











































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)
























































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)


























































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


























































































![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)






























































































































"Designing Data-Intensive Applications": Chapter 1 - Foundations of Data Systems
Welcome to the very first chapter of my epic adventure through Designing Data-Intensive Applications by Martin Kleppmann. Some call it the Bible of System Design. As for me, I call it my new good friend (sorry, coffee mug, you're now replaced). If you're a software engineer like me—curious, sometimes overwhelmed, and always ready for a good meme—you're in the right place. I'll be sharing what I learn, chapter by chapter, in language that's more "hanging out at a coffee shop" and less "I have a PhD in distributed systems." Let's get into Chapter 1: Reliable, Scalable, and Maintainable Applications. And yes, there will be bad jokes. Why Am I Reading This Book? (And Maybe You Should Too) Let's face it: today's apps are less about flexing CPU power and more about wrestling with mountains of data—think Netflix recommendations, petabytes of dog videos, and those wild "You May Also Like" algorithms. The bottleneck isn't usually the CPU—it's the data: how much there is, how messy it gets, and how fast it changes. This book promises not just to tell us what to do, but how to think about building systems that handle all this data without falling over and making us cry (or worse, making our users cry). Whether you're a newbie or a seasoned sysadmin with battle scars, this book is for anyone who's ever had a system go down at 2am and thought, "There must be a better way." Chapter 1: The Three Pillars of Data Systems (a.k.a. The Holy Trinity) Martin says that every robust data system stands on three pillars: reliability, scalability, and maintainability. If you're missing even one, your project is basically a Jenga tower at a toddler's birthday party. But first, a quick pit stop: most modern data-intensive apps are built with a few trusty building blocks: Databases: Your data's forever home. Caches: The "are we there yet?" of system design—speeding up delivery by remembering answers. Search Indexes: Like Google for your own app. Stream Processing: Passing messages around asynchronously, so things don't get stuck waiting. Batch Processing: When you need to crunch a mountain of data, preferably while you're sleeping. Let's break down the big three: 1. Reliability: When "It Works on My Machine" Isn't Enough Reliability means your system keeps working—even when the universe conspires against you. And trust me, it will. The Usual Suspects Hardware Faults: Hard drives die. Power goes out. Sometimes, the server room AC is set to sweat lodge mode. Modern systems assume hardware will fail and build in redundancy. Thank you, software engineers of the world! Software Errors: Bugs, memory leaks, the infamous "works only on Tuesdays." Software can be sneaky—sometimes the bug only bites when you're on vacation. Human Errors: Aka "I thought this was the staging database." Turns out, most outages are caused by us—humans. Guess we're not that reliable after all. How Do We Fight Back? Make it hard to mess up—sandbox environments, good tests, and big "Are you sure?" buttons help. Recover quickly from mistakes. Monitor everything. If a rocket needs telemetry to know what's going on after launch, your app probably needs it too. The Human Side Imagine a parent storing baby photos in your app. Now imagine those photos vanish forever. Yikes. Reliability isn't just a technical checkbox—it's about real people trusting you not to lose their memories. No pressure. 2. Scalability: Because "It Just Needs to Handle a Few Users" is a Lie Every founder ever: "We'll just launch with a simple prototype." Six months later, you've got a viral TikTok and a server crying in the corner. What Does "Scalable" Even Mean? Saying "X is scalable" is about as useful as saying "X is delicious." It depends! As your data, traffic, and users grow, how does your system cope? What knobs can you turn when things get crazy? Load Parameters (a.k.a. "How Much Stuff Are We Dealing With?") Requests per second Ratio of reads vs. writes Number of active users Cache hit rates Or whatever metric keeps you up at night The Twitter Example: To Fanout or Not to Fanout? Approach 1: Read-time Fanout Every time someone checks their timeline, grab all tweets from everyone they follow and merge them on the fly. (Spoiler: great for your first 200 users.) SELECT tweets.