![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)
















































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)




































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)








































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

























































































![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)









![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)































































































































Evita la trampa del Scheduling en Kubernetes: Por qué todos tus Pods pueden caer juntos (y cómo evitarlo)
“Estamos en Kubernetes, así que ya somos resilientes.” Famosas últimas palabras... hasta que una zona de disponibilidad falla y todos tus pods desaparecen con ella. Muchos creen que mover su aplicación a Kubernetes les otorga automáticamente alta disponibilidad. Pero la verdad es que, sin configuración explícita, Kubernetes simplemente hace lo que le conviene: programar pods donde haya espacio. No entiende de resiliencia, ni de zonas de disponibilidad, ni de recuperación ante desastres. Y eso, en producción, puede costarte muy caro. ⚠️ Nota: Aunque el scheduler de Kubernetes es potente, si no lo configuras correctamente, priorizará eficiencia (bin-packing) por encima de la resiliencia. El Problema: Kubernetes no sabe qué significa “Resiliencia” Si desplegamos nuestra aplicación con 5 réplicas en un clúster distribuido en tres zonas de disponibilidad, puede que pensemos "estoy a salvo, si una AZ cae, mi aplicación sigue funcionando". Pero no configuraste ninguna regla de distribución...y Kubernetes, haciendo lo suyo, pone todas las réplicas en la misma AZ. Si ese nodo o zona falla, tu servicio cae por completo. ¿Por qué ocurre esto? Porque el scheduler de Kubernetes no tiene en cuenta la disponibilidad geográfica ni resiliencia a fallos...a no ser que se lo digamos nosotros. ⚠️ Nota: Por defecto, Kubernetes: Busca nodos con recursos disponibles (CPU, memoria) Programa los pods donde haya espacio No entiende de zonas de disponibilidad, racks o dominios de fallo Herramientas de Scheduling para evitarlo Vamos a repasar las principales herramientas que Kubernetes te ofrece para controlar dónde se programan tus pods. Lo interesante es que ya están ahí — solo tienes que usarlas. 1. nodeSelector – Simple, pero limitado Permite que un pod se ejecute solo en nodos con una etiqueta específica. nodeSelector: disktype: ssd Esto es útil si quieres asegurarte de que ciertos workloads vayan a nodos con características particulares. Pero… no hay lógica de fallback. Si no encuentra ese nodo, no se programa. Y si solo hay un nodo con esa etiqueta, tus pods van todos al mismo lugar. Ejemplo práctico: Tienes una app de machine learning que necesita discos SSD para procesar datos. Usas nodeSelector para asegurarte de que los pods de esta app solo se desplieguen en nodos con discos SSD. apiVersion: v1 kind: Pod metadata: name: ml-app spec: nodeSelector: disktype: ssd containers: - name: ml-container image: ml-image Los pods solo se programan en nodos etiquetados con disktype=ssd. Si no hay nodos con esa etiqueta, el Pod queda pendiente. 