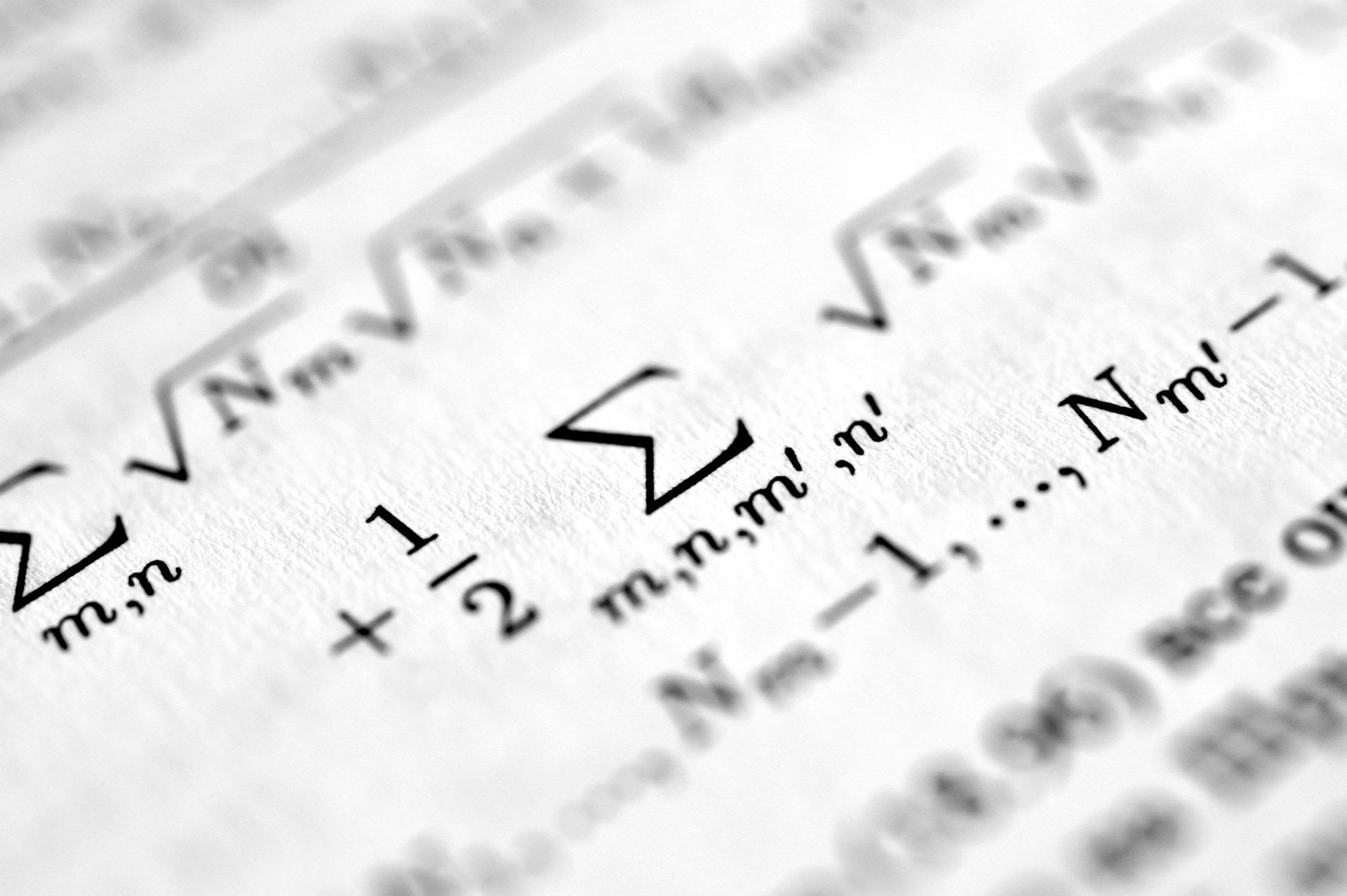


Fine-Tuning e RAG: Entendendo as Estratégias para Personalizar um Chatbot com IA
Para tornar um chatbot mais preciso e eficiente, é essencial definir como ele aprende e acessa informações. O Fine-Tuning permite que o modelo aprenda novas informações de forma definitiva, como uma aula particular que ele nunca esquece - embora, com o tempo, tanta informação acumulada possa deixá-lo um pouco confuso. Já o RAG combina busca e geração de texto para fornecer respostas sempre atualizadas, funcionando como um aluno esperto que sempre consulta as anotações mais atualizadas antes de responder. Vamos explorar como essas estratégias funcionam, suas vantagens e quando usar cada uma. 1. Fine-Tuning – Memória de Longo Prazo O fine-tuning é um processo onde um modelo pré-treinado (como o GPT-4, LLaMA, Claude e Gemini) é ajustado com novos exemplos específicos para um domínio. Como funciona? Você fornece um conjunto de dados estruturado no formato input → output para o treinamento. O modelo aprende novas informações e padrões, ajustando seus pesos internos – valores numéricos que determinam como a rede neural processa os dados. Esses pesos armazenam o conhecimento adquirido, permitindo que o modelo gere respostas sem precisar consultar uma base de conhecimento externa. Memória no Fine-Tuning Memória de Longo Prazo O conhecimento aprendido durante o treinamento é armazenado nos pesos da rede neural, que controlam a forma como o modelo transforma entradas em respostas. Após o treinamento, os pesos não mudam automaticamente com novas informações. Isso significa que o modelo não se atualiza dinamicamente – se precisar aprender algo novo, é necessário um novo fine-tuning. O que são os Pesos (Weights) em uma Rede Neural? Os pesos em uma rede neural são valores numéricos ajustáveis que determinam a importância de cada conexão entre os neurônios artificiais. Eles funcionam como parâmetros que modulam a forma como os dados de entrada são processados e transformados em saída. Durante o treinamento de um modelo, esses pesos são ajustados repetidamente através de algoritmos de otimização, como o backpropagation, para minimizar erros e melhorar a precisão das respostas. Esse ajuste é o que permite ao modelo aprender padrões e armazenar conhecimento, funcionando como uma memória de longo prazo. Quanto mais treinado um modelo for, mais refinados serão seus pesos, resultando em respostas mais precisas e adequadas ao contexto aprendido. Vantagens: Respostas rápidas e diretas, pois o conhecimento já está embutido no modelo. Funciona bem para tarefas específicas como suporte técnico ou linguagem especializada. Desvantagens: Não é fácil de atualizar – se novas informações surgirem, é necessário um novo treinamento. Pode ser caro e demorado. Exemplo de uso: Um chatbot médico treinado para responder perguntas sobre cardiologia com base em milhares de artigos médicos. 