![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)
























































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)


























































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


























































































![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)






























































































































Chaos Engineering for Microservices: Resilience Testing with Chaos Toolkit, Chaos Monkey, Kubernetes, and Istio
Introduction As modern applications adopt microservices, Kubernetes, and service meshes like Istio, ensuring resilience becomes a critical challenge in today’s cloud-native world. Distributed architectures introduce new failure modes, requiring proactive resilience testing to achieve high availability. Chaos Engineering enables organizations to identify and mitigate vulnerabilities before they impact production by introducing controlled failures to analyze system behavior and improve reliability. For Java (Spring Boot) and Node.js applications, Chaos Toolkit, Chaos Monkey, and Istio-based fault injection provide robust ways to implement Chaos Engineering. Additionally, Kubernetes-native chaos experiments, such as pod failures, network latency injection, and region-based disruptions, allow teams to evaluate system stability at scale. This document explores how to implement Chaos Engineering in Java, Node.js, Kubernetes, and Istio, focusing on installation, configuration, and experiment execution using Chaos Toolkit and Chaos Monkey. We will also cover Kubernetes and Istio-based failure injection methods to improve resilience across distributed applications and multi-cloud environments. What is Chaos Engineering? Chaos Engineering is a discipline designed to proactively identify weaknesses in distributed systems by simulating real-world failures. The goal is to strengthen application resilience by running controlled experiments that help teams: Simulate the failure of an entire region or data center. Inject latency between services. Max out CPU cores to evaluate performance impact. Simulate file system I/O faults. Test application behavior when dependencies become unavailable. Observe the cascading impact of outages on microservices. By incorporating Chaos Engineering practices, organizations can detect weaknesses before they impact production, reducing downtime and improving system recovery time. Chaos Engineering Lifecycle The process of conducting Chaos Engineering experiments follows a structured lifecycle: Figure 1: The Chaos Engineering Lifecycle: A systematic approach to improving system resilience through continuous experimentation. This lifecycle ensures that failures are introduced methodically and improvements are made continuously. Chaos Toolkit vs. Chaos Monkey: Key Differences Chaos Toolkit and Chaos Monkey are powerful tools in Chaos Engineering, but they have distinct use cases. When to Use Chaos Toolkit? When working with Kubernetes-based deployments. When requiring multi-cloud or multi-language chaos testing. When defining custom failure scenarios for distributed environments. When to Use Chaos Monkey? When testing Spring Boot applications. When needing application-layer failures such as method-level latency and exceptions. When preferring a lightweight, built-in solution for Java-based microservices. Chaos Toolkit: A Versatile Chaos Testing Framework Installation For Java and Node.js applications, install the Chaos Toolkit CLI: pip install chaostoolkit To integrate Kubernetes-based chaos testing: pip install chaostoolkit-kubernetes For Istio-based latency injection: pip install -U chaostoolkit-istio To validate application health using Prometheus: pip install -U chaostoolkit-prometheus Chaos Monkey for Spring Boot The below diagram illustrates how Chaos Monkey for Spring Boot integrates with different components of a Spring Boot application to inject failures and assess resilience. On the left, it shows the key layers of a typical Spring Boot application, including @Controller, @Repository, @Service, and @RestController, which represent the web, business logic, and data access layers. These components are continuously monitored by Chaos Monkey Watchers, which include Controller Watcher, Repository Watcher, Service Watcher, and RestController Watcher. These watchers track activity within their respective layers and enable Chaos Monkey to introduce failures dynamically. On the right, the diagram depicts different types of chaos assaults that can be triggered, such as Latency Assault, which introduces artificial delays in request processing; Exception Assault, which injects random exceptions into methods; and KillApp Assault, which simulates a complete application crash. By leveraging these chaos experiments, teams can validate how well their Spring Boot applications handle unexpected failures and improve system resilience. This visualization helps in understanding the failure injection points within a Spring Boot application and highlights how Chaos Monkey enables fault tolerance testing in real-world scenarios. Figure 2: Chaos Monkey in a Spring Boot Application: Injecting failures at different layers—Controller, Service, Repository—to test resilience. Installation Add the following dependency to your Spring Boot project: de.codecentric ch
Introduction
As modern applications adopt microservices, Kubernetes, and service meshes like Istio, ensuring resilience becomes a critical challenge in today’s cloud-native world. Distributed architectures introduce new failure modes, requiring proactive resilience testing to achieve high availability. Chaos Engineering enables organizations to identify and mitigate vulnerabilities before they impact production by introducing controlled failures to analyze system behavior and improve reliability.