2. nodeAffinity – Más Inteligente Aquí ya podemos hablar de condiciones más expresivas, como por ejemplo "quiero nodos en eu-south-1a", pero si no hay disponibles, programa en cualquier otro nodo válido (por ejemplo 1b, 1c)" affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 preference: matchExpressions: - key: topology.kubernetes.io/zone operator: In values: - eu-south-1a Nota: Le hemos asignado una prioridad alta (de 1 a 100) a esta preferencia. Si tienes múltiples reglas preferred, Kubernetes suma los pesos para decidir el mejor nodo. key: topology.kubernetes.io/zone: Usamos la etiqueta estándar de Kubernetes para zonas de disponibilidad, asegurando compatibilidad con clústeres bien configurados. Valores (eu-south-1a): Priorizamos una sola zona, pero la naturaleza de preferred nos da flexibilidad. Ejemplo práctico: Tienes una aplicación web que sirve a usuarios en Europa. Quieres que los pods se desplieguen preferentemente en eu-south-1a para menor latencia, pero si esa zona está llena o no disponible, estás dispuesto a usar eu-south-1b o eu-south-1c. apiVersion: v1 kind: Pod metadata: name: web-app spec: affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 preference: matchExpressions: - key: topology.kubernetes.io/zone operator: In values: - eu-south-1a containers: - name: web-container image: nginx Cuándo usarlo: Usa preferredDuringSchedulingIgnoredDuringExecution cuando quieras optimizar la ubicación de los pods (por ejemplo, para latencia o costes), pero no quieres sacrificar la capacidad de programarlos si las condiciones ideales no se cumplen. Ejemplo: Aplicaciones que se benefician de estar en una zona específica, pero pueden funcionar correctamente en otras. Por otro lado, tienes la opción de usar requiredDuringSchedulingIgnoredDuringExecution pero te encontrarás que fuerza a los pods que cumplan las condiciones especificadas (por ejemplo, zone=eu-south-1a). Es mucho más restrictivo porque si no hay nodos disponibles, los pods quedan pendientes. 3. podAntiAffinity – ¡No Juntes Todos los Pods! Este es el paracaídas que muc
“Estamos en Kubernetes, así que ya somos resilientes.”
Famosas últimas palabras... hasta que una zona de disponibilidad falla y todos tus pods desaparecen con ella.
Muchos creen que mover su aplicación a Kubernetes les otorga automáticamente alta disponibilidad. Pero la verdad es que, sin configuración explícita, Kubernetes simplemente hace lo que le conviene: programar pods donde haya espacio. No entiende de resiliencia, ni de zonas de disponibilidad, ni de recuperación ante desastres.
Y eso, en producción, puede costarte muy caro.
⚠️ Nota: Aunque el scheduler de Kubernetes es potente, si no lo configuras correctamente, priorizará eficiencia (bin-packing) por encima de la resiliencia.
El Problema: Kubernetes no sabe qué significa “Resiliencia”
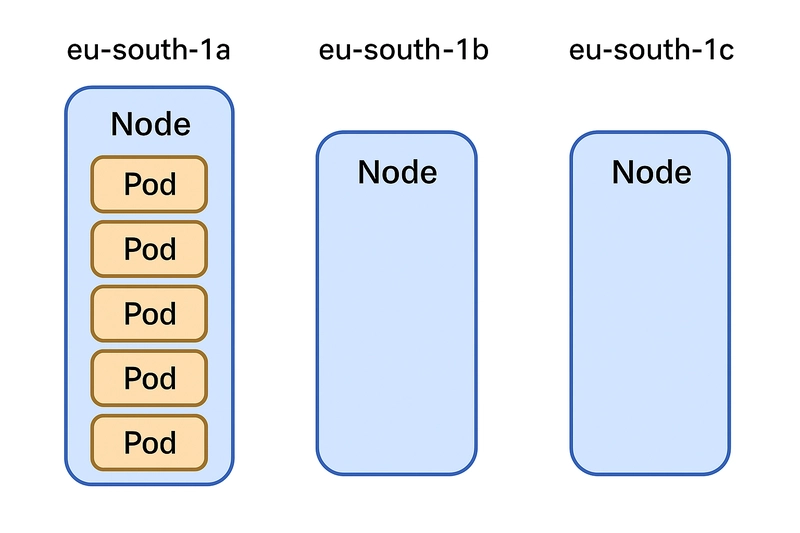
Si desplegamos nuestra aplicación con 5 réplicas en un clúster distribuido en tres zonas de disponibilidad, puede que pensemos "estoy a salvo, si una AZ cae, mi aplicación sigue funcionando".
Pero no configuraste ninguna regla de distribución...y Kubernetes, haciendo lo suyo, pone todas las réplicas en la misma AZ. Si ese nodo o zona falla, tu servicio cae por completo.
¿Por qué ocurre esto? Porque el scheduler de Kubernetes no tiene en cuenta la disponibilidad geográfica ni resiliencia a fallos...a no ser que se lo digamos nosotros.
