












































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)






























































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.png?#)























.webp?#)










_Christophe_Coat_Alamy.jpg?#)
 (1).webp?#)





































































































![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)
![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)





























































































































Databases: Indexes. Part 1
This article will introduce you to the concept of database indexes. Before diving into indexes, it’s recommended to first read about how databases store data, as this will provide a better understanding of how indexes fit into the overall database architecture. What Is An Index In a Database? An index in a database is like the table of contents in a book. It helps the database find information faster, just like a table of contents helps you quickly find a chapter in a book. Normally, when you search for something in a database, it has to scan every row in a table, which takes time. An index is a special structure that keeps track of where data is stored, allowing the database to find it quickly. It works similarly to a library catalog, which helps locate books without checking every shelf, making searches more efficient. Why Are Indexes Important ? In database management, indexes are very helpful tools. They make it easier and faster to find and retrieve specific information. Here are some key benefits: Faster Data Retrieval - when searching for a specific record, an index allows the database to find the result directly, instead of scanning every row. This significantly reduces query time. Efficient Sorting and Filtering - queries with ORDER BY or WHERE conditions run much faster because the database can use the index instead of sorting or filtering all rows manually. Better Performance for Large Databases - as data increases, queries can slow down. Indexes help keep search times consistent, even when dealing with millions of records. Optimized Joins Between Tables - indexes speed up JOIN operations by quickly matching related records between tables, making complex queries more efficient. These benefits make indexes essential for maintaining the performance and efficiency of databases, especially as they grow larger. How Indexes Are Stored in a Database Indexes are stored separately from the main table data. They act as a separate data structure that is linked to the table. An index typically stores a reference to the row in the table and the indexed column's value. Most relational databases use B-trees (Balanced Trees) or hash tables for storing indexes. The structure allows efficient lookups, insertions, and deletions. Here's how it works: B-trees (or B+ trees): These are the most common data structures used for indexing. The tree structure allows the database to maintain sorted values, and the search can quickly navigate the tree in a logarithmic manner, making the lookup faster. The leaf nodes of the tree contain the actual data pointers, allowing for efficient retrieval. Hash Indexes: A hash table uses a hash function to convert the indexed column's value into a fixed-size hash code, which then points to the data rows. This is efficient when dealing with equality searches (WHERE column = value), but it doesn’t support range queries (WHERE column > value). Why Indexes Are Fast The reason why an index speeds up searches in databases is the use of binary search. Without an index, if you wanted to search for a specific value in a large table, the database would have to scan every row to find the match. This process is known as a full table scan, and it has a time complexity of O(n), where n is the number of rows. With an index, the database doesn’t need to scan every row. It can use binary search to locate the desired data much faster. Binary search works by dividing the data in half repeatedly, narrowing down the search space quickly. Instead of checking every single record, it cuts the search space in half with each step. For example, in a sorted list, a binary search can locate an element in O(log n) time, where n is the number of items. The larger the data set, the more significant the performance improvement when using an index. Big O Notation Comparison - Full Table Scan (No Index): O(n) Every record is checked one by one. Time increases linearly with the number of records. - Indexed Search (Using Binary Search): O(log n) The number of checks decreases exponentially with each step. Even for large datasets, the number of operations remains much lower than a full table scan. As you can see from the graph, the time complexity for a full table scan increases linearly (O(n)) with the size of the dataset, while the time complexity for an indexed search using binary search increases logarithmically (O(log n)). How Indexes Help with Search in a Library Imagine you’re in a large library trying to find a specific book. The library has thousands of books, and you’re looking for a book titled “The Art of Programming”. Here’s how an index would help speed up the search: Without an Index If the books are randomly arranged on shelves, you’d have to check each book one by one to find the one you’re looking for. This is similar to performing a full table scan. The librarian would start at the first book and keep checking each title un