For Java (Spring Boot) and Node.js applications, Chaos Toolkit, Chaos Monkey, and Istio-based fault injection provide robust ways to implement Chaos Engineering. Additionally, Kubernetes-native chaos experiments, such as pod failures, network latency injection, and region-based disruptions, allow teams to evaluate system stability at scale.
This document explores how to implement Chaos Engineering in Java, Node.js, Kubernetes, and Istio, focusing on installation, configuration, and experiment execution using Chaos Toolkit and Chaos Monkey. We will also cover Kubernetes and Istio-based failure injection methods to improve resilience across distributed applications and multi-cloud environments.
What is Chaos Engineering?
Chaos Engineering is a discipline designed to proactively identify weaknesses in distributed systems by simulating real-world failures. The goal is to strengthen application resilience by running controlled experiments that help teams:
- Simulate the failure of an entire region or data center.
- Inject latency between services.
- Max out CPU cores to evaluate performance impact.
- Simulate file system I/O faults.
- Test application behavior when dependencies become unavailable.
- Observe the cascading impact of outages on microservices.
By incorporating Chaos Engineering practices, organizations can detect weaknesses before they impact production, reducing downtime and improving system recovery time.
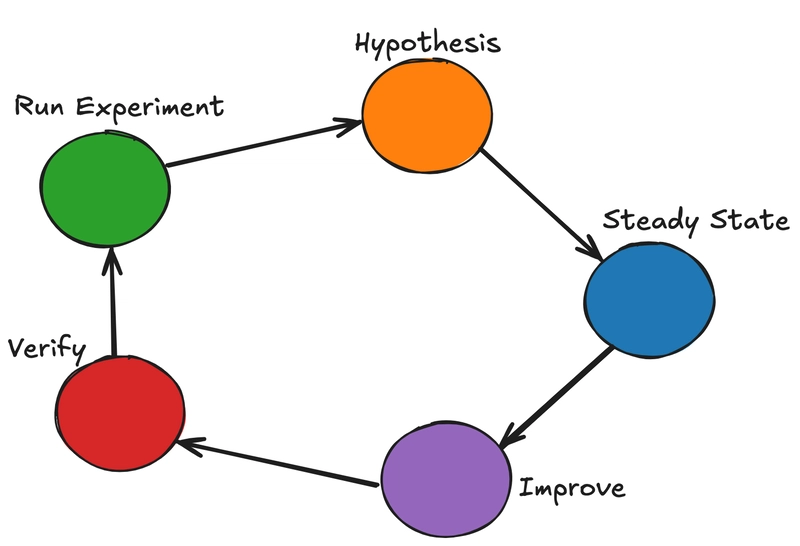
Chaos Engineering Lifecycle
The process of conducting Chaos Engineering experiments follows a structured lifecycle:
Figure 1: The Chaos Engineering Lifecycle: A systematic approach to improving system resilience through continuous experimentation.