2. RAG (Retrieval-Augmented Generation) – Memória de Curto e Longo Prazo O RAG (Geração Aumentada por Recuperação) combina busca e geração de texto, permitindo que o LLM consulte uma base de conhecimento antes de formular sua resposta. Como funciona? O sistema armazena documentos em um banco de dados vetorial Quando recebe uma pergunta, ele busca os textos mais relevantes e os envia como contexto para o LLM. O modelo usa essa informação para gerar uma resposta precisa. Fluxo do processo: O usuário faz uma pergunta. O sistema identifica o documento com o conteúdo mais próximo em significado. Um prompt é gerado, combinando a pergunta do usuário com o conteúdo recuperado, orientando o LLM a produzir uma resposta contextualizada e precisa. Memória no RAG Memória de Curto e Longo Prazo Curto Prazo: O modelo recebe o contexto relevante no momento da geração da resposta, mas não "aprende" esse conteúdo permanentemente. Longo Prazo: O armazenamento das informações acontece em uma base vetorial, que pode ser consultada sempre que necessário. O modelo se mantém atualizado sem precisar de um novo treinamento, pois busca sempre os dados mais recentes. Search-Based dentro do RAG O processo de recuperação de informações no RAG é baseado em Search-Based, que busca documentos relevantes antes de passar os dados ao modelo de IA. No entanto, diferente do Search-Based puro, que apenas retorna os documentos encontrados, o RAG processa esses dados com um LLM para formular uma resposta mais elaborada e natural. O que são Bancos Vetoriais? Os bancos de dados vetoriais são sistemas especializados em armazenar e recuperar embeddings de forma eficiente. Diferente de bancos relacionais (como MySQL), que armazenam dados em tabelas, os bancos vetoriais armazenam vetores gerados a partir de embeddings em um espaço multidimensional, permitindo buscas por similaridade sem a necessidade de correspondência exata entre palavras ou frases. Isso os torna essenciais para aplicações de inteligência artificial que precisam encontrar

Para tornar um chatbot mais preciso e eficiente, é essencial definir como ele aprende e acessa informações. O Fine-Tuning permite que o modelo aprenda novas informações de forma definitiva, como uma aula particular que ele nunca esquece - embora, com o tempo, tanta informação acumulada possa deixá-lo um pouco confuso. Já o RAG combina busca e geração de texto para fornecer respostas sempre atualizadas, funcionando como um aluno esperto que sempre consulta as anotações mais atualizadas antes de responder.
Vamos explorar como essas estratégias funcionam, suas vantagens e quando usar cada uma.
1. Fine-Tuning – Memória de Longo Prazo
O fine-tuning é um processo onde um modelo pré-treinado (como o GPT-4, LLaMA, Claude e Gemini) é ajustado com novos exemplos específicos para um domínio.
Como funciona?
