











































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)








































































































.png?#)





.jpg?#)































_Christophe_Coat_Alamy.jpg?#)


































































































![Rapidus in Talks With Apple as It Accelerates Toward 2nm Chip Production [Report]](https://www.iclarified.com/images/news/96937/96937/96937-640.jpg)

































































































































DuckDB
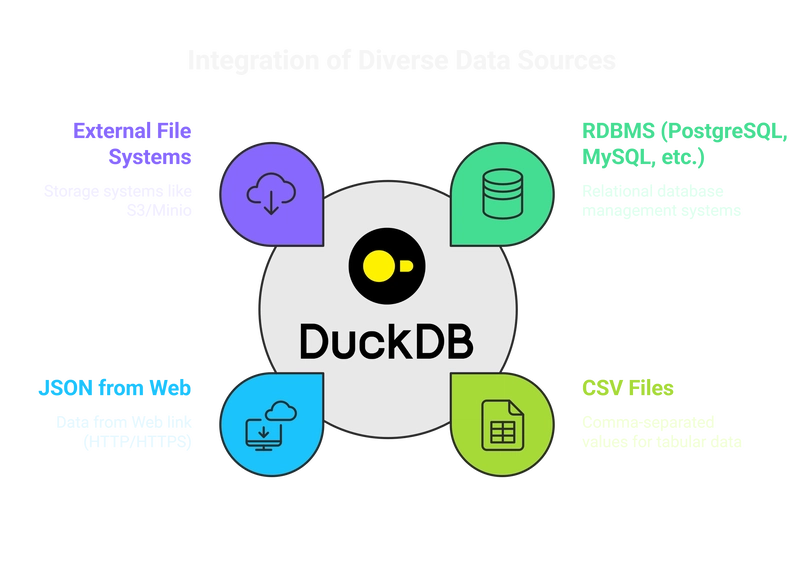
Introduction DuckDB est largement reconnu pour ses capacités de traitement analytique, mais sa véritable puissance réside dans son moteur de requête exceptionnel. Contrairement aux bases de données traditionnelles qui nécessitent une configuration et des processus ETL complexes, DuckDB permet aux utilisateurs d'interroger des données provenant de diverses sources de manière fluide. Cet article explore le moteur de requête de DuckDB, ses avantages et propose un guide pratique pour l'utiliser efficacement. Qu'est-ce qui fait du moteur de requête de DuckDB un outil révolutionnaire ? Contrairement à de nombreuses bases de données qui nécessitent l'importation de données avant l'interrogation, le moteur de requête de DuckDB est conçu pour fonctionner directement sur plusieurs formats de fichiers et bases de données externes . Voici ce qui le distingue : Caractéristiques principales Prend en charge plusieurs formats de fichiers : Faites des requête sur des fichiers CSV, Parquet, JSON et plus sans conversion manuelle. Fonctionne avec les bases de données relationnelles : se connecte de manière transparente à PostgreSQL, MySQL et autres. Lire les formats de données ouverts : prend en charge Iceberg et Delta Lake. Interface SQL simple : aucune configuration complexe requise. Compatibilité multi-language : fonctionne avec Python, R, Java, Node.js, Rust, etc. Pris en charge par les outils de visualisation : Pris en charge comme source de données par les outils de visualisation tels qu'Apache-Superset, metabase, les outils basés sur JDBC (Tableau,...), etc. Optimisations avancées dans DuckDB DuckDB est un système de gestion de base de données (SGBD) relationnel (orienté table) prenant en charge le langage SQL (Structured Query Language) . Il est conçu pour répondre au besoin d'un système de base de données offrant un ensemble unique de compromis, notamment pour les cas d'utilisation analytiques. Ses principales caractéristiques sont sa simplicité et son fonctionnement intégré , inspiré de SQLite. Il ne nécessite aucune dépendance externe pour la compilation ou l'exécution et est compilé dans un fichier d'en-tête et d'implémentation unique (une « fusion »), simplifiant ainsi le déploiement. Contrairement aux bases de données client-serveur traditionnelles, DuckDB s'exécute entièrement intégré à un processus hôte , éliminant ainsi le besoin d'installation et de maintenance d'un logiciel serveur distinct. Cette intégration permet un transfert de données à haut débit et la possibilité de traiter des données externes, telles que les Pandas DataFrames en Python, sans copie. Conçu pour