⚠️ Nota: Por defecto, Kubernetes:
- Busca nodos con recursos disponibles (CPU, memoria)
- Programa los pods donde haya espacio
- No entiende de zonas de disponibilidad, racks o dominios de fallo
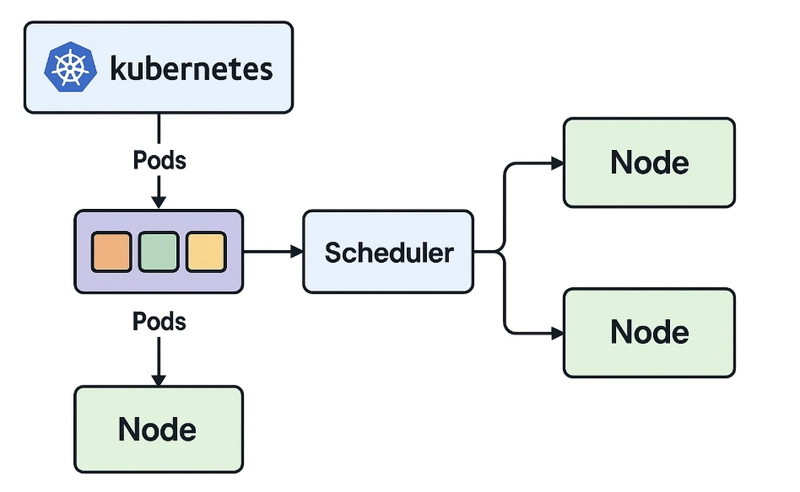
Herramientas de Scheduling para evitarlo
Vamos a repasar las principales herramientas que Kubernetes te ofrece para controlar dónde se programan tus pods. Lo interesante es que ya están ahí — solo tienes que usarlas.
1. nodeSelector – Simple, pero limitado
Permite que un pod se ejecute solo en nodos con una etiqueta específica.
nodeSelector:
disktype: ssd
Esto es útil si quieres asegurarte de que ciertos workloads vayan a nodos con características particulares.
Pero… no hay lógica de fallback. Si no encuentra ese nodo, no se programa.
Y si solo hay un nodo con esa etiqueta, tus pods van todos al mismo lugar.
Ejemplo práctico: Tienes una app de machine learning que necesita discos SSD para procesar datos. Usas nodeSelector para asegurarte de que los pods de esta app solo se desplieguen en nodos con discos SSD.
apiVersion: v1
kind: Pod
metadata:
name: ml-app
spec:
nodeSelector:
disktype: ssd
containers:
- name: ml-container
image: ml-image
Los pods solo se programan en nodos etiquetados con disktype=ssd. Si no hay nodos con esa etiqueta, el Pod queda pendiente.
2. nodeAffinity – Más Inteligente
Aquí ya podemos hablar de condiciones más expresivas, como por ejemplo "quiero nodos en eu-south-1a", pero si no hay disponibles, programa en cualquier otro nodo válido (por ejemplo 1b, 1c)"
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
preference:
matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- eu-south-1a
Nota:
- Le hemos asignado una prioridad alta (de 1 a 100) a esta preferencia. Si tienes múltiples reglas
preferred, Kubernetes suma los pesos para decidir el mejor nodo. -
key: topology.kubernetes.io/zone: Usamos la etiqueta estándar de Kubernetes para zonas de disponibilidad, asegurando compatibilidad con clústeres bien configurados. - Valores (eu-south-1a): Priorizamos una sola zona, pero la naturaleza de preferred nos da flexibilidad.
Ejemplo práctico: Tienes una aplicación web que sirve a usuarios en Europa. Quieres que los pods se desplieguen preferentemente en eu-south-1a para menor latencia, pero si esa zona está llena o no disponible, estás dispuesto a usar eu-south-1b o eu-south-1c.
apiVersion: v1
kind: Pod
metadata:
name: web-app
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
preference:
matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- eu-south-1a
containers:
- name: web-container
image: nginx
Cuándo usarlo:
- Usa
preferredDuringSchedulingIgnoredDuringExecutioncuando quieras optimizar la ubicación de los pods (por ejemplo, para latencia o costes), pero no quieres sacrificar la capacidad de programarlos si las condiciones ideales no se cumplen. - Ejemplo: Aplicaciones que se benefician de estar en una zona específica, pero pueden funcionar correctamente en otras.
Por otro lado, tienes la opción de usar requiredDuringSchedulingIgnoredDuringExecution pero te encontrarás que fuerza a los pods que cumplan las condiciones especificadas (por ejemplo, zone=eu-south-1a). Es mucho más restrictivo porque si no hay nodos disponibles, los pods quedan pendientes.
3. podAntiAffinity – ¡No Juntes Todos los Pods!