*, users.* FROM tweets JOIN users ON tweets.sender_id = users.id JOIN follows ON follows.followee_id = users.id WHERE follows.follower_id = current_user Approach 2: Write-time Fanout Every time someone tweets, stuff it into every follower's timeline cache. Now reading is cheap and fast—until Kim Kardashian logs in and breaks your database. So Twitter…uses both. Most users get fast, precomputed timelines, but if you're super famous, your tweets get fetched and merged dynamically. Because, as always, "it depends." Performance: It's Not Just About Average
Welcome to the very first chapter of my epic adventure through Designing Data-Intensive Applications by Martin Kleppmann. Some call it the Bible of System Design. As for me, I call it my new good friend (sorry, coffee mug, you're now replaced).
If you're a software engineer like me—curious, sometimes overwhelmed, and always ready for a good meme—you're in the right place. I'll be sharing what I learn, chapter by chapter, in language that's more "hanging out at a coffee shop" and less "I have a PhD in distributed systems." Let's get into Chapter 1: Reliable, Scalable, and Maintainable Applications. And yes, there will be bad jokes.
Why Am I Reading This Book? (And Maybe You Should Too)
Let's face it: today's apps are less about flexing CPU power and more about wrestling with mountains of data—think Netflix recommendations, petabytes of dog videos, and those wild "You May Also Like" algorithms. The bottleneck isn't usually the CPU—it's the data: how much there is, how messy it gets, and how fast it changes.
This book promises not just to tell us what to do, but how to think about building systems that handle all this data without falling over and making us cry (or worse, making our users cry). Whether you're a newbie or a seasoned sysadmin with battle scars, this book is for anyone who's ever had a system go down at 2am and thought, "There must be a better way."
Chapter 1: The Three Pillars of Data Systems (a.k.a. The Holy Trinity)
Martin says that every robust data system stands on three pillars: reliability, scalability, and maintainability. If you're missing even one, your project is basically a Jenga tower at a toddler's birthday party.
But first, a quick pit stop: most modern data-intensive apps are built with a few trusty building blocks:
- Databases: Your data's forever home.
- Caches: The "are we there yet?" of system design—speeding up delivery by remembering answers.
- Search Indexes: Like Google for your own app.
- Stream Processing: Passing messages around asynchronously, so things don't get stuck waiting.
- Batch Processing: When you need to crunch a mountain of data, preferably while you're sleeping.
Let's break down the big three:
1. Reliability: When "It Works on My Machine" Isn't Enough
Reliability means your system keeps working—even when the universe conspires against you. And trust me, it will.
The Usual Suspects
- Hardware Faults: Hard drives die. Power goes out. Sometimes, the server room AC is set to sweat lodge mode. Modern systems assume hardware will fail and build in redundancy. Thank you, software engineers of the world!
- Software Errors: Bugs, memory leaks, the infamous "works only on Tuesdays." Software can be sneaky—sometimes the bug only bites when you're on vacation.
- Human Errors: Aka "I thought this was the staging database." Turns out, most outages are caused by us—humans. Guess we're not that reliable after all.
How Do We Fight Back?
- Make it hard to mess up—sandbox environments, good tests, and big "Are you sure?" buttons help.
- Recover quickly from mistakes.
- Monitor everything. If a rocket needs telemetry to know what's going on after launch, your app probably needs it too.
The Human Side
Imagine a parent storing baby photos in your app. Now imagine those photos vanish forever. Yikes. Reliability isn't just a technical checkbox—it's about real people trusting you not to lose their memories. No pressure.
2. Scalability: Because "It Just Needs to Handle a Few Users" is a Lie
Every founder ever: "We'll just launch with a simple prototype." Six months later, you've got a viral TikTok and a server crying in the corner.