exceller dans les charges de travail de requêtes analytiques (OLAP) caractérisées par des requêtes complexes et longues sur de grands ensembles de données, DuckDB utilise un moteur d'exécution de requêtes vectorisé en colonnes . Cette approche traite les données par lots (« vecteurs »), réduisant considérablement la charge par rapport aux systèmes traditionnels basés sur les lignes comme PostgreSQL, MySQL ou SQLite. DuckDB est également extensible , permettant aux utilisateurs de définir de nouveaux types de données, fonctions, formats de fichiers et syntaxe SQL grâce à un mécanisme d'extension. Notamment, la prise en charge de formats courants comme Parquet et JSON, ainsi que de protocoles comme HTTP(S) et s3, est implémentée sous forme d'extensions. DuckDB est extrêmement portable , capable d'être compilé pour tous les principaux systèmes d'exploitation (Linux, macOS, Windows) et architectures CPU (x86, ARM), et peut même fonctionner dans les navigateurs web et sur les téléphones portables via DuckDB-Wasm. Il fournit des API pour divers langages de programmation, dont Java, C, C++, Go et Python. Malgré sa simplicité, DuckDB est riche en fonctionnalités , offrant une prise en charge étendue des requêtes SQL complexes, une vaste bibliothèque de fonctions, des fonctions de fenêtrage, des garanties transactionnelles (propriétés ACID) , des bases de données monofichier persistantes et des index secondaires. Il est également profondément intégré à Python et R pour une analyse de données interactive et efficace. Pour plus de détails techniques, visitez la documentation officielle de DuckDB . DuckDB vs Apache Spark vs Trino : comparaison rapide Fonctionnalité DuckDB Apache Spark Trino Coûts d'installation Gratuit, léger Configuration du cluster requise Nécessite une configuration distribuée Coûts de fonctionnement Minimal Dépenses courantes du cluster Coûts du cluster ou du cloud Courbe d'apprentissage Connaissances de base en SQL Nécessite un apprentissage plus approfondi Connaissances SQL modérées Performance Rapide pour les requêtes locales S'adapte bien au Big Data Optimisé pour SQL distribué Cas d'utilisation Analyses locales Traitement distribué des données Moteur de requête fédéré DuckDB est idéal pour les requêtes analytiques locales, Spark est meil
Introduction
DuckDB est largement reconnu pour ses capacités de traitement analytique, mais sa véritable puissance réside dans son moteur de requête exceptionnel. Contrairement aux bases de données traditionnelles qui nécessitent une configuration et des processus ETL complexes, DuckDB permet aux utilisateurs d'interroger des données provenant de diverses sources de manière fluide. Cet article explore le moteur de requête de DuckDB, ses avantages et propose un guide pratique pour l'utiliser efficacement.
Qu'est-ce qui fait du moteur de requête de DuckDB un outil révolutionnaire ?
Contrairement à de nombreuses bases de données qui nécessitent l'importation de données avant l'interrogation, le moteur de requête de DuckDB est conçu pour fonctionner directement sur plusieurs formats de fichiers et bases de données externes . Voici ce qui le distingue :
Caractéristiques principales
- Prend en charge plusieurs formats de fichiers : Faites des requête sur des fichiers CSV, Parquet, JSON et plus sans conversion manuelle.