Este es el paracaídas que muchos olvidan abrir. Evita que múltiples réplicas de la misma app caigan en el mismo nodo:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: mi-app
topologyKey: kubernetes.io/hostname
Esto dice: “No pongas mis pods con el mismo label en el mismo nodo.”
Ideal para evitar que un único fallo te deje sin servicio.
Cuándo usarlo: Cuando quieres garantizar que las réplicas de tu app no estén en el mismo nodo o zona, para que un fallo no derribe todo.
⚠️ Cuidado: si no hay suficientes nodos disponibles, Kubernetes no programará los pods. Así que úsalo con cabeza y monitoriza bien tu infraestructura.
Ejemplo práctico: Una API crítica con 3 réplicas. Quieres que cada réplica esté en una zona diferente para sobrevivir a fallos de una zona.
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-app
spec:
replicas: 3
selector:
matchLabels:
app: api
template:
metadata:
labels:
app: api
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: api
topologyKey: topology.kubernetes.io/zone
containers:
- name: api-container
image: api-image
En nuestro ejemplo cada réplica se programa en una zona distinta (eu-south-1a, 1b, 1c) y además forzamos a que sea así (a diferencia del ejemplo anterior donde utilizamos preferredDuringSchedulingIgnoredDuringExecution. Si no hay suficientes zonas, el pod simplemente no se programa.
4. taints y tolerations – Para reservar nodos especiales
A veces no se trata de distribuir, sino de aislar. Con taints puedes impedir que pods se programen en ciertos nodos a menos que los toleren explícitamente.
kubectl taint nodes nodo-gpu dedicated=gpu:NoSchedule
Y luego en el pod:
tolerations:
- key: "dedicated"
operator: "Equal"
value: "gpu"
effect: "NoSchedule"
Esto es perfecto para:
- Reservar nodos GPU
- Separar entornos (producción vs. desarrollo)
- Cargas críticas o de alto aislamiento
Cuándo usarlo: Cuando quieres reservar nodos para cargas específicas, como entornos de producción o hardware especializado.
Ejemplo práctico: Tienes nodos con GPUs (que nos cuestan un ojo de la cara) que solo deberían usar pods de una app de renderizado 3D.
apiVersion: v1
kind: Pod
metadata:
name: render-app
spec:
tolerations:
- key: "dedicated"
operator: "Equal"
value: "gpu"
effect: "NoSchedule"
containers:
- name: render-container
image: render-image
Únicamente los pods con la tolerancia adecuada pueden ejecutarse en el nodo con el taint; los demás son automáticamente excluidos.
5. TopologySpreadConstraints (TSC)
Si quieres que tus pods se distribuyan de manera uniforme entre zonas, nodos o racks, TopologySpreadConstraints es tu mejor amigo. A diferencia de podAntiAffinity, que solo evita que los pods estén juntos, TSC asegura que se repartan equitativamente, minimizando el riesgo de que un fallo afecte a todas tus réplicas.
¿Cuándo usarlo?
- Cuando tienes muchas réplicas y quieres que se distribuyan automáticamente entre zonas o nodos.
- Cuando necesitas tolerancia a fallos sin configurar reglas rígidas como en podAntiAffinity.
Ejemplo práctico: Tienes una app de comercio electrónico con 6 réplicas que debe estar distribuida en tres zonas (eu-south-1a, 1b, 1c). Quieres que cada zona tenga aproximadamente 2 Pods para balancear la carga y sobrevivir a fallos.
apiVersion: apps/v1
kind: Deployment
metadata:
name: ecommerce-app
spec:
replicas: 6
selector:
matchLabels:
app: ecommerce
template:
metadata:
labels:
app: ecommerce
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: ecommerce
containers:
- name: ecommerce-container
image: ecommerce-image
¿Qué significa esto?
-
maxSkew: 1: La diferencia máxima de Pods entre cualquier par de zonas será de 1 (por ejemplo, 2 pods en una zona, 2 en otra, 2 en otra). -
topologyKey: topology.kubernetes.io/zone: Los pods se distribuyen según las zonas de disponibilidad. -
whenUnsatisfiable: DoNotSchedule: Si no se puede cumplir la restricción (por ejemplo, no hay suficientes zonas), los pods no se programan. -
labelSelector: Aplica la restricción solo a los pods con la etiqueta app: ecommerce.
Ventajas:
- Distribución automática y equilibrada.
- Más flexible que podAntiAffinity, ya que permite pequeños desequilibrios controlados.
