









































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






































































































































































































![Blue Archive tier list [April 2025]](https://media.pocketgamer.com/artwork/na-33404-1636469504/blue-archive-screenshot-2.jpg?#)
































.png?#)









-Baldur’s-Gate-3-The-Final-Patch---An-Animated-Short-00-03-43.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)












![Apple to Split Enterprise and Western Europe Roles as VP Exits [Report]](https://www.iclarified.com/images/news/97032/97032/97032-640.jpg)























































































































![Nanoleaf Announces New Pegboard Desk Dock With Dual-Sided Lighting [Video]](https://www.iclarified.com/images/news/97030/97030/97030-640.jpg)

![Apple's Foldable iPhone May Cost Between $2100 and $2300 [Rumor]](https://www.iclarified.com/images/news/97028/97028/97028-640.jpg)


























































































































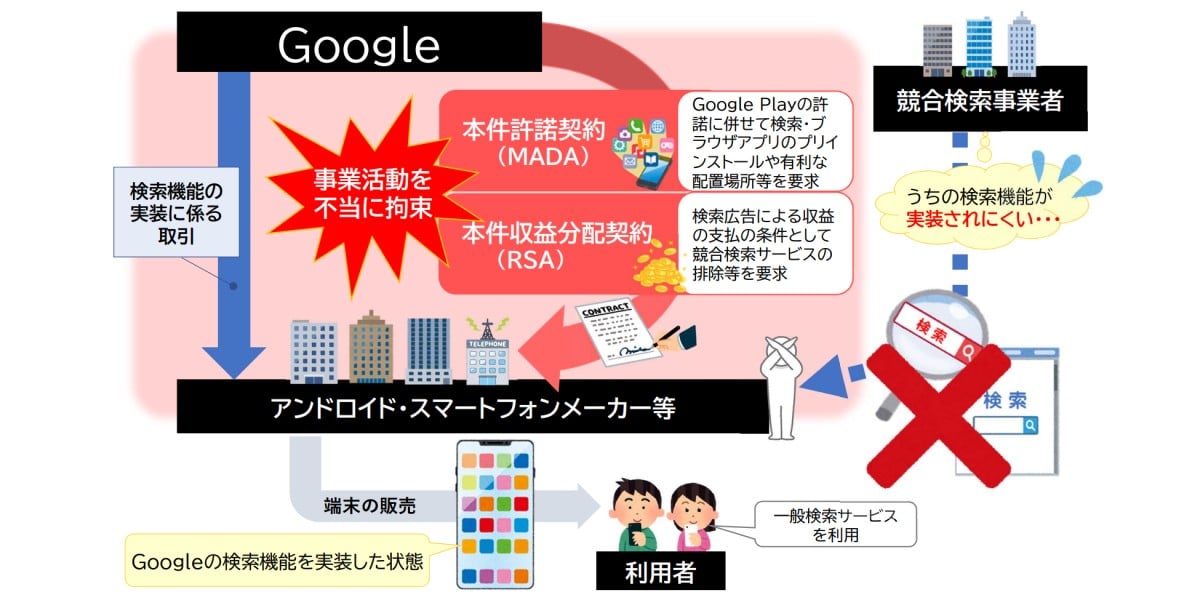
Data Models in DBMS
Database Management System allows us to store tons of data in an efficient manner. A Data Model defines how data is stored, connected and accessed. Essentially, it is the backbone of DBMS. Here are some common Data Models Explained, and how they store data: 1. Hierarchical Data Model A hierarchical database model organizes data in a tree-like structure. Data is stored in records, each made up of one or more fields, and each field holds a single value. The type of a record is defined by the combination of its fields. One special type of field is a link, which connects a record to other related records. These links create parent-child relationships between records, forming a tree structure where each record can link to multiple child records, but only one parent. Ex:- XML, Windows Registry 2. Network Data Model Here, in contrast to the Hierarchical Data Model, the network model allows each record to have multiple parents and multiple children, forming a more flexible graph-like structure. This applies on two levels: At the schema level, record types are connected through relationship types, forming a graph of how data can be related. At the data level, actual records (called record occurrences) are connected by relationships, also forming a graph Ex:- Integrated Data Store (IDS) 3. Relational Data Model In the relational data model, data is organized into tables, also known as relations. Each table consists of rows (called tuples) and columns (called attributes). Every row represents a single record, and each column represents a field containing a specific type of data. Relationships between data are established through keys: A primary key uniquely identifies each row in a table. A foreign key creates a link between rows in different tables by referencing the primary key of another table. Unlike the hierarchical or network