This lifecycle ensures that failures are introduced methodically and improvements are made continuously.
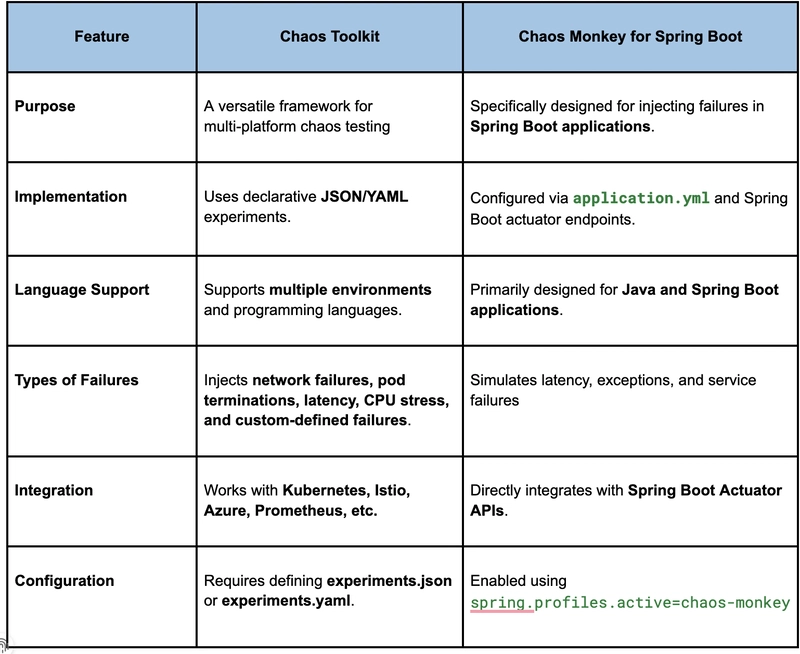
Chaos Toolkit vs. Chaos Monkey: Key Differences
Chaos Toolkit and Chaos Monkey are powerful tools in Chaos Engineering, but they have distinct use cases.
When to Use Chaos Toolkit?
- When working with Kubernetes-based deployments.
- When requiring multi-cloud or multi-language chaos testing.
- When defining custom failure scenarios for distributed environments.
When to Use Chaos Monkey?
- When testing Spring Boot applications.
- When needing application-layer failures such as method-level latency and exceptions.
- When preferring a lightweight, built-in solution for Java-based microservices.
Chaos Toolkit: A Versatile Chaos Testing Framework
Installation
For Java and Node.js applications, install the Chaos Toolkit CLI:
pip install chaostoolkit
To integrate Kubernetes-based chaos testing:
pip install chaostoolkit-kubernetes
For Istio-based latency injection:
pip install -U chaostoolkit-istio
To validate application health using Prometheus:
pip install -U chaostoolkit-prometheus
Chaos Monkey for Spring Boot
The below diagram illustrates how Chaos Monkey for Spring Boot integrates with different components of a Spring Boot application to inject failures and assess resilience. On the left, it shows the key layers of a typical Spring Boot application, including @Controller, @Repository, @Service, and @RestController, which represent the web, business logic, and data access layers. These components are continuously monitored by Chaos Monkey Watchers, which include Controller Watcher, Repository Watcher, Service Watcher, and RestController Watcher. These watchers track activity within their respective layers and enable Chaos Monkey to introduce failures dynamically. On the right, the diagram depicts different types of chaos assaults that can be triggered, such as Latency Assault, which introduces artificial delays in request processing; Exception Assault, which injects random exceptions into methods; and KillApp Assault, which simulates a complete application crash. By leveraging these chaos experiments, teams can validate how well their Spring Boot applications handle unexpected failures and improve system resilience. This visualization helps in understanding the failure injection points within a Spring Boot application and highlights how Chaos Monkey enables fault tolerance testing in real-world scenarios.