- Fonctionne avec les bases de données relationnelles : se connecte de manière transparente à PostgreSQL, MySQL et autres.
- Lire les formats de données ouverts : prend en charge Iceberg et Delta Lake.
- Interface SQL simple : aucune configuration complexe requise.
- Compatibilité multi-language : fonctionne avec Python, R, Java, Node.js, Rust, etc.
- Pris en charge par les outils de visualisation : Pris en charge comme source de données par les outils de visualisation tels qu'Apache-Superset, metabase, les outils basés sur JDBC (Tableau,...), etc.
Optimisations avancées dans DuckDB
DuckDB est un système de gestion de base de données (SGBD) relationnel (orienté table) prenant en charge le langage SQL (Structured Query Language) . Il est conçu pour répondre au besoin d'un système de base de données offrant un ensemble unique de compromis, notamment pour les cas d'utilisation analytiques. Ses principales caractéristiques sont sa simplicité et son fonctionnement intégré , inspiré de SQLite. Il ne nécessite aucune dépendance externe pour la compilation ou l'exécution et est compilé dans un fichier d'en-tête et d'implémentation unique (une « fusion »), simplifiant ainsi le déploiement. Contrairement aux bases de données client-serveur traditionnelles, DuckDB s'exécute entièrement intégré à un processus hôte , éliminant ainsi le besoin d'installation et de maintenance d'un logiciel serveur distinct. Cette intégration permet un transfert de données à haut débit et la possibilité de traiter des données externes, telles que les Pandas DataFrames en Python, sans copie.
Conçu pour exceller dans les charges de travail de requêtes analytiques (OLAP) caractérisées par des requêtes complexes et longues sur de grands ensembles de données, DuckDB utilise un moteur d'exécution de requêtes vectorisé en colonnes . Cette approche traite les données par lots (« vecteurs »), réduisant considérablement la charge par rapport aux systèmes traditionnels basés sur les lignes comme PostgreSQL, MySQL ou SQLite. DuckDB est également extensible , permettant aux utilisateurs de définir de nouveaux types de données, fonctions, formats de fichiers et syntaxe SQL grâce à un mécanisme d'extension. Notamment, la prise en charge de formats courants comme Parquet et JSON, ainsi que de protocoles comme HTTP(S) et s3, est implémentée sous forme d'extensions.
DuckDB est extrêmement portable , capable d'être compilé pour tous les principaux systèmes d'exploitation (Linux, macOS, Windows) et architectures CPU (x86, ARM), et peut même fonctionner dans les navigateurs web et sur les téléphones portables via DuckDB-Wasm. Il fournit des API pour divers langages de programmation, dont Java, C, C++, Go et Python. Malgré sa simplicité, DuckDB est riche en fonctionnalités , offrant une prise en charge étendue des requêtes SQL complexes, une vaste bibliothèque de fonctions, des fonctions de fenêtrage, des garanties transactionnelles (propriétés ACID) , des bases de données monofichier persistantes et des index secondaires. Il est également profondément intégré à Python et R pour une analyse de données interactive et efficace.
Pour plus de détails techniques, visitez la documentation officielle de DuckDB .
DuckDB vs Apache Spark vs Trino : comparaison rapide
| Fonctionnalité | DuckDB | Apache Spark | Trino |
|---|---|---|---|
| Coûts d'installation | Gratuit, léger | Configuration du cluster requise | Nécessite une configuration distribuée |
| Coûts de fonctionnement | Minimal | Dépenses courantes du cluster | Coûts du cluster ou du cloud |
| Courbe d'apprentissage | Connaissances de base en SQL | Nécessite un apprentissage plus approfondi | Connaissances SQL modérées |
| Performance | Rapide pour les requêtes locales | S'adapte bien au Big Data | Optimisé pour SQL distribué |
| Cas d'utilisation | Analyses locales | Traitement distribué des données | Moteur de requête fédéré |
DuckDB est idéal pour les requêtes analytiques locales, Spark est meilleur pour le calcul distribué à grande échelle et Trino excelle dans les requêtes fédérées sur plusieurs sources.
