












































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)






























































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.png?#)























.webp?#)










_Christophe_Coat_Alamy.jpg?#)
 (1).webp?#)





































































































![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)
![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)





























































































































Database Sharding: Breaking It Down Without Breaking Your DB
When your application grows and the database starts wheezing under load, you have two choices: scale up (buy beefier hardware) or scale out (distribute the load). Sharding is the latter—a technique where we split a database into smaller, more manageable pieces to improve performance and scalability. Let's dive into what sharding is, why it matters, the different types, and some pitfalls to watch out for. What is Database Sharding? Imagine a library. Instead of one massive bookshelf with all the books, you split them into separate sections based on genres, making it easier to find what you're looking for. Sharding does the same thing for databases—dividing data across multiple servers (shards) so that no single database carries the entire load. Each shard is an independent database, and collectively, they function as a single system. Queries get directed to the appropriate shard, reducing overall query time and improving performance. Why Use Sharding? Sharding isn't just for fun; it's a necessity when: Your database outgrows the capacity of a single machine. Query performance degrades as data volume increases. You need high availability and fault tolerance. Scaling up (buying expensive hardware) is no longer a viable option. You have geographically distributed users and want faster local access. Types of Sharding Not all sharding strategies are created equal. The choice depends on your data, query patterns, and scalability goals. Here are the main types: 1. Key-Based (Hash) Sharding How it works: A hash function determines which shard a piece of data belongs to. Example: shard_id = hash(user_id) % total_shards Pros: Even distribution of data across shards Prevents hot spots (a single overloaded shard) Cons: Rebalancing is hard if you add/remove shards Joins across shards are complex 2. Geo Sharding How it works: Data is partitioned based on user location. Example: Users in Europe are served by EU servers, and US users by North American servers. Pros: Reduces latency by keeping data close to users Easier compliance with regional data laws Cons: Uneven distribution (some regions might have more users) Handling cross-region queries is tricky 3. Directory-Based (Lookup) Sharding How it works: A central lookup table keeps track of which shard stores which data. Pros: High flexibility in sharding logic Easy to add/remove shards dynamically Cons: The lookup table can become a bottleneck Extra overhead of maintaining the mapping 4. Range-Based Sharding (A-I, J-R, S-Z, etc.) How it works: Data is divided based on a range of values. Example: Users with names starting from A-I go to Shard 1, J-R to Shard 2, and so on. Pros: Easy to implement and query Works well when query patterns align with data distribution Cons: Can lead to hot spots (some shards getting more traffic than others) Harder to rebalance dynamically 5. Vertical Sharding How it works: Different tables or columns are stored in different shards. Example: User profile data is on one shard, while orders are on another. Pros: Helps isolate high-traffic tables Reduces complexity of horizontal partitioning Cons: Doesn't scale well for growing datasets Cross-shard joins can be painful Drawbacks of Sharding Sharding isn't a silver bullet. Here are some challenges: Complexity: Managing multiple shards requires more maintenance. Rebalancing: Adding/removing shards can be difficult, especially with hash-based sharding. Joins Across Shards: Queries that need data from multiple shards are expensive and slow. Data Consistency: Ensuring consistency across shards can be tricky. Backup & Recovery: Each shard needs its own backup strategy. Sharding is a powerful tool for scaling databases, but it comes with trade-offs. The right sharding strategy depends on your data structure, access patterns, and long-term growth plans. If implemented correctly, sharding can supercharge your database performance and ensure your application scales smoothly. Just be prepared for the extra complexity. Tip: Before sharding, consider optimizing indexes, caching, and read replicas. Sometimes, these strategies can delay the need for sharding altogether. Speed Up DB Queries Like a Pro Athreya aka Maneshwar ・ Feb 6 #webdev #programming #beginners #database I’ve been working on a super-convenient tool called LiveAPI. LiveAPI helps you get all your backend APIs documented in a few minutes With LiveAPI, you can quickly generate interactive API documentation that allows users to execute APIs directly from the browser. If you’re tired of manually creating docs for your APIs, this tool might just ma
When your application grows and the database starts wheezing under load, you have two choices: scale up (buy beefier hardware) or scale out (distribute the load).
Sharding is the latter—a technique where we split a database into smaller, more manageable pieces to improve performance and scalability.
Let's dive into what sharding is, why it matters, the different types, and some pitfalls to watch out for.
What is Database Sharding?
Imagine a library.
Instead of one massive bookshelf with all the books, you split them into separate sections based on genres, making it easier to find what you're looking for.
Sharding does the same thing for databases—dividing data across multiple servers (shards) so that no single database carries the entire load.
Each shard is an independent database, and collectively, they function as a single system.
Queries get directed to the appropriate shard, reducing overall query time and improving performance.
Why Use Sharding?
Sharding isn't just for fun; it's a necessity when:
- Your database outgrows the capacity of a single machine.
- Query performance degrades as data volume increases.
- You need high availability and fault tolerance.
- Scaling up (buying expensive hardware) is no longer a viable option.
- You have geographically distributed users and want faster local access.
Types of Sharding
Not all sharding strategies are created equal.
The choice depends on your data, query patterns, and scalability goals.