models, the relational model does not rely on explicit pointers or predefined paths between records. Instead, relationships are inferred through matching key values, providing flexibility and ease of querying using structured query language (SQL). At both the schema level (structure of tables and keys) and the data level (actual rows and values), the relational model forms a logical structure rather than a physical graph or tree. This abstraction makes it easier to understand, maintain, and query complex data sets without dealing with how data is physically linked. Ex:- MySQL, PostgreSQL 4. Object Oriented Data Model In the object-oriented data model, data is represented as objects, similar to how it's handled in object-oriented programming languages. Each object contains both data (attributes) and behavior (methods), encapsulated into a single unit. Objects are grouped into classes, which define the structure (attributes) and behavior (methods) shared by all objects of that type. The model supports key object-oriented features such as: Inheritance – Classes can inherit attributes and methods from other classes, promoting code reuse and hierarchy. Encapsulation – Data and behavior are bundled together, protecting internal states and exposing only what is necessary. Polymorphism – Objects can be accessed through references of their parent class type, allowing flexibility in method usage. At the schema level, the structure of the database is defined through class hierarchies and object relationships. At the data level, actual object instances are stored, each maintaining its state and behavior. Relationships between objects can be expressed through object references, allowing complex structures like trees, graphs, and networks. The object-oriented model is especially suited for applications with complex data and behavior, such as CAD systems, multimedia databases, and object-oriented programming integrations. Ex:- db4o, ObjectDB 5. Document Data Model (used in NoSQL) In the document data model, data is stored in the form of documents, typically using formats like JSON, BSON, or XML. Each document is a self-contained unit that holds all the data for a single object or entity, including nested structures and arrays. Documents are grouped into collections (similar to tables in the relational model), but unlike rows in a table, documents in a collection do not need to follow a fixed schema—each can have a different structure. This model provides flexibility and is well-suited for handling semi-structured or hierarchical data. Key features include: Schema flexibility – Documents can evolve over time without requiring changes to a rigid schema. Embedded data – Related data can be stored within the same document (e.g., an order and its line items), reducing the need for joins. Rich queries – Document databases support powerful query languages to filter, project, and manipulate nested fields. Ex:- MongoDB, CouchDB 6. Key-Value Data Model (NoSQ
Database Management System allows us to store tons of data in an efficient manner. A Data Model defines how data is stored, connected and accessed. Essentially, it is the backbone of DBMS.