Pratique : Libérez DuckDB comme moteur de requête
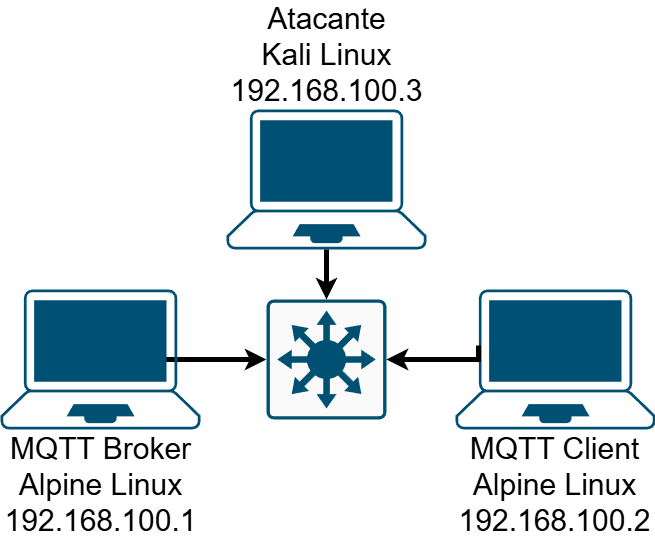
Dans ce tutoriel, nous utiliserons DuckDB pour interroger trois sources de données différentes :
- Base de données PostgreSQL
- Base de données MySQL
- Fichiers CSV
-
JSON à partir d'un serveur Web
1. Configuration de l'environnement
Nous utiliserons Docker Compose pour configurer l'infrastructure. Commencez par cloner le dépôt et démarrer les services :
git clone https://github.com/mikekenneth/bp_duck_as_query_engine
cd bp_duck_as_query_engine
make up # Start services
Vérifiez les conteneurs en cours d'exécution avec :
docker ps

Ensuite, accédez à DuckDB CLI :
make duckdb

Pour faciliter la configuration, j'ai créé un duckdb_init.sql contenant les commandes SQL nécessaires pour se connecter à nos sources de données externes.
2. Connexion aux sources de données externes
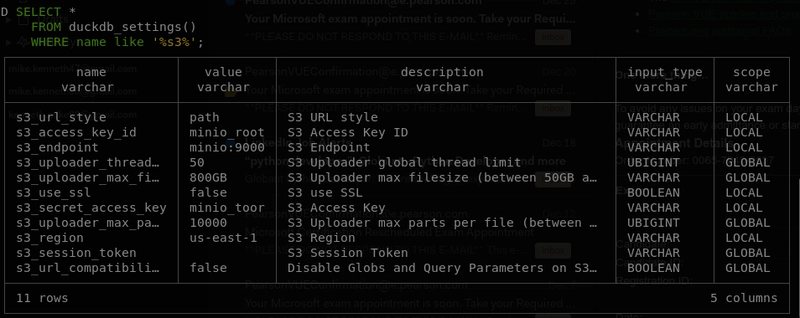
a) Connexion à MinIO (stockage compatible s3)
Pour interagir avec les données stockées dans MinIO, nous devons activer l'extension HTTPS et configurer les paramètres de connexion :
-- Enable the HTTPS Extension to connect to s3/Minio
INSTALL https;
LOAD https;
-- Set Connection settings
SET s3_region='us-east-1';
SET s3_url_style='path';
SET s3_endpoint='minio:9000';
SET s3_access_key_id='minio_root' ;
SET s3_secret_access_key='minio_toor';
SET s3_use_ssl=false; -- Needed when running without SSL
Vérifions si les paramètres sont correctement appliqués.
b) Connexion à PostgreSQL
Pour interroger les données dans notre instance PostgreSQL, nous devons charger l'extension PostgreSQL, puis nous attacher à la base de données :
-- Load Extension
INSTALL postgres;
LOAD postgres;
-- Attach the PostgreSQL database
ATTACH 'dbname=postgres user=postgres password=postgres host=postgres port=5432'
AS postgres_db (TYPE postgres, SCHEMA 'public');
Explication : La
INSTALL postgres;commande prend désormais en charge l'interaction avec les bases de données PostgreSQL.ATTACHElle établit une connexion à la base de données PostgreSQL spécifiée (dbname,user,password,host) et lui attribue l'aliaspostgres_db, rendant ainsi ses tables accessibles dans DuckDB. Nous spécifions également le type et le schéma de la base de données.