- Ideal para clústeres grandes con muchas réplicas.
⚠️ Cuidado:
Asegúrate de que tus nodos estén bien etiquetados con topology.kubernetes.io/zone.
Si el clúster es pequeño, puede ser difícil cumplir con las restricciones.
6. Topology Aware Routing (TAR) – Un vistazo al Futuro
Mientras que TopologySpreadConstraints se centra en distribuir pods, TAR optimiza el tráfico entre ellos, asegurando que las comunicaciones sean lo más locales posible (por ejemplo, dentro de la misma zona).
⚠️ Nota: Aunque es prometedor, TAR aún está en fase experimental y depende de EndpointSlices y kube-proxy. Por ahora, TSC es la opción más estable y práctica para la mayoría de los casos.
Con TAR podemos dispersar pods entre nodos, zonas de disponibilidad (AZ), racks o dominios personalizados optimizando el tráfico de red para que permanezca en la misma zona donde se origina.
# Habilita TAR mediante una anotación en el Servicio
apiVersion: v1
kind: Service
metadata:
name: mi-servicio
annotations:
service.kubernetes.io/topology-mode: "Auto"
spec:
selector:
app: mi-app
ports:
- protocol: TCP
port: 80
targetPort: 8080
Características:
- Usa pistas en EndpointSlices para preferir puntos finales locales, ajustando dinámicamente el enrutamiento del tráfico
TAR nos va a optimizar cómo se envía el tráfico de red dentro de un clúster de Kubernetes. Normalmente, cuando un pod en una zona (como "zona A") intenta comunicarse con un servicio, Kubernetes podría enviar ese tráfico a cualquier pod que respalde ese servicio, incluso si está en otra zona (como "zona B"), lo que aumenta la latencia y los costos entre zonas. TAR cambia esto al usar "pistas" (o hints) que se almacenan en objetos llamados EndpointSlices.
Los EndpointSlices son como una lista dinámica que Kubernetes mantiene para rastrear qué pods están disponibles para recibir tráfico para un servicio específico (por ejemplo, todos los pods con la etiqueta app: mi-app). Estas pistas le dicen al sistema: "Si el tráfico viene de la zona A, intenta enviarlo primero a los pods que también están en la zona A". Esto se llama "preferir puntos finales locales", porque TAR prioriza los pods más cercanos en términos de topología (como la misma zona de disponibilidad).
Hablamos de "ajuste dinámico" ya que no se trata de una regla fija. En lugar de depender de configuraciones estáticas, TAR observa constantemente las condiciones del clúster (como cuántos pods hay en cada zona) y adapta el enrutamiento del tráfico en tiempo real a través de kube-proxy, el componente que maneja la red en Kubernetes. Esto asegura que el tráfico se mantenga eficiente y local siempre que sea posible, reduciendo retrasos y costos.
- Se desactiva automáticamente si las zonas se desequilibran (por ejemplo, pocos puntos finales disponibles) y se reactiva cuando el balance se restaura, sin necesidad de configuraciones manuales complejas
Además TAR está diseñado para evitar problemas cuando el clúster no está en un estado ideal. Imagina que tienes un servicio con pods distribuidos en tres zonas: A, B y C. Si por alguna razón (como un fallo o un escalado automático) la zona C se queda sin pods (es decir, "pocos puntos finales disponibles"), el clúster se desequilibra porque no hay una distribución uniforme de pods entre las zonas.
En este caso, TAR detecta que mantener el tráfico "local" en la zona C no tiene sentido, porque no hay pods para recibirlo. Entonces, en lugar de forzar una configuración inválida, TAR se "desactiva" automáticamente para esa zona y permite que el tráfico se enrute a pods en otras zonas (como A o B), usando el comportamiento predeterminado de Kubernetes (enrutamiento global). Esto es una medida de protección para garantizar que el servicio siga funcionando, incluso si las condiciones no son perfectas.
Cuando las cosas vuelven a la normalidad —por ejemplo, si nuevos pods se despliegan en la zona C y el balance entre zonas se restaura— TAR se "reactiva" automáticamente y vuelve a preferir puntos finales locales en cada zona. Lo mejor de esto es que no necesitas ajustar manualmente reglas complicadas ni escribir configuraciones adicionales para manejar estos cambios; TAR lo hace todo por ti en segundo plano, basándose en las pistas de los EndpointSlices y las condiciones actuales del clúster.