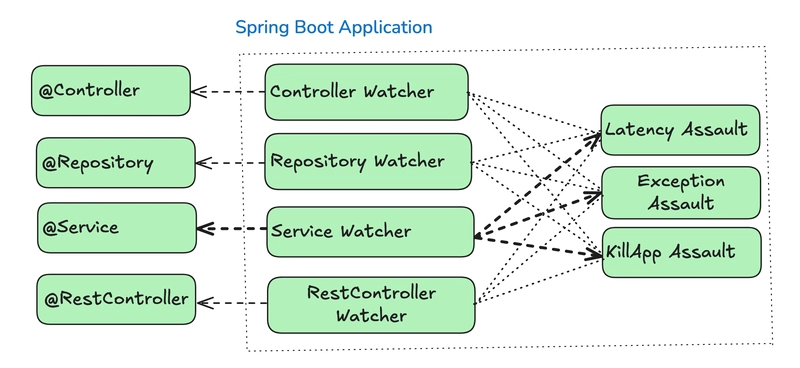
Figure 2: Chaos Monkey in a Spring Boot Application: Injecting failures at different layers—Controller, Service, Repository—to test resilience.
Installation
Add the following dependency to your Spring Boot project:
de.codecentric
chaos-monkey-spring-boot
2.5.4
Enable Chaos Monkey in application.yml:
spring:
profiles:
active: chaos-monkey
chaos:
monkey:
enabled: true
assaults:
level: 3
latency-active: true
latency-range-start: 2000
latency-range-end: 5000
exceptions-active: true
watcher:
controller: true
service: true
repository: true
Running Chaos Monkey in Spring Boot
Start the application with:
mvn spring-boot:run -Dspring.profiles.active=chaos-monkey
To manually enable Chaos Monkey attacks via Spring Boot Actuator endpoints:
curl -X POST
To introduce latency or exceptions, configure assaults dynamically:
curl -X POST http://localhost:8080/actuator/chaosmonkey/assaults \ -H "Content-Type: application/json" \ -d '{ "latencyActive": true, "exceptionsActive": true, "level": 5 }'
Chaos Engineering in Node.js: Implementing Chaos Monkey and Chaos Toolkit
While Chaos Monkey for Spring Boot is widely used for Java applications, Node.js applications can also integrate chaos engineering principles using Chaos Toolkit and Node-specific libraries.
Chaos Monkey for Node.js
For Node.js applications, chaos monkey functionality can be introduced using third-party libraries. The most popular one is:
Chaos Monkey for Node.js (npm package)
Installation for Node.js
To install the Chaos Monkey library for Node.js:
npm install chaos-monkey --save
Basic Usage in a Node.js Application
const express = require("express");
const chaosMonkey = require("chaos-monkey");
const app = express();
app.use(chaosMonkey()); // Injects random failures
app.get("/", (req, res) => {
res.send("Hello, Chaos Monkey!");
});
app.listen(3000, () => {
console.log("App running on port 3000");
});
What does this do?
- Injects random latency delays.
- Throws random exceptions in endpoints.
- Simulates network failures.
Configuring Chaos Monkey for Controlled Experiments in Node.js
To have more control over chaos injection, you can define specific failure types.
Configuring Failure Injection
Modify chaosMonkey.config.js:
module.exports = {
latency: {
enabled: true,
minMs: 500,
maxMs: 3000,
},
exceptions: {
enabled: true,
probability: 0.2, // 20% chance of exception
},
killProcess: {
enabled: false, // Prevents killing the process
},
};
Now, modify the server.js file to load the configuration:
const express = require("express");
const chaosMonkey = require("chaos-monkey");
const config = require("./chaosMonkey.config");
const app = express();
app.use(chaosMonkey(config)); // Inject failures based on configuration
app.get("/", (req, res) => {
res.send("Chaos Engineering in Node.js is running!");
});
app.listen(3000, () => {
console.log("App running on port 3000 with Chaos Monkey");
});
Chaos Toolkit for Node.js Applications
Similar to Kubernetes and Java applications, Chaos Toolkit can be used to inject failures into Node.js services.
Example: Latency Injection for Node.js using Chaos Toolkit
This Chaos Toolkit experiment will introduce latency into a Node.js service.