Here are some common Data Models Explained, and how they store data:
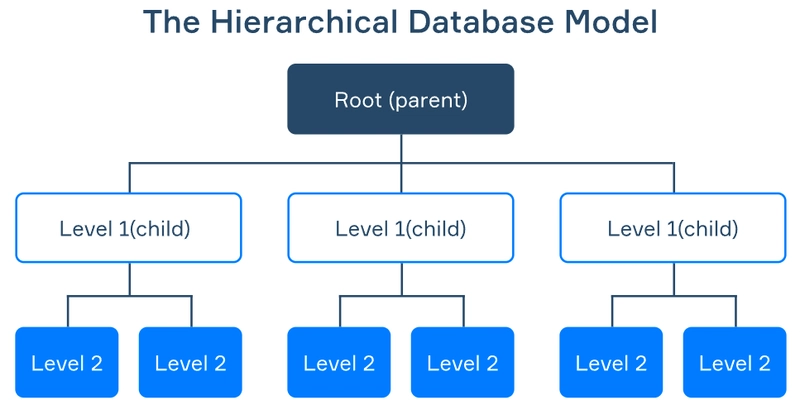
1. Hierarchical Data Model
A hierarchical database model organizes data in a tree-like structure. Data is stored in records, each made up of one or more fields, and each field holds a single value. The type of a record is defined by the combination of its fields. One special type of field is a link, which connects a record to other related records. These links create parent-child relationships between records, forming a tree structure where each record can link to multiple child records, but only one parent.
Ex:- XML, Windows Registry
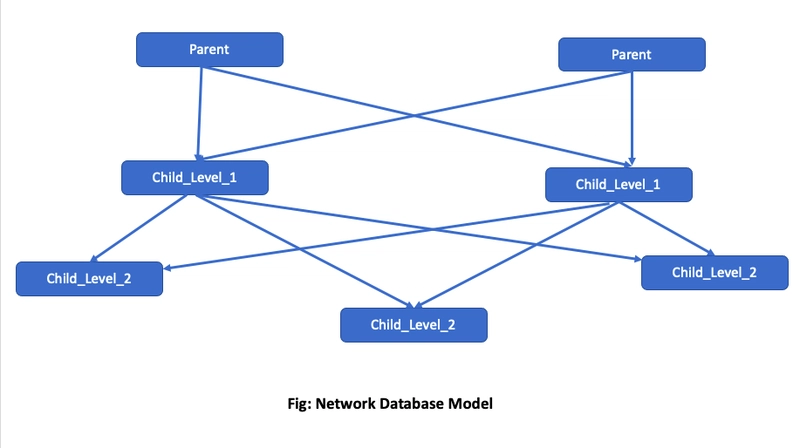
2. Network Data Model
Here, in contrast to the Hierarchical Data Model, the network model allows each record to have multiple parents and multiple children, forming a more flexible graph-like structure.
This applies on two levels:
- At the schema level, record types are connected through relationship types, forming a graph of how data can be related.
- At the data level, actual records (called record occurrences) are connected by relationships, also forming a graph
 Ex:- Integrated Data Store (IDS)
Ex:- Integrated Data Store (IDS)
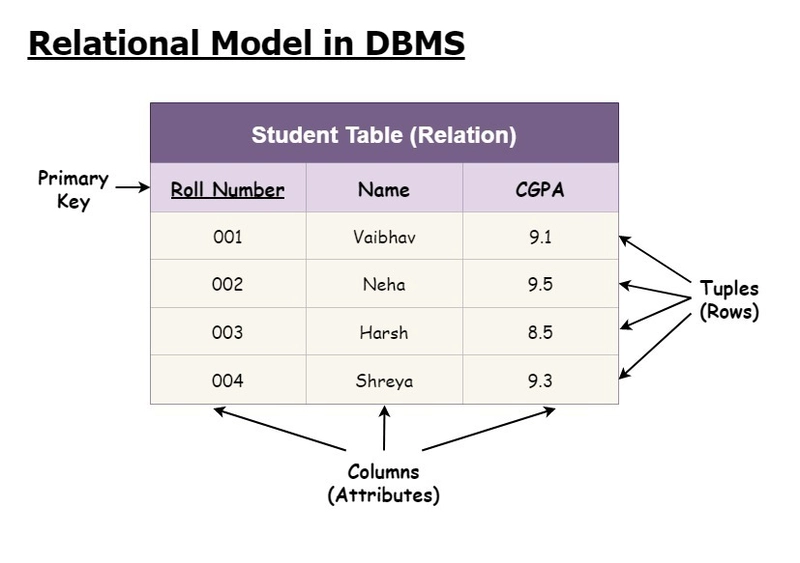
3. Relational Data Model
In the relational data model, data is organized into tables, also known as relations. Each table consists of rows (called tuples) and columns (called attributes). Every row represents a single record, and each column represents a field containing a specific type of data.
Relationships between data are established through keys:
- A primary key uniquely identifies each row in a table.
- A foreign key creates a link between rows in different tables by referencing the primary key of another table.
