










































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)










































































































(1).jpg?#)































_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)






































































































![Apple Developing AI 'Vibe-Coding' Assistant for Xcode With Anthropic [Report]](https://www.iclarified.com/images/news/97200/97200/97200-640.jpg)
![Apple's New Ads Spotlight Apple Watch for Kids [Video]](https://www.iclarified.com/images/news/97197/97197/97197-640.jpg)



























































































Cross-Platform Software Development – Part 1: Yes, Bytes Can Be 9 Bits
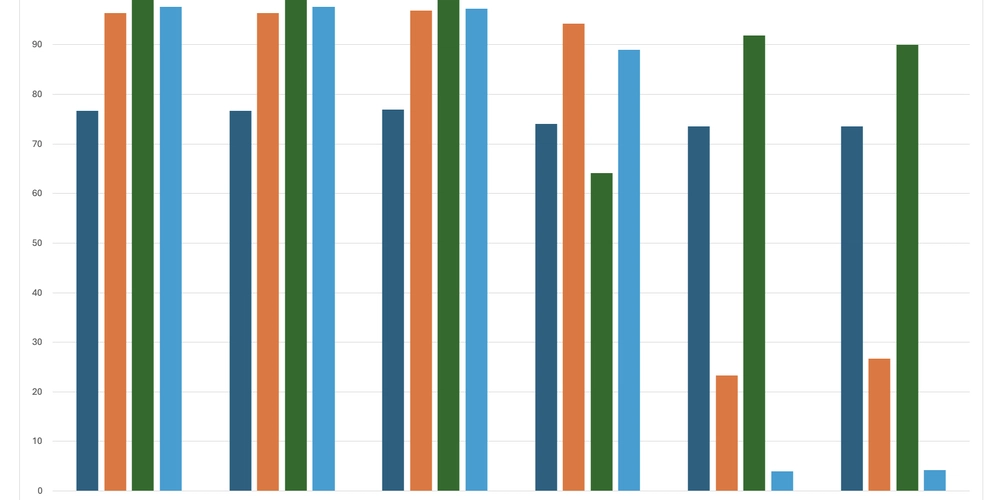
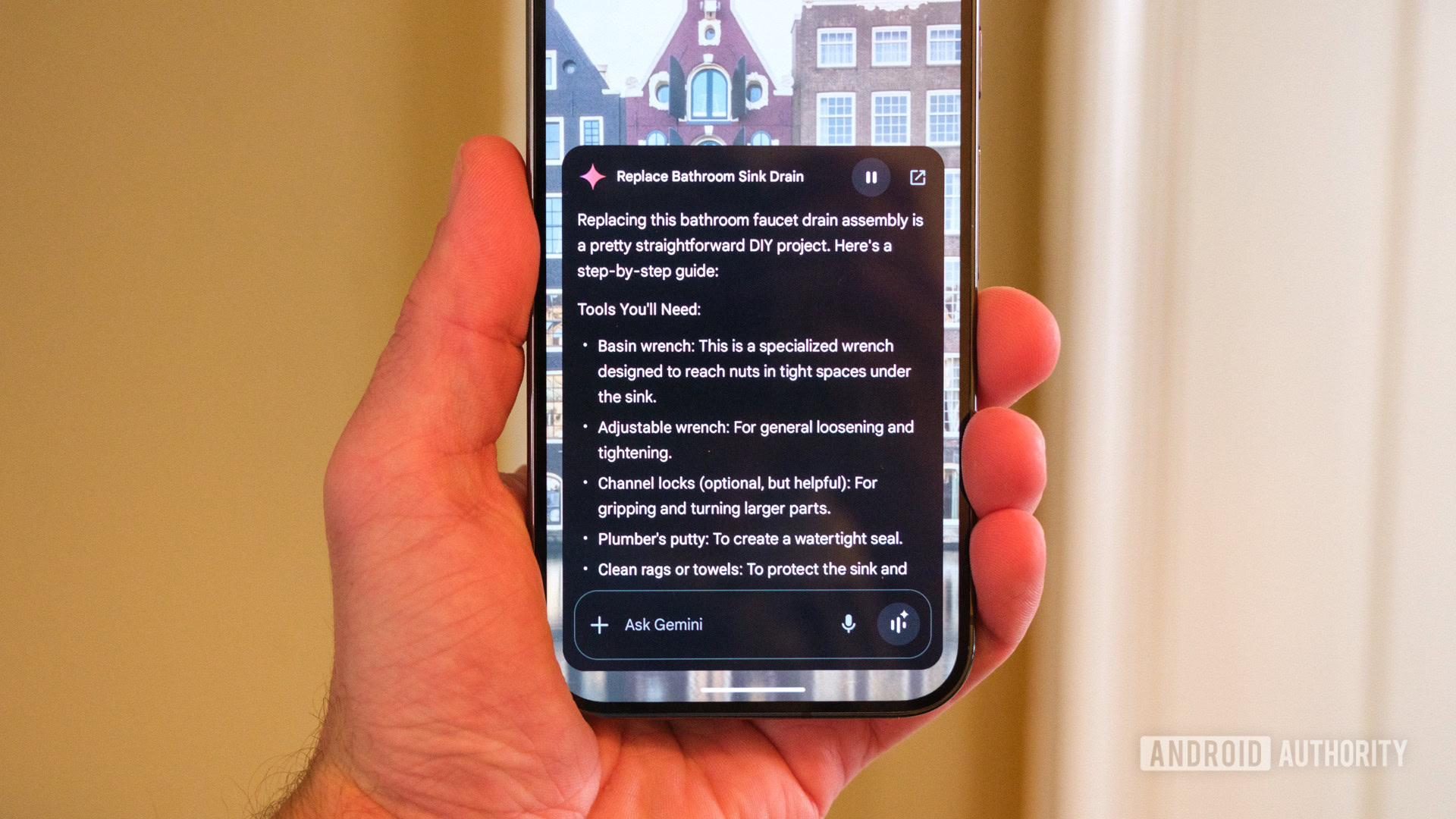
When we say cross-platform, we often underestimate just how diverse platforms really are. Did you know the last commercial computer using 9-bit bytes was shut down only 30 years ago? That was the PDP-10—still running when C was dominant, C++ was just emerging (but not yet standardized), Java hadn’t launched (just one year before its release), and Python was still in development (two years before version 1.0). That kind of diversity hasn’t gone away—it’s just shifted. Today: There are 35+ active CPU architecture families: x86/64, Arm, MIPS, RISC-V, Xtensa, TriCore, SPARC, PIC, AVR, and many more Some use unusual instruction widths (e.g., 13-bit for Padauk’s $0.03 MCU) Not all CPUs support floating-point—or even 8-bit operations And beyond the hardware: 15+ actively used IDEs 10+ build systems (CMake, Bazel, Make, etc.) 10+ CI/CD tools Multiple documentation systems (e.g., Doxygen) Dozens of compliance and certification standards (MISRA C++, aerospace, safety, security, etc.) Even if your library is just int sum(int a, int b), complexity sneaks in. You have to think about integration, testing, versioning, documentation—and possibly even certification or safety compliance. Over time, we’ve solved many problems that turned out to be avoidable. Why? Because cross-platform development forces you to explore the strange corners of computing. This article series is our way of sharing those lessons. Why C++? We’re focusing on C++ because: It compiles to native code and runs without a virtual machine (unlike Java) It’s a descendant of C, with a wealth of low-level, highly optimized libraries It builds for almost any architecture—except the most constrained devices, where pure C, mini-C (Padauk), or assembly is preferred That makes it the language of choice for serious cross-platform development—at least on CPUs. We’re skipping GPUs, FPGAs, and low-level peripherals (e.g., GPIO, DMA) for now, as they come with their own portability challenges. Why Not C? C is