{
"title": "Introduce artificial latency in Node.js service",
"description": "Test how the Node.js API handles slow responses.",
"method": [
{
"type": "action",
"name": "introduce-latency",
"provider": {
"type": "process",
"path": "curl",
"arguments": [
"-X",
"POST",
"http://localhost:3000/chaosmonkey/enable-latency"
]
}
}
],
"rollbacks": [
{
"type": "action",
"name": "remove-latency",
"provider": {
"type": "process",
"path": "curl",
"arguments": [
"-X",
"POST",
"http://localhost:3000/chaosmonkey/disable-latency"
]
}
}
]
}
To execute and report the experiment:
chaos run node-latency-experiment.json --journal-path=node-latency-journal.json
chaos report --export-format=json node-latency-journal.json > node-latency-report.json
Chaos Experiments in Multi-Cloud and Kubernetes Environments
For microservices deployed on Kubernetes or multi-cloud platforms, Chaos Toolkit provides a more robust way to perform failover testing.
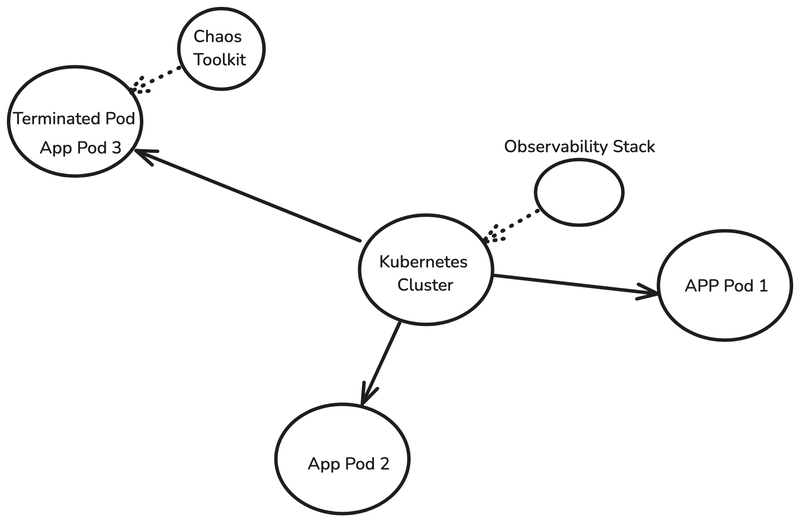
Figure 3: Chaos Toolkit Experiment Execution Flow: A structured approach to injecting failures and observing system behavior.
For microservices deployed on Kubernetes or multi-cloud platforms, Chaos Toolkit provides a more robust way to perform failover testing.
A pod-kill experiment to test application resilience in Kubernetes:
{
"version": "1.0.0",
"title": "System Resilience to Pod Failures",
"description": "Can the system survive a pod failure?",
"configuration": {
"app_name": { "type": "env", "key": "APP_NAME" },
"namespace": { "type": "env", "key": "NAMESPACE" }
},
"steady-state-hypothesis": {
"title": "Application must be up and healthy",
"probes": [{
"name": "check-application-health",
"type": "probe",
"provider": {
"type": "http",
"url": "http://myapp.com/health",
"method": "GET"
}
}]
},
"method": [{
"type": "action",
"name": "terminate-pod",
"provider": {
"type": "python",
"module": "chaosk8s.pod.actions",
"func": "terminate_pods",
"arguments": {
"label_selector": "app=${app_name}",
"ns": "${namespace}",
"rand": true,
"mode": "fixed",
"qty": 1
}
}
}]
}
Running the Chaos Experiment
To execute the experiment, run:
chaos run pod-kill-experiment.json --journal-path=pod-kill-experiment-journal.json
To Generate report after execution:
chaos report --export-format=html pod-kill-experiment-journal.json > pod-kill-experiment-report.html
Rolling Back the Experiment (if necessary):
chaos rollback pod-kill-experiment.json
Example: Region Delay Experiment (Kubernetes & Istio)
This experiment injects network latency into requests by modifying Istio’s virtual service.