Unlike the hierarchical or network models, the relational model does not rely on explicit pointers or predefined paths between records. Instead, relationships are inferred through matching key values, providing flexibility and ease of querying using structured query language (SQL).
At both the schema level (structure of tables and keys) and the data level (actual rows and values), the relational model forms a logical structure rather than a physical graph or tree. This abstraction makes it easier to understand, maintain, and query complex data sets without dealing with how data is physically linked.
 Ex:- MySQL, PostgreSQL
Ex:- MySQL, PostgreSQL
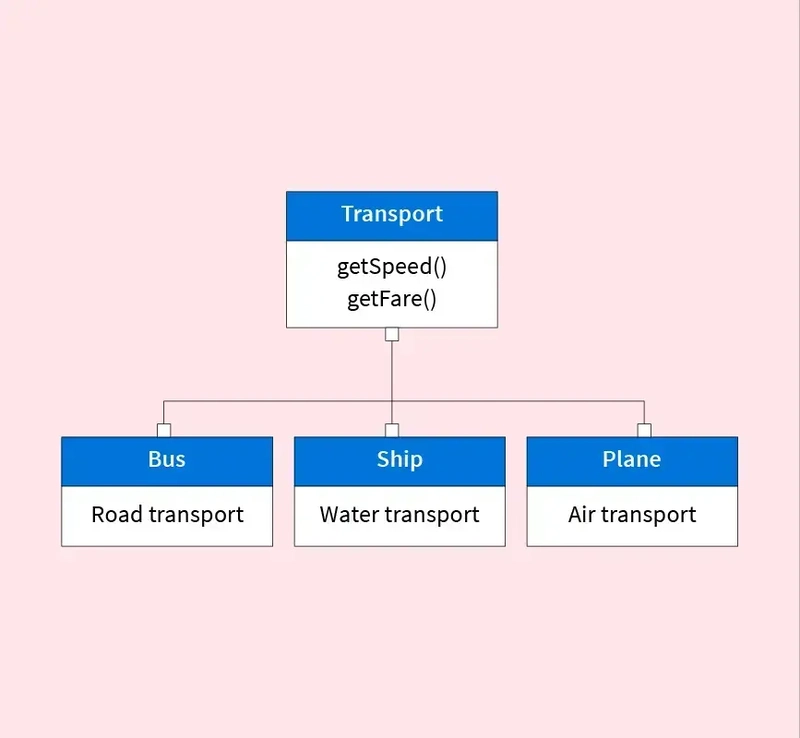
4. Object Oriented Data Model
In the object-oriented data model, data is represented as objects, similar to how it's handled in object-oriented programming languages. Each object contains both data (attributes) and behavior (methods), encapsulated into a single unit.
Objects are grouped into classes, which define the structure (attributes) and behavior (methods) shared by all objects of that type. The model supports key object-oriented features such as:
- Inheritance – Classes can inherit attributes and methods from other classes, promoting code reuse and hierarchy.
- Encapsulation – Data and behavior are bundled together, protecting internal states and exposing only what is necessary.
- Polymorphism – Objects can be accessed through references of their parent class type, allowing flexibility in method usage.
At the schema level, the structure of the database is defined through class hierarchies and object relationships.
At the data level, actual object instances are stored, each maintaining its state and behavior.
Relationships between objects can be expressed through object references, allowing complex structures like trees, graphs, and networks. The object-oriented model is especially suited for applications with complex data and behavior, such as CAD systems, multimedia databases, and object-oriented programming integrations.
 Ex:- db4o, ObjectDB
Ex:- db4o, ObjectDB
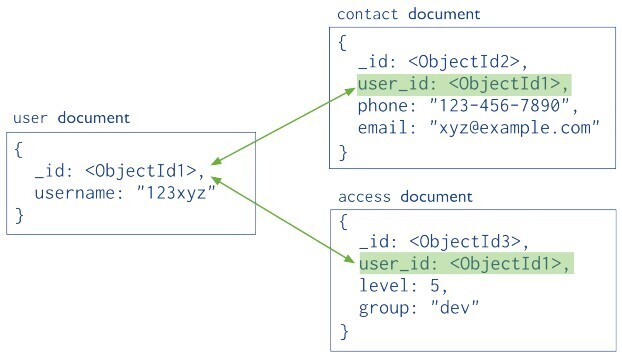
5. Document Data Model (used in NoSQL)
In the document data model, data is stored in the form of documents, typically using formats like JSON, BSON, or XML. Each document is a self-contained unit that holds all the data for a single object or entity, including nested structures and arrays.