still a valid choice for embedded and systems development—but modern C++ offers major advantages. C++17 is supported by all major toolchains and improves development by providing: Templates that dramatically reduce boilerplate and code size Compile-time programming (metaprogramming), simplifying toolchains and shifting logic from runtime to compile time Stronger type systems Yes, binary size can increase—but with proper design, it’s manageable. Features like exceptions, RTTI, and STL containers can be selectively disabled or replaced. The productivity and maintainability gains often outweigh the cost, especially when building reusable cross-platform libraries. How to Think About Requirements You can’t build a library that runs everywhere—but you can plan wisely: List all platforms you want to support Choose the smallest subset of toolchains (IDE, build system, CI) that covers most of them Stick with standard ecosystems (e.g., Git + GitHub) for sharing and integration Example: Big-endian support If your library needs to support communication between systems with different endianness (e.g., a little-endian C++ app and a big-endian Java app), it’s better to handle byte order explicitly from the start. Adding byte-swapping now might increase complexity by, say, 3%. But retrofitting it later—especially after deployment—could cost, say, 30% more in refactoring, debugging, and testing. Still, ask: Does this broaden our potential market? Supporting cross-endian interaction makes your library usable in more environments—especially where Java (which uses big-endian formats) is involved. It’s often safer and easier to normalize data on the C++ side than to change byte handling in Java. Requirements Are Multidimensional Even a single feature—like big-endian support—adds complexity to your CI/CD matrix. Cross-platform code must be tested across combinations of: CPU architectures Compilers Toolchains But that’s just the beginning. A typical project spans many other dimensions: Build configurations (debug, release, minimal binary size) Optional modules (e.g., pluggable hash algorithms) Hardware features (e.g., FPU availability) Compile-time flags (e.g., log verbosity, filtering, platform constraints) Business logic flags—often hundreds of #defines Each dimension multiplies the test matrix. The challenge isn’t just making code portable—it’s keeping it maintainable. Supporting a new CPU architecture means expanding your CI/CD infrastructure—especially if using GitHub Actions. Many architectures require local runners, which are harder to manage. Pre-submit tests for such configurations can take tens of minutes per run (see our multi-platform CI config). Compile-time customization increases complexity further. Our config.h in the Aethernet C++ client toggles options like floating-point support, logging verbosity, and platform-specific constraints. Multiply that by eve