Nous pouvons maintenant créer une table dans PostgreSQL en lisant un fichier CSV à partir de notre instance MinIO :
-- Create the base table in Postgres from s3
create or replace table postgres_db.fct_trips as
(
select *
from read_csv("s3://duckdb-bucket/init_data/base_raw.csv")
);
c) Connexion à MySQL
-- Load Extension
INSTALL mysql;
LOAD mysql;
-- Attach the MYSQL database
ATTACH 'database=db user=user password=password host=mysql port=3306'
AS mysql_db (TYPE mysql);
Explication : Cette
INSTALL mysql;commande permet d'interagir avec les bases de données MySQL.ATTACHElle se connecte à la base de données MySQL à l'aide des informations d'identification fournies et lui attribue l'aliasmysql_db. Le type de base de données est également spécifié.
Créons une table dans MySQL en lisant un fichier CSV depuis MinIO :
-- Create the base table in MySQL from s3
create or replace table mysql_db.dim_credit_card as
(
select *
from read_csv("s3://duckdb-bucket/init_data/base_raw.csv")
);
Confirmons que les deux bases de données sont correctement connectées :
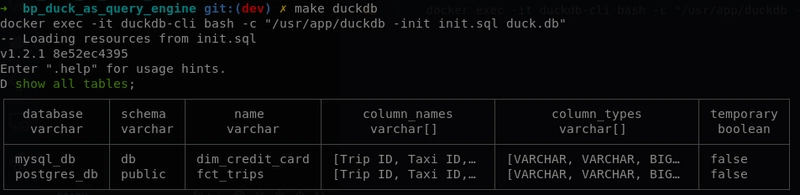
d) Requête de données JSON à partir d'un serveur Web
Enfin, démontrons comment récupérer des données directement à partir d’un serveur Web servant un fichier JSON :
select distinct *
from read_json('http://nginx:80/companies_data.json')
Cette requête lit et traite directement les données JSON disponibles à l'URL spécifiée.
Voici le résultat de la requête :
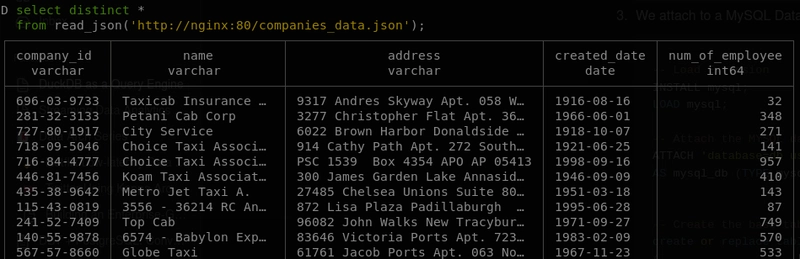
3. Interrogation simultanée de plusieurs sources de données
Avec la connectivité établie avec MinIO et nos bases de données relationnelles, nous pouvons désormais exécuter une seule requête qui récupère et joint les données de toutes nos sources configurées :
---------------- Query multiple Data Sources Simultaneously ----------------
with
fct_trips as (
select *
from postgres_db.public.fct_trips
),
dim_customer as (
select distinct *
from read_csv('s3://duckdb-bucket/init_data/customer.csv')
),
dim_creditcard as (
select distinct *
from mysql_db.db.dim_credit_card
),
dim_companies_data_web as (
select distinct *
from read_json('http://nginx:80/companies_data.json')
)
select
trips."Trip ID",
-- Customer info