Autoscaling en Kubernetes: Pods vs. Nodos
Para que tu clúster sea realmente resiliente, no solo necesitas distribuir bien los pods, sino también escalar dinámicamente según la demanda. En Kubernetes, hay dos tipos de autoscaling:
-
Autoscaling de Pods:
- Herramientas como Horizontal Pod Autoscaler (HPA), Vertical Pod Autoscaler (VPA) o KEDA ajustan el número o los recursos de los pods según métricas como CPU, memoria o eventos externos.
- Ejemplo: Si tu app recibe más tráfico, HPA crea más réplicas automáticamente.
- Cuándo usarlo: Cuando la carga de trabajo varía y necesitas más pods para manejar el tráfico.
-
Autoscaling de Nodos:
- Herramientas como Cluster Autoscaler o Karpenter añaden o eliminan nodos según la demanda de pods.
- Ejemplo: Si no hay suficientes nodos para programar nuevos pods, Karpenter crea nodos nuevos en la zona adecuada.
- Cuándo usarlo: Cuando el clúster necesita crecer o reducirse para soportar los pods.
¿Y si quiero automatizar la creación de nodos?
Si bien todas las herramientas anteriores son excelentes, tienen un límite: sigues dependiendo de los nodos existentes.
¿Qué pasa si no hay nodos disponibles? Ahí entra Karpenter, el autoscaler inteligente de Kubernetes, que no solo escala nodos, sino que respeta tus reglas de distribución.
Karpenter te ayuda a:
- Crear nodos en tiempo real según la demanda
- Respeta topologySpreadConstraints y todos los constraints que hemos visto en este artículo
- Evita que los nodos sobreprovisionados acaparen todos los pods
- Compatible con Spot y Graviton para mayor eficiencia y ahorro
- Funciona a través de múltiples AZs sin necesidad de grupos de nodos fijos
Un ejemplo: Este es un nodepool que:
- Distribuye los Pods entre múltiples AZs
- Usa instancias Spot con fallback a bajo coste
- Limita a instancias basadas en Graviton (arm64)
- Respeta topologySpreadConstraints definidos en los Pods
- Asocia etiquetas específicas para afinidad con workloads
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: topology.kubernetes.io/zone
operator: In
values: ["eu-south-1a", "eu-south-1b", "eu-south-1c"]
- key: kubernetes.io/arch
operator: In
values: ["arm64"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]
labels:
workload: critical # Etiqueta para afinidad con workloads
nodeClassRef:
name: default
limits:
cpu: 1000
disruption:
consolidationPolicy: WhenUnderutilized
expireAfter: 720h # 30 días
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2023
role: "KarpenterNodeRole-my-cluster"
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "my-cluster"
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "my-cluster"
¿Qué significa esto?
-
NodePool:-
requirements: Solo crea nodos en las zonas eu-south-1a, 1b, 1c, con arquitectura ARM64 (Graviton) y prefiere instancias Spot, pero permite On-Demand como respaldo. -
limits: Máximo 1000 CPUs en total. -
disruption: Consolida nodos subutilizados y elimina nodos vacíos tras 30 días.
-
-
EC2NodeClass:- Usa Amazon Linux 2023 como AMI.
- Aplica el rol IAM y selecciona subnets/security groups con la etiqueta
karpenter.sh/discovery: my-cluster.
Como ves, Karpenter aporta funcionalidades avanzadas que complementan las herramientas nativas de Kubernetes (trabaja en tándem con el Kube scheduler).
Ejemplo práctico: Tienes una app con TopologySpreadConstraints que necesita 10 Pods distribuidos en 3 zonas. Si no hay suficientes nodos, Karpenter crea nuevos nodos en las zonas especificadas, respetando tus reglas de TSC y usando instancias Spot baratas siempre que sea posible.
# Parte 1: Deployment con TopologySpreadConstraints
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 10 #crea 10 pods
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
topologySpreadConstraints:
- maxSkew: 1 #diferencia de pods entre cualquier par de zonas sea como máximo 1
topologyKey: topology.kubernetes.io/zone #Distribuye pods según las zonas de disponibilidad.
whenUnsatisfiable: DoNotSchedule #Si no se puede cumplir la restricción (ej, no hay nodos en una zona), los pods no se programan.
labelSelector:
matchLabels:
app: my-app #Aplica la restricción a los pods con esta etiqueta
containers:
- name: app-container
image: nginx
resources:
requests:
cpu: "100m"
memory: "128Mi"
---
# Parte 2: NodePool de Karpenter
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: topology.kubernetes.io/zone #Permite nodos en las 3x AZs
operator: In
values: ["eu-south-1a", "eu-south-1b", "eu-south-1c"]
- key: kubernetes.io/arch #Limita a instancias Graviton.