- Você fornece um conjunto de dados estruturado no formato
input → outputpara o treinamento. - O modelo aprende novas informações e padrões, ajustando seus pesos internos – valores numéricos que determinam como a rede neural processa os dados.
- Esses pesos armazenam o conhecimento adquirido, permitindo que o modelo gere respostas sem precisar consultar uma base de conhecimento externa.
Memória no Fine-Tuning
Memória de Longo Prazo
- O conhecimento aprendido durante o treinamento é armazenado nos pesos da rede neural, que controlam a forma como o modelo transforma entradas em respostas.
- Após o treinamento, os pesos não mudam automaticamente com novas informações. Isso significa que o modelo não se atualiza dinamicamente – se precisar aprender algo novo, é necessário um novo fine-tuning.
O que são os Pesos (Weights) em uma Rede Neural?
Os pesos em uma rede neural são valores numéricos ajustáveis que determinam a importância de cada conexão entre os neurônios artificiais. Eles funcionam como parâmetros que modulam a forma como os dados de entrada são processados e transformados em saída. Durante o treinamento de um modelo, esses pesos são ajustados repetidamente através de algoritmos de otimização, como o backpropagation, para minimizar erros e melhorar a precisão das respostas. Esse ajuste é o que permite ao modelo aprender padrões e armazenar conhecimento, funcionando como uma memória de longo prazo. Quanto mais treinado um modelo for, mais refinados serão seus pesos, resultando em respostas mais precisas e adequadas ao contexto aprendido.
Vantagens:
- Respostas rápidas e diretas, pois o conhecimento já está embutido no modelo.
- Funciona bem para tarefas específicas como suporte técnico ou linguagem especializada.
Desvantagens:
- Não é fácil de atualizar – se novas informações surgirem, é necessário um novo treinamento.
- Pode ser caro e demorado.
Exemplo de uso:
- Um chatbot médico treinado para responder perguntas sobre cardiologia com base em milhares de artigos médicos.
2. RAG (Retrieval-Augmented Generation) – Memória de Curto e Longo Prazo
O RAG (Geração Aumentada por Recuperação) combina busca e geração de texto, permitindo que o LLM consulte uma base de conhecimento antes de formular sua resposta.
Como funciona?
- O sistema armazena documentos em um banco de dados vetorial
- Quando recebe uma pergunta, ele busca os textos mais relevantes e os envia como contexto para o LLM.
- O modelo usa essa informação para gerar uma resposta precisa.
-
Fluxo do processo:
- O usuário faz uma pergunta.
- O sistema identifica o documento com o conteúdo mais próximo em significado.
- Um prompt é gerado, combinando a pergunta do usuário com o conteúdo recuperado, orientando o LLM a produzir uma resposta contextualizada e precisa.
Memória no RAG
Memória de Curto e Longo Prazo
- Curto Prazo: O modelo recebe o contexto relevante no momento da geração da resposta, mas não "aprende" esse conteúdo permanentemente.
- Longo Prazo: O armazenamento das informações acontece em uma base vetorial, que pode ser consultada sempre que necessário.
- O modelo se mantém atualizado sem precisar de um novo treinamento, pois busca sempre os dados mais recentes.
Search-Based dentro do RAG
O processo de recuperação de informações no RAG é baseado em Search-Based, que busca documentos relevantes antes de passar os dados ao modelo de IA. No entanto, diferente do Search-Based puro, que apenas retorna os documentos encontrados, o RAG processa esses dados com um LLM para formular uma resposta mais elaborada e natural.
O que são Bancos Vetoriais?
Os bancos de dados vetoriais são sistemas especializados em armazenar e recuperar embeddings de forma eficiente. Diferente de bancos relacionais (como MySQL), que armazenam dados em tabelas, os bancos vetoriais armazenam vetores gerados a partir de embeddings em um espaço multidimensional, permitindo buscas por similaridade sem a necessidade de correspondência exata entre palavras ou frases. Isso os torna essenciais para aplicações de inteligência artificial que precisam encontrar informações relevantes com base no significado e não apenas em palavras específicas.
Por que são importantes no RAG?
- Permitem busca semântica, retornando textos relevantes mesmo que a pergunta seja feita com palavras diferentes.
- São altamente escaláveis, podendo armazenar milhões de embeddings sem perder eficiência.
- Utilizam métodos avançados de indexação, como HNSW (Hierarchical Navigable Small World), para tornar as buscas mais rápidas.
Bancos de Dados Vetoriais Nativos
- FAISS – Desenvolvido pelo Facebook, é um dos mais usados para busca vetorial aproximada em larga escala.
- Milvus – Open-source, distribuído e altamente escalável, ideal para aplicações de IA.
- Pinecone – Plataforma gerenciada que simplifica busca vetorial em tempo real.
- Weaviate – Banco vetorial open-source com GraphQL, usado em IA e NLP.