Documents are grouped into collections (similar to tables in the relational model), but unlike rows in a table, documents in a collection do not need to follow a fixed schema—each can have a different structure. This model provides flexibility and is well-suited for handling semi-structured or hierarchical data.
Key features include:
- Schema flexibility – Documents can evolve over time without requiring changes to a rigid schema.
- Embedded data – Related data can be stored within the same document (e.g., an order and its line items), reducing the need for joins.
- Rich queries – Document databases support powerful query languages to filter, project, and manipulate nested fields.
 Ex:- MongoDB, CouchDB
Ex:- MongoDB, CouchDB
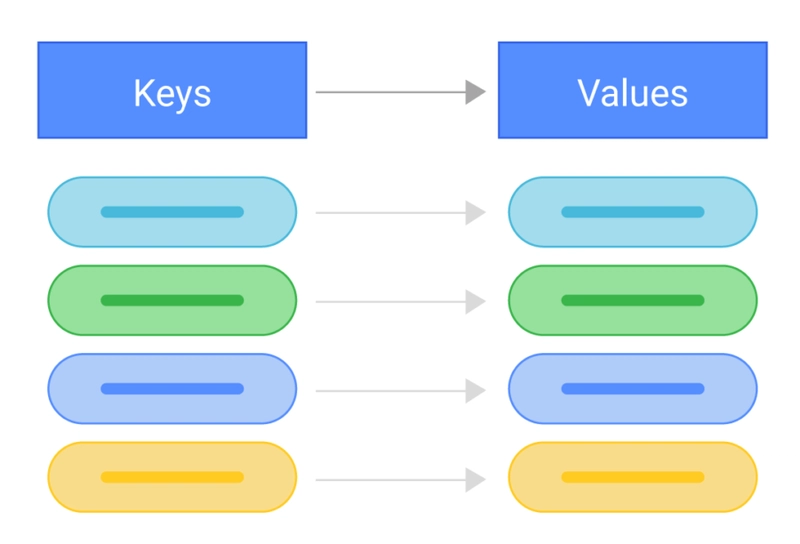
6. Key-Value Data Model (NoSQL)
The key-value data model is one of the simplest types of NoSQL database models. In this model, data is stored as a collection of key-value pairs, where:
- The key is a unique identifier.
- The value is the associated data, which can be a string, number, binary blob, JSON, or any arbitrary data.
- This model is often compared to a hash table or dictionary, where you retrieve data by providing its key.
Key-value databases are best suited for scenarios like:
- Caching (e.g., Redis, Memcached)
- Session management
- User preferences and profile storage
- Real-time data and large-scale applications
 Ex:- Redis, DynamoDB
Ex:- Redis, DynamoDB
7. Column-Family Data Model (NoSQL)
The column-family data model is a NoSQL model that stores data in columns rather than rows, making it especially suitable for large-scale, distributed systems that require fast read/write access across wide datasets.
In this model, data is organized into structures called column families, which are collections of related rows. Each row is identified by a row key, and contains multiple columns, grouped logically into column families.
Unlike the relational model:
- Columns are not fixed across all rows—each row can have a different set of columns.
- Columns can be grouped together for efficient storage and retrieval.
8. Graph Data Model
The graph data model represents data as a network of nodes and edges, making it ideal for capturing complex, interconnected relationships.
- Nodes represent entities (such as people, products, or locations).
- Edges represent relationships between those entities (such as "friends with", "purchased", or "located in").
- Both nodes and edges can have properties—key-value pairs that store relevant information. This structure allows relationships to be first-class citizens, meaning they can be directly queried, navigated, and analyzed.
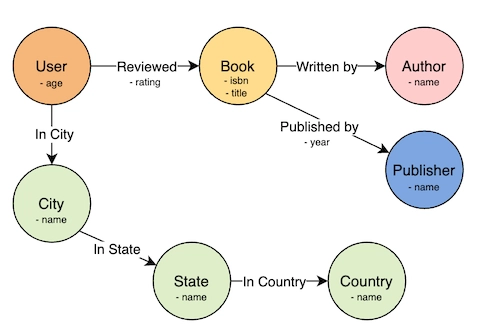 Ex:- Neo4j, Amazon Neptune
Ex:- Neo4j, Amazon Neptune