Here are the main types:
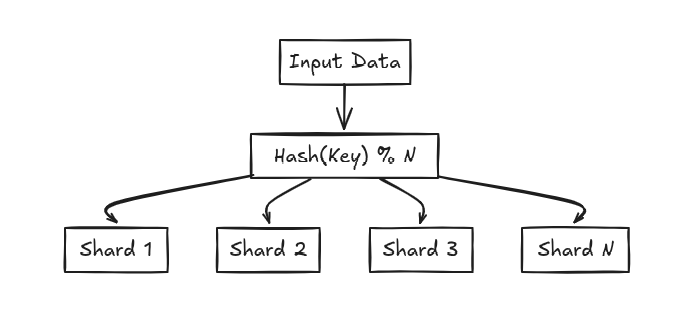
1. Key-Based (Hash) Sharding
How it works:
- A hash function determines which shard a piece of data belongs to.
- Example:
shard_id = hash(user_id) % total_shards
Pros:
- Even distribution of data across shards
- Prevents hot spots (a single overloaded shard)
Cons:
- Rebalancing is hard if you add/remove shards
- Joins across shards are complex
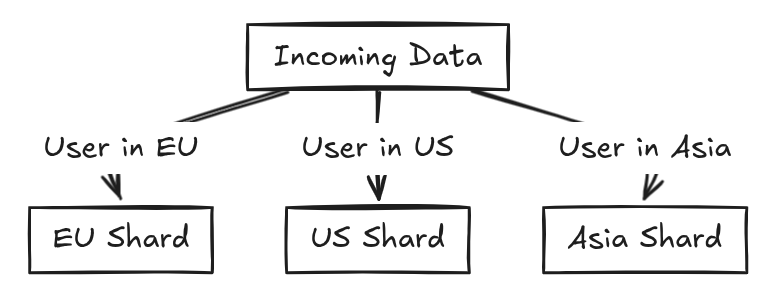
2. Geo Sharding
How it works:
- Data is partitioned based on user location.
- Example: Users in Europe are served by EU servers, and US users by North American servers.
Pros:
- Reduces latency by keeping data close to users
- Easier compliance with regional data laws
Cons:
- Uneven distribution (some regions might have more users)
- Handling cross-region queries is tricky
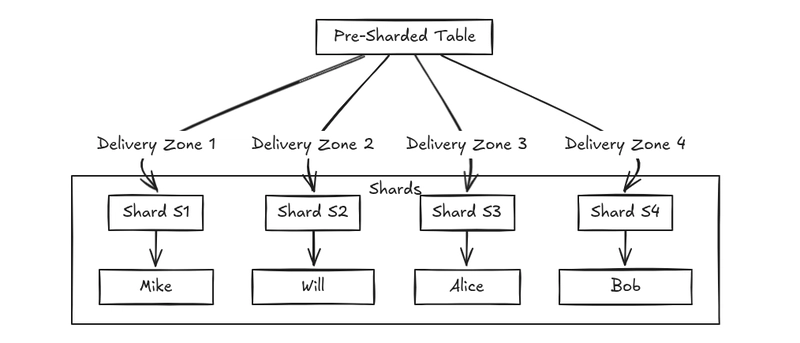
3. Directory-Based (Lookup) Sharding
How it works:
- A central lookup table keeps track of which shard stores which data.
Pros:
- High flexibility in sharding logic
- Easy to add/remove shards dynamically
Cons:
- The lookup table can become a bottleneck
- Extra overhead of maintaining the mapping
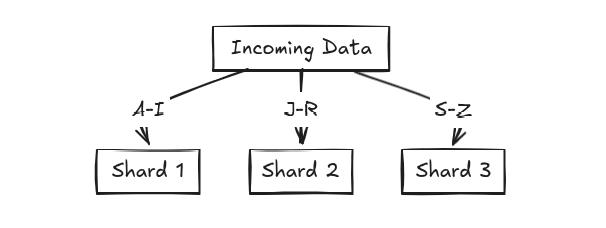
4. Range-Based Sharding (A-I, J-R, S-Z, etc.)
How it works:
- Data is divided based on a range of values.
- Example: Users with names starting from A-I go to Shard 1, J-R to Shard 2, and so on.
Pros:
- Easy to implement and query
- Works well when query patterns align with data distribution
Cons:
- Can lead to hot spots (some shards getting more traffic than others)
- Harder to rebalance dynamically
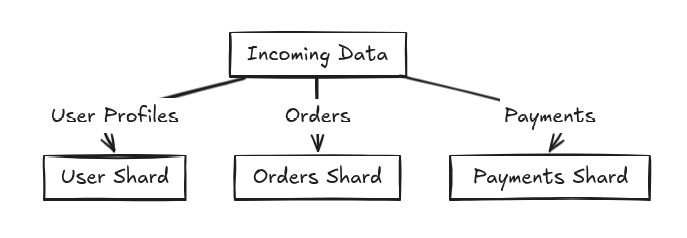
5. Vertical Sharding
How it works:
- Different tables or columns are stored in different shards.
- Example: User profile data is on one shard, while orders are on another.
Pros:
- Helps isolate high-traffic tables
- Reduces complexity of horizontal partitioning
Cons:
- Doesn't scale well for growing datasets
- Cross-shard joins can be painful
Drawbacks of Sharding
Sharding isn't a silver bullet. Here are some challenges:
- Complexity: Managing multiple shards requires more maintenance.
- Rebalancing: Adding/removing shards can be difficult, especially with hash-based sharding.
- Joins Across Shards: Queries that need data from multiple shards are expensive and slow.
- Data Consistency: Ensuring consistency across shards can be tricky.
- Backup & Recovery: Each shard needs its own backup strategy.

Sharding is a powerful tool for scaling databases, but it comes with trade-offs.
The right sharding strategy depends on your data structure, access patterns, and long-term growth plans.
If implemented correctly, sharding can supercharge your database performance and ensure your application scales smoothly.
Just be prepared for the extra complexity.
Tip: Before sharding, consider optimizing indexes, caching, and read replicas.
Sometimes, these strategies can delay the need for sharding altogether.

I’ve been working on a super-convenient tool called LiveAPI.
LiveAPI helps you get all your backend APIs documented in a few minutes
With LiveAPI, you can quickly generate interactive API documentation that allows users to execute APIs directly from the browser.

If you’re tired of manually creating docs for your APIs, this tool might just make your life easier.