operator: In
values: ["arm64"]
- key: karpenter.sh/capacity-type #Prioriza Spot, con On-Demand como respaldo.
operator: In
values: ["spot", "on-demand"]
labels:
workload: critical #Opcional: Añade una etiqueta para afinidad
nodeClassRef:
name: default
limits:
cpu: 1000 #Limita el total de CPUs para evitar sobreprovisionamiento.
disruption: #Consolida nodos subutilizados y elimina nodos vacíos tras 30 días.
consolidationPolicy: WhenUnderutilized
expireAfter: 720h # 30 días
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass #Define la configuración de AWS (AMI, rol IAM, subnets, security groups).
metadata:
name: default
spec:
amiFamily: AL2023
role: "KarpenterNodeRole-my-cluster"
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "my-cluster"
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "my-cluster"
- Si faltan nodos en alguna zona para cumplir con
topologySpreadConstraints(por ejemplo, no hay suficientes nodos eneu-south-1b), Karpenter crea nuevos nodos en esa zona. - Prefiere instancias Spot para minimizar costes, pero usa On-Demand si Spot no está disponible.
- Los nodos creados son compatibles con las zonas requeridas, asegurando que el scheduler de Kubernetes pueda distribuir los pods correctamente.
Ventajas:
- Escala nodos automáticamente según las necesidades de los Pods.
- Respeta restricciones como zonas y tipos de instancia.
- Optimiza costes con Spot y Graviton.
Tabla resumen – Herramientas de scheduling en Kubernetes
| Herramienta | Ventajas | Limitaciones | Caso de Uso |
|---|---|---|---|
| nodeSelector | Muy fácil de usar, ideal para nodos específicos | Sin fallback, riesgo de colocation | App que necesita discos SSD para alto rendimiento |
| nodeAffinity | Condiciones complejas, permite reglas suaves (preferred) | No garantiza distribución, requiere etiquetas correctas | App que prefiere una zona para menor latencia pero acepta otras |
| podAntiAffinity | Evita colocation de réplicas, mejora resiliencia | Puede dejar pods sin programar si faltan nodos | API crítica que debe sobrevivir fallos de una zona |
| taints & tolerations | Aísla cargas específicas, ideal para hardware especial | No influye en distribución, puede dejar nodos vacíos | Nodos GPU reservados para apps de machine learning |
| TopologySpreadConstraints | Distribución equilibrada, flexible con desequilibrios | Requiere etiquetas correctas, complejo en clústeres pequeños | App con muchas réplicas que debe balancearse entre zonas |
| Topology Aware Routing | Optimiza tráfico localmente, adapta dinámicamente | Experimental, depende de EndpointSlices, menos control sobre pods | Servicios críticos que necesitan mínima latencia entre zonas |
| Karpenter | Escala nodos dinámicamente, respeta restricciones, soporta Spot/Graviton | Requiere configuración IAM, más complejo inicialmente | Clúster que crece/reduce según demanda, respetando distribución de pods |
Checklist: Mi clúster resiliente
Conociendo las herramientas y qué ventajas tienen, podríamos tener una checklist para verificar si nuestro clúster está preparado para soportar caídas sin comprometer la disponibilidad.
Para ello, asegúrate de validar tu configuración:
- [ ] Habilitar TopologySpreadConstraints para distribuir pods equitativamente entre zonas.
- [ ] Aplicar podAntiAffinity para evitar colapsos
- [ ] Etiqueta bien tus nodos (zone, rack, tipo, etc.)
- [ ] Configuraste nodos con taints y tolerations para aislar cargas
- [ ] Tienes Karpenter desplegado y activo
- [ ] Has hecho simulaciones de fallos con herramientas como Chaos Mesh o Fault Injection Service
Seguro que se te ocurre alguna otra validación. Si es así, déjanosla en los comentarios.
Conclusión
Kubernetes no te da resiliencia automáticamente. Si no guías al scheduler, pondrá todo donde sea más cómodo — y eso puede ser un quebradero de cabeza.
Pero con un buen uso de las herramientas que hemos visto y con Karpenter para reforzar el autoscaling, puedes tomar el control del scheduling y construir un clúster robusto que resista fallos de nodos o zonas. Configura estas opciones con cuidado, prueba tu entorno y usa el autoscaling inteligente de Karpenter para garantizar que tu aplicación siga funcionando sin interrupciones, sin importar lo que pase.
Nos vemos en el siguiente!