- Qdrant – Alternativa robusta, com bom suporte a filtros e alto desempenho.
Bancos de Dados Tradicionais com Suporte a Vetores
- PostgreSQL (pgvector) – Uma das opções mais populares, permitindo busca vetorial dentro do SQL.
- Redis (RedisSearch + HNSW) – Oferece busca vetorial eficiente dentro de um banco in-memory.
- Elasticsearch (dense_vector) – Suporte a vetores dentro de um motor de busca altamente escalável.
- MongoDB (Atlas Vector Search) – Busca vetorial integrada ao MongoDB Atlas, facilitando o uso com dados não estruturados.
- ClickHouse (distance functions) – Banco analítico que permite armazenar e buscar vetores rapidamente.
Fonte: https://blog.det.life/why-you-shouldnt-invest-in-vector-databases-c0cd3f59d23c
O que são Embeddings?
Os embeddings são representações numéricas de textos que permitem que um sistema compreenda o significado das frases sem depender exclusivamente das palavras exatas. Eles convertem textos em vetores dentro de um espaço matemático, onde expressões com significados semelhantes ficam mais próximas umas das outras.
Essa técnica de Processamento de Linguagem Natural (PLN) transforma textos em representações vetoriais, posicionando palavras e frases em um espaço multidimensional. Assim, quando um usuário faz uma pergunta, o sistema busca no modelo vetorial os textos mais próximos, identificando similaridades e recuperando a informação mais relevante para gerar uma resposta precisa.
Exemplo de Embeddings na prática
- As frases "Como faço para redefinir minha senha?" e "Esqueci minha senha, como recuperar?" podem ter palavras diferentes, mas seus embeddings serão próximos, pois têm o mesmo significado.
- Com isso, o chatbot pode recuperar a resposta correta mesmo que a pergunta não tenha sido feita com as palavras exatas.
Gráfico com representação vetorial de palavras em um espaço tridimensional
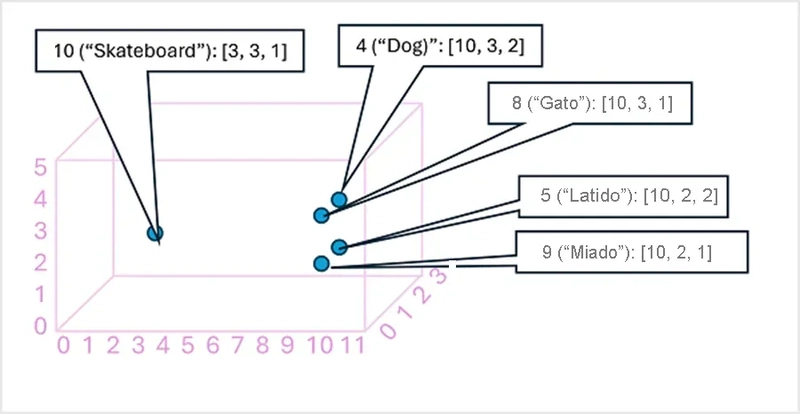
Fonte: Microsoft Certified: Azure AI Fundamental
O gráfico ilustra como os embeddings representam palavras como pontos em um espaço multidimensional, onde termos semanticamente similares estão mais próximos uns dos outros. No exemplo, palavras relacionadas a cães e gatos, como "Dog", "Gato", "Latido" e "Miado", aparecem agrupadas, enquanto "Skateboard", um termo não relacionado, está mais distante. Essa organização é essencial para sistemas que utilizam bancos vetoriais, que armazenam e indexam esses vetores para permitir buscas eficientes. Em um banco vetorial, ao buscar por "cachorro", o sistema pode encontrar automaticamente palavras próximas, como "latido" e "gato", sem precisar de uma correspondência exata, tornando a recuperação de informações mais inteligente e contextualizada.
Vantagens:
- Fácil de atualizar sem precisar re-treinar o modelo.
- Permite respostas contextualizadas e embasadas em documentos reais.
Desvantagens:
- Depende da qualidade da indexação dos dados.
- Pode aumentar o tempo de resposta devido ao processo de busca.
Exemplo de uso:
- Um chatbot corporativo que consulta documentos internos para responder dúvidas de funcionários.
| Método | Memória Interna? | Curto Prazo | Longo Prazo | Atualização Fácil? | Melhor Para... |
|---|---|---|---|---|---|
| Fine-Tuning | ✅ Sim | ❌ | ✅ | ❌ Não (requer re-treino) | Dados estáveis e linguagem específica |
| RAG | ✅ Parcialmente | ✅ | ✅ | ✅ Sim (busca sempre os dados mais recentes) | Respostas baseadas em conhecimento dinâmico |
Se você precisa de um chatbot que se lembre de informações novas e possa ser atualizado sem re-treinamento, RAG é a melhor escolha.