When we say cross-platform, we often underestimate just how diverse platforms really are. Did you know the last commercial computer using 9-bit bytes was shut down only 30 years ago? That was the PDP-10—still running when C was dominant, C++ was just emerging (but not yet standardized), Java hadn’t launched (just one year before its release), and Python was still in development (two years before version 1.0).
That kind of diversity hasn’t gone away—it’s just shifted. Today:
- There are 35+ active CPU architecture families: x86/64, Arm, MIPS, RISC-V, Xtensa, TriCore, SPARC, PIC, AVR, and many more
- Some use unusual instruction widths (e.g., 13-bit for Padauk’s $0.03 MCU)
- Not all CPUs support floating-point—or even 8-bit operations
And beyond the hardware:
- 15+ actively used IDEs
- 10+ build systems (CMake, Bazel, Make, etc.)
- 10+ CI/CD tools
- Multiple documentation systems (e.g., Doxygen)
- Dozens of compliance and certification standards (MISRA C++, aerospace, safety, security, etc.)
Even if your library is just int sum(int a, int b), complexity sneaks in. You have to think about integration, testing, versioning, documentation—and possibly even certification or safety compliance.
Over time, we’ve solved many problems that turned out to be avoidable. Why? Because cross-platform development forces you to explore the strange corners of computing. This article series is our way of sharing those lessons.
Why C++?
We’re focusing on C++ because:
- It compiles to native code and runs without a virtual machine (unlike Java)
- It’s a descendant of C, with a wealth of low-level, highly optimized libraries
- It builds for almost any architecture—except the most constrained devices, where pure C, mini-C (Padauk), or assembly is preferred
That makes it the language of choice for serious cross-platform development—at least on CPUs. We’re skipping GPUs, FPGAs, and low-level peripherals (e.g., GPIO, DMA) for now, as they come with their own portability challenges.
Why Not C?
C is still a valid choice for embedded and systems development—but modern C++ offers major advantages. C++17 is supported by all major toolchains and improves development by providing:
- Templates that dramatically reduce boilerplate and code size
- Compile-time programming (metaprogramming), simplifying toolchains and shifting logic from runtime to compile time
- Stronger type systems
Yes, binary size can increase—but with proper design, it’s manageable. Features like exceptions, RTTI, and STL containers can be selectively disabled or replaced. The productivity and maintainability gains often outweigh the cost, especially when building reusable cross-platform libraries.
How to Think About Requirements
You can’t build a library that runs everywhere—but you can plan wisely:
- List all platforms you want to support
- Choose the smallest subset of toolchains (IDE, build system, CI) that covers most of them
- Stick with standard ecosystems (e.g., Git + GitHub) for sharing and integration
Example: Big-endian support
If your library needs to support communication between systems with different endianness (e.g., a little-endian C++ app and a big-endian Java app), it’s better to handle byte order explicitly from the start.
Adding byte-swapping now might increase complexity by, say, 3%. But retrofitting it later—especially after deployment—could cost, say, 30% more in refactoring, debugging, and testing.
Still, ask: Does this broaden our potential market? Supporting cross-endian interaction makes your library usable in more environments—especially where Java (which uses big-endian formats) is involved. It’s often safer and easier to normalize data on the C++ side than to change byte handling in Java.
Requirements Are Multidimensional
Even a single feature—like big-endian support—adds complexity to your CI/CD matrix. Cross-platform code must be tested across combinations of:
- CPU architectures
- Compilers
- Toolchains
But that’s just the beginning. A typical project spans many other dimensions:
- Build configurations (debug, release, minimal binary size)
- Optional modules (e.g., pluggable hash algorithms)
- Hardware features (e.g., FPU availability)
- Compile-time flags (e.g., log verbosity, filtering, platform constraints)
- Business logic flags—often hundreds of
#defines
Each dimension multiplies the test matrix. The challenge isn’t just making code portable—it’s keeping it maintainable.
Supporting a new CPU architecture means expanding your CI/CD infrastructure—especially if using GitHub Actions. Many architectures require local runners, which are harder to manage. Pre-submit tests for such configurations can take tens of minutes per run (see our multi-platform CI config).
Compile-time customization increases complexity further. Our config.h in the Aethernet C++ client toggles options like floating-point support, logging verbosity, and platform-specific constraints. Multiply that by every build configuration and platform, and you get an idea of how quickly things grow.