This article will introduce you to the concept of database indexes. Before diving into indexes, it’s recommended to first read about how databases store data, as this will provide a better understanding of how indexes fit into the overall database architecture.
What Is An Index In a Database?
An index in a database is like the table of contents in a book. It helps the database find information faster, just like a table of contents helps you quickly find a chapter in a book. Normally, when you search for something in a database, it has to scan every row in a table, which takes time. An index is a special structure that keeps track of where data is stored, allowing the database to find it quickly. It works similarly to a library catalog, which helps locate books without checking every shelf, making searches more efficient.
Why Are Indexes Important ?
In database management, indexes are very helpful tools. They make it easier and faster to find and retrieve specific information. Here are some key benefits:
- Faster Data Retrieval - when searching for a specific record, an index allows the database to find the result directly, instead of scanning every row. This significantly reduces query time.
- Efficient Sorting and Filtering - queries with ORDER BY or WHERE conditions run much faster because the database can use the index instead of sorting or filtering all rows manually.
- Better Performance for Large Databases - as data increases, queries can slow down. Indexes help keep search times consistent, even when dealing with millions of records.
- Optimized Joins Between Tables - indexes speed up JOIN operations by quickly matching related records between tables, making complex queries more efficient.
These benefits make indexes essential for maintaining the performance and efficiency of databases, especially as they grow larger.
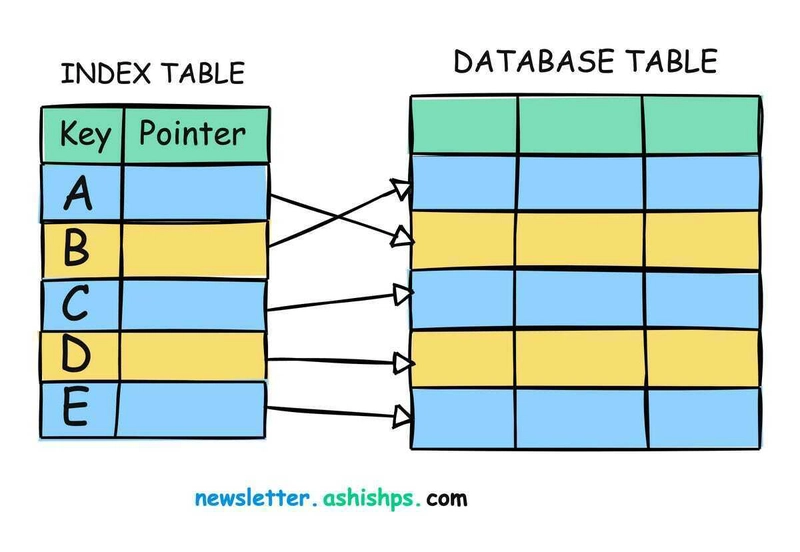
How Indexes Are Stored in a Database
Indexes are stored separately from the main table data. They act as a separate data structure that is linked to the table. An index typically stores a reference to the row in the table and the indexed column's value. Most relational databases use B-trees (Balanced Trees) or hash tables for storing indexes. The structure allows efficient lookups, insertions, and deletions. Here's how it works:
B-trees (or B+ trees): These are the most common data structures used for indexing. The tree structure allows the database to maintain sorted values, and the search can quickly navigate the tree in a logarithmic manner, making the lookup faster. The leaf nodes of the tree contain the actual data pointers, allowing for efficient retrieval.
Hash Indexes: A hash table uses a hash function to convert the indexed column's value into a fixed-size hash code, which then points to the data rows. This is efficient when dealing with equality searches (WHERE column = value), but it doesn’t support range queries (WHERE column > value).
Why Indexes Are Fast
The reason why an index speeds up searches in databases is the use of binary search.
Without an index, if you wanted to search for a specific value in a large table, the database would have to scan every row to find the match. This process is known as a full table scan, and it has a time complexity of O(n), where n is the number of rows. With an index, the database doesn’t need to scan every row. It can use binary search to locate the desired data much faster. Binary search works by dividing the data in half repeatedly, narrowing down the search space quickly. Instead of checking every single record, it cuts the search space in half with each step.
For example, in a sorted list, a binary search can locate an element in O(log n) time, where n is the number of items. The larger the data set, the more significant the performance improvement when using an index.
Big O Notation Comparison
- Full Table Scan (No Index): O(n)
Every record is checked one by one. Time increases linearly with the number of records.
- Indexed Search (Using Binary Search): O(log n)
The number of checks decreases exponentially with each step. Even for large datasets, the number of operations remains much lower than a full table scan.
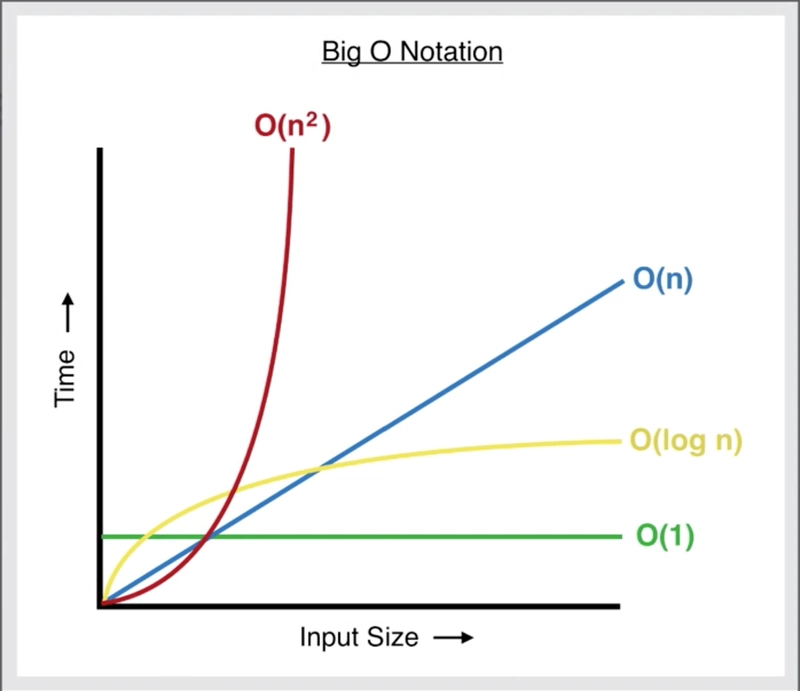
As you can see from the graph, the time complexity for a full table scan increases linearly (O(n)) with the size of the dataset, while the time complexity for an indexed search using binary search increases logarithmically (O(log n)).
How Indexes Help with Search in a Library
Imagine you’re in a large library trying to find a specific book. The library has thousands of books, and you’re looking for a book titled “The Art of Programming”. Here’s how an index would help speed up the search:
Without an Index
If the books are randomly arranged on shelves, you’d have to check each book one by one to find the one you’re looking for. This is similar to performing a full table scan. The librarian would start at the first book and keep checking each title until they find “The Art of Programming”. If there are 100,000 books, you might have to check a lot of them before finding your desired book.