dcust.id as customer_id, dcust.name as customer_name,dcust.sex as customer_sex,
dcust.address as customer_address, dcust.birth_date as customer_birth_date,
-- Credit Card info
dcard.credit_card_number as credit_card_number, dcard.expire_date as credit_card_expire_date,
dcard.provider as credit_card_provider, dcard.owner_name as credit_card_owner_name,
-- Company info
dcompany.name as company_name, dcompany.address as company_address,
dcompany.created_date as company_created_date, dcompany.num_of_employee as company_num_of_employee
from fct_trips trips
LEFT JOIN dim_customer dcust on trips.customer_id = dcust.id
LEFT JOIN dim_creditcard dcard on trips.credit_card_number = dcard.credit_card_number
LEFT JOIN dim_companies_data_web dcompany on trips.Company = dcompany.name;
Résultat:
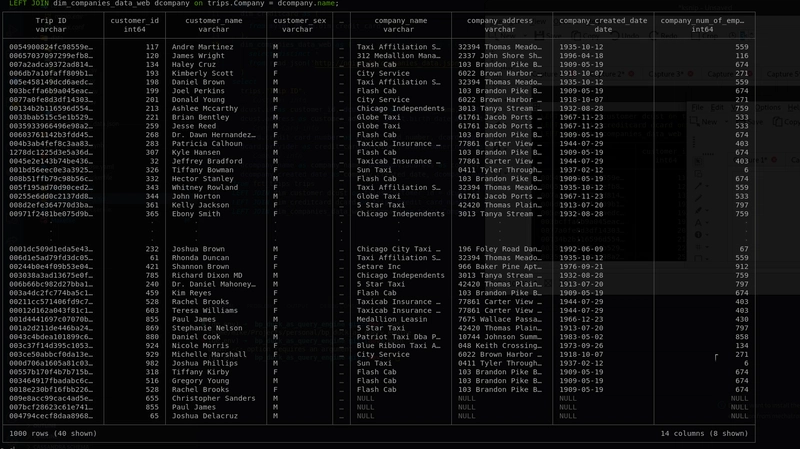
4. Exportation des résultats de la requête
De plus, DuckDB permet d'exporter directement les résultats de requêtes vers un stockage externe, tel que S3/MinIO, dans différents formats de fichiers. Ici, nous allons exporter les données jointes au format Parquet :
COPY (
with
fct_trips as (
select *
from postgres_db.public.fct_trips
...
...
...
from fct_trips trips
LEFT JOIN dim_customer dcust on trips.customer_id = dcust.id
LEFT JOIN dim_creditcard dcard on trips.credit_card_number = dcard.credit_card_number
LEFT JOIN dim_companies_data_web dcompany on trips.Company = dcompany.name
) TO 's3://duckdb-bucket/query_result.parquet' (FORMAT parquet);
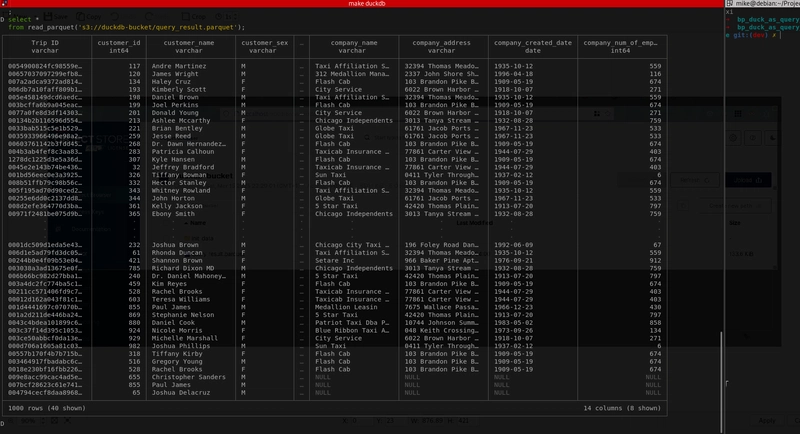
Nous pouvons ensuite vérifier le contenu du fichier Parquet exporté directement avec DuckDB
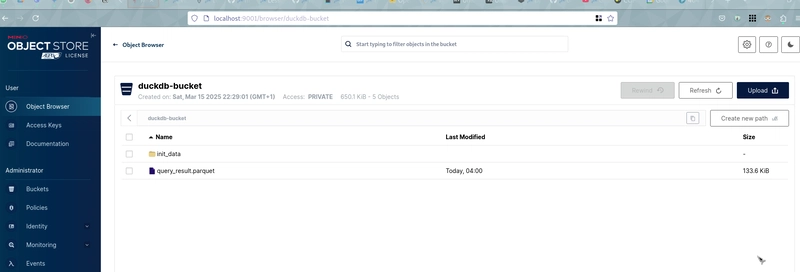
Nous pouvons ensuite valider le fichier exporté :
SELECT * FROM read_parquet('s3://duckdb-bucket/query_result.parquet');
Conclusion
DuckDB est un moteur de requête puissant et léger qui permet d'interroger facilement plusieurs sources. Que vous travailliez avec des fichiers CSV, des bases de données ou des données JSON web, son interface SQL simple et ses hautes performances en font un excellent choix pour l'analyse. À mesure que l'écosystème se développe, DuckDB continue d'ajouter de nouvelles fonctionnalités, ce qui en fait une alternative solide pour le traitement local des données.