version: "1.0.0"
title: "Region Delay Experiment"
description: "Simulating high latency in a specific region"
method:
- type: action
name: "inject-fault"
provider:
type: python
module: chaosistio.fault.actions
func: add_delay_fault
arguments:
virtual_service_name: "my-service-vs"
fixed_delay: "5s"
percentage: 100
ns: "default"
pauses:
before: 5
after: 20
rollbacks:
- type: action
name: "remove-fault"
provider:
type: python
module: chaosistio.fault.actions
func: remove_delay_fault
arguments:
virtual_service_name: "my-service-vs"
ns: "default"
To execute:
chaos run region-delay-experiment.yaml --journal-path=region-delay-journal.json
Generate a detailed report:
chaos report --export-format=html region-delay-journal.json > region-delay-report.html
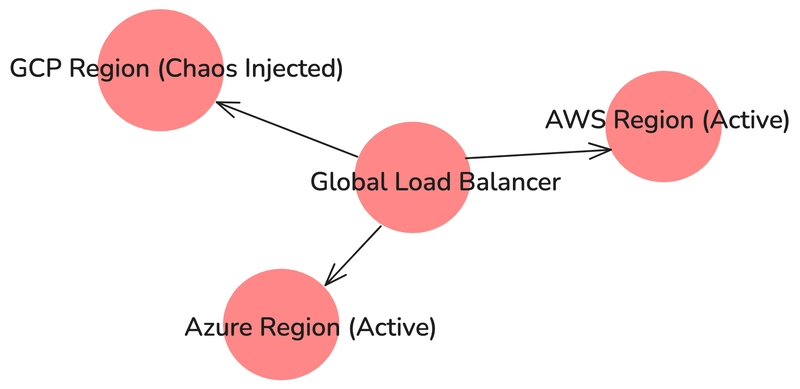
Figure 4: Multi-Cloud Chaos Engineering: Simulating cloud-region failures across AWS, Azure, and GCP using a global load balancer.
More Chaos Toolkit Scenarios
In addition to basic pod failures and latency injection, Chaos Toolkit can simulate more complex failure scenarios:
- Injecting Memory/CPU Stress in Kubernetes Pods - Test how applications behave under high CPU or memory consumption.
- Shutting Down a Database Instance - Simulate a database failure to verify if the system can handle database outages gracefully.
- Network Partitioning Between Services - Introduce network partitions to analyze the impact on microservices communication.
- Scaling Down an Entire Service - Reduce the number of available replicas of a service to test auto-scaling mechanisms.
- Time-based Failures - Simulate failures only during peak traffic hours to observe resilience under load.
These real-world scenarios help identify weak points in distributed architectures and improve recovery strategies.
Integrating Chaos Engineering into CI/CD Pipelines
To ensure resilience testing becomes an integral part of the software development lifecycle, organizations should automate chaos experiments within CI/CD pipelines. This allows failures to be introduced in a controlled manner before production deployment, reducing the risk of unexpected outages.
Why Integrate Chaos Testing into CI/CD?
- Automates resilience validation as part of deployment.
- Identifies performance bottlenecks before changes reach production.
- Ensures services can recover from failures without manual intervention.
- Improves Mean Time to Recovery (MTTR) by simulating real-world issues.
Chaos Engineering in CI/CD Workflow
A typical CI/CD-integrated Chaos Testing workflow follows these steps:
- Developer Commits Code → Code changes are pushed to the repository.
- CI/CD Pipeline Triggers Build & Deploy → The application is built and deployed to Kubernetes.
- Run Chaos Experiments → Automated chaos testing is executed after deployment.
- Observability & Monitoring → Prometheus, Datadog, and logs collect system behavior metrics.
- Verify System Resilience → If service health checks pass, the deployment proceeds.
- Rollback if Needed → If the system fails resilience thresholds, auto-rollback is triggered.
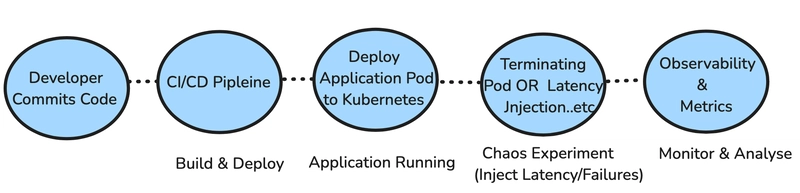
Figure 5: Integrating Chaos Engineering into CI/CD: Automating resilience testing with Kubernetes and Istio.