What Does "Scalable" Even Mean?
Saying "X is scalable" is about as useful as saying "X is delicious." It depends! As your data, traffic, and users grow, how does your system cope? What knobs can you turn when things get crazy?
Load Parameters (a.k.a. "How Much Stuff Are We Dealing With?")
- Requests per second
- Ratio of reads vs. writes
- Number of active users
- Cache hit rates
- Or whatever metric keeps you up at night
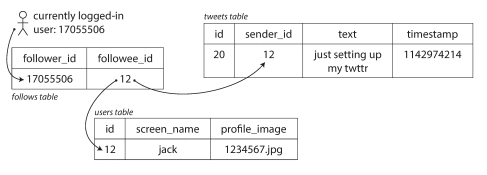
The Twitter Example: To Fanout or Not to Fanout?
Approach 1: Read-time Fanout
Every time someone checks their timeline, grab all tweets from everyone they follow and merge them on the fly. (Spoiler: great for your first 200 users.)
SELECT tweets.*, users.* FROM tweets
JOIN users ON tweets.sender_id = users.id
JOIN follows ON follows.followee_id = users.id
WHERE follows.follower_id = current_user
Approach 2: Write-time Fanout
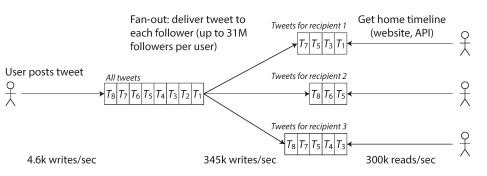
Every time someone tweets, stuff it into every follower's timeline cache. Now reading is cheap and fast—until Kim Kardashian logs in and breaks your database.
So Twitter…uses both. Most users get fast, precomputed timelines, but if you're super famous, your tweets get fetched and merged dynamically. Because, as always, "it depends."
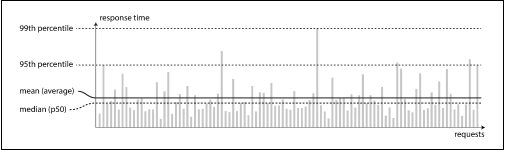
Performance: It's Not Just About Averages
The book says to skip averages—focus on percentiles. Why? Because your angriest users are the ones stuck waiting at the 99.9th percentile.
X Percentile of a given request in this context means that there are X percentage of requests slower than the given.
Did you know Amazon found that a 100ms delay costs them 1% in sales? And a 1-second delay drops customer satisfaction by 16%? Now that's incentive to optimize.
Scaling Up vs. Scaling Out
- Scaling Up: Bigger machines. (Vertical Scaling)
- Scaling Out: More machines. (Horizontal Scaling)
Most real systems mix both.
And if you're looking for a "magic scaling sauce," sorry—every app is different. There's no secret recipe, just a lot of experience, trial, and error.
3. Maintainability: For the Future-You (and Your Team)
Let's be honest: most of the cost in software comes after you launch. Maintenance is where the real pain (and sometimes glory) is.
Three Principles to Live By
Operability:
Make it easy for ops teams to keep things running. Good ops can save bad software—but bad ops can sink even the best code.
- Monitor everything.
- Automate what you can.
- Document everything.
- Good defaults, but let experts override.
Simplicity:
Complexity is like glitter—you'll never get rid of it all, but you can try. Symptoms of "big ball of mud" syndrome: tangled dependencies, wild state space, special-case hacks, and naming that makes no sense.
- Remove accidental complexity.
- Use abstraction wisely.
- Make it easy for new engineers to ramp up. (Don't make them solve a riddle to understand your code.)
Evolvability:
Change is the only constant. Your system should be able to adapt—new features, new requirements, new bosses with "just one more thing."
- Keep things simple and well-abstracted.
- Use practices like TDD and refactoring.
- Remember, the next person who works on this code might be you…six months from now…at 3am.
Reflections (and a Pep Talk)
What struck me most about this chapter is how these three pillars—reliability, scalability, and maintainability—aren't just technical checkboxes. They're connected to the real world: to business outcomes, user happiness, and to our own sanity as engineers.
The Twitter example is more than a story; it's a peek into how real companies wrestle with trade-offs. And when Amazon says "milliseconds matter," you know the stakes are high.
System design isn't just about picking the fanciest tech. It's about making thoughtful trade-offs, learning from mistakes, and always, always thinking about the humans on the other side of the screen (and those who'll maintain your code later).
What's Next?
Next up: data models and query languages! (Spoiler: how you store and fetch data changes everything.) If you've ever wondered why NoSQL exists or whether SQL is secretly a wizard, you won't want to miss it.
What about you? Had any reliability horror stories? Ever scaled an app and watched it break gloriously? Or maybe you've inherited a "big ball of mud" codebase and lived to tell the tale? Drop your stories or questions in the comments—I'd love to hear them!
Buckle up—this journey's just getting started.