Example: Automating Chaos Testing in GitHub Actions
Below is an example of how you can automate Chaos Toolkit experiments in a GitHub Actions CI/CD pipeline:
name: Chaos Testing Pipeline
on:
push:
branches:
- main
jobs:
chaos-test:
runs-on: ubuntu-latest
steps:
- name: Checkout Code
uses: actions/checkout@v2
- name: Install Chaos Toolkit
run: pip install chaostoolkit
- name: Run Chaos Experiment
run: chaos run pod-kill-experiment.json
- name: Validate Recovery
run: curl -f http://myapp.com/health || exit 1
Key Steps Explained:
- The pipeline triggers on code push events.
- The Chaos Toolkit is installed dynamically.
- The pod-kill experiment is executed against the deployed application.
- A health check ensures the application recovers from the failure.
- If the health check fails, the pipeline halts the deployment to avoid releasing unstable code.
Validating Results After Running Chaos Experiments
After executing chaos experiments, it’s essential to validate system performance. The chaos report command generates detailed experiment reports:
chaos report --export-format=html /app/reports/chaos_experiment_journal.json /app/reports/chaos_experiment_summary.html
How to analyze results?
- If the system maintains a steady state → The service is resilient.
- If anomalies are detected → Logs, monitoring tools, and alerting mechanisms should be used for debugging.
- If failure cascades occur → Adjust service design, introduce circuit breakers, or optimize auto-scaling policies.
Best Practices for Running Chaos Experiments
- Start with a Steady-State Hypothesis → Define what a "healthy" system looks like before introducing chaos.
- Begin with Low-Level Failures → Start with 100ms latency injection before increasing failure severity.
- Monitor System Metrics → Use Grafana & Prometheus dashboards to track failure impact.
- Enable Auto-Rollbacks → Ensure failures are reverted automatically after an experiment.
- Gradually Increase Chaos Level → Use controlled chaos before introducing large-scale failures.
Conclusion
Chaos Engineering is a critical practice in today’s cloud-native, Kubernetes, and service mesh-based environments. Whether you're working with Java (Spring Boot), Node.js, Kubernetes, or Istio, you can leverage:
- Chaos Monkey for lightweight failure injection within Spring Boot applications.
- Chaos Toolkit for complex failure scenarios across Kubernetes, Istio, and multi-cloud environments.
- Kubernetes and Istio Chaos Experiments to validate failover strategies, latency handling, and pod resilience.
- Service mesh-based network disruptions to simulate cross-region and intra-cluster failures.
By systematically injecting failures at the application, network, and infrastructure layers, teams can proactively improve system resilience. Kubernetes and Istio offer powerful tools for injecting latency, network disruptions, and pod failures to evaluate service stability. Integrating Chaos Engineering into CI/CD pipelines ensures automated resilience testing across multi-cloud deployments.
Next Steps
- Integrate Chaos Monkey and Chaos Toolkit into your development workflow.
- Automate chaos experiments using CI/CD pipelines (GitHub Actions, Jenkins, Azure Devops).
- Explore Kubernetes-native failure injection techniques.
- Use Istio traffic management to validate multi-region and network fault tolerance.
By embracing Chaos Engineering as a continuous discipline, organizations can build fault-tolerant, highly available systems that withstand unexpected failures in production.
Happy Chaos Engineering!
References
To further explore Chaos Engineering principles, tools, and best practices, refer to the following resources:
- Principles of Chaos Engineering – A detailed explanation of the core principles and methodologies of Chaos Engineering.
- Chaos Monkey for Spring Boot Documentation – A guide to implementing Chaos Monkey for Spring Boot applications.
- Spring Boot Actuator Reference – Official documentation for Spring Boot Actuator, used for Chaos Monkey experiments.
- Chaos Monkey for Node.js (NPM Package) – Node.js library for injecting failures.
- Chaos Toolkit Official Documentation – The official guide to installing and using Chaos Toolkit.
- Chaos Toolkit GitHub Repository – Source code and contributions to Chaos Toolkit.
- Chaos Toolkit Kubernetes Integration – Guide to injecting failures in Kubernetes clusters.
Originally published at https://dzone.com.