![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)












































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)







































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)







































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

























































































![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)
































































































































Breaking Down AI Buzzwords: A Developer’s Guide to Understanding the Basics
Hey there, developers! AI is absolutely everywhere these days, right? And let's be honest, so is the jargon: tokenization, embeddings, self-attention... it's enough to make your head spin! If you've ever found yourself nodding along in a meeting while secretly wondering what these terms really mean, trust me, you're not alone. I've been there too. That's why I wrote this post. My goal is to break down some of the most common AI buzzwords you'll encounter, especially in Large Language Models (LLMs), using plain language. Forget the dense academic papers and overwhelming math for now – we're focusing on simple explanations to help you grasp how these concepts work and why they actually matter in the models we use. Ready to make sense of the AI hype together? Let's dive in! Tokenization: Chopping Up Language First things first: before any AI model can even begin to understand text, it needs to break it down into smaller, manageable pieces. This crucial first step is called tokenization. What's it really doing? Think of it like slicing a loaf of bread before you can make sandwiches. You take a whole sentence (the loaf) and chop it into smaller bits – words or even parts of words (the slices). These pieces are called "tokens." For example, the sentence "Hello, world!" might get tokenized into something like: [Hello] [ , ] [world] [ ! ] Why bother? Because computers don't speak English, French, or Hindi – they speak the language of numbers. Tokenization is the bridge. Each token gets assigned a numerical ID, turning language into a format the machine can actually perform calculations on. A Simple Analogy: I found it helpful to think of reading a complex recipe. You don't tackle it all at once; you break it down ingredient by ingredient, step by step. Tokenization does this for language, making it digestible for the AI. Key Things to Remember about Tokenization: Vocab Size Matters: Every model has a pre-defined "vocabulary" – a list of all the unique tokens it recognizes. This might include letters (A-Z, a-z), numbers (0-9), punctuation, common words, or subwords. If a model's vocab size is, say, 50,000, it knows 50,000 unique pieces it can represent numerically. Different Models, Different Strategies: Some models tokenize purely by words ([Hello], [world]). Others use "subword" tokenization, which is really clever. It can break down unknown or long words into smaller known parts, like tokenizing "Unbelievable" into [Un] [believ] [able]. This helps handle new words without needing an infinitely large vocabulary. Why should you care? Tokenization is the absolute foundation. Without it, text remains meaningless squiggles to an AI. It's the essential first step in turning human language into something a machine can process and learn from. Vector Embeddings: Giving Words Mathematical Meaning So, we've chopped our text into tokens and given each a number. But those numbers are just IDs – they don't capture the meaning or context of the token. That's where the magic of vector embeddings comes in. What are they, exactly? Imagine giving each word (or token) a rich, multi-faceted mathematical identity. Instead of just one ID number, each token gets mapped to a vector – basically, a list of numbers (often hundreds of them!). This vector isn't random; it's carefully calculated to represent the token's meaning and its relationships to other tokens. Why vectors? Because while machines don't understand "king" or "queen," they excel at comparing lists of numbers. Embeddings translate semantic meaning into a format computers can work with. Think of it like this: You're plotting concepts on a complex, multi-dimensional map. Each concept (token) gets coordinates (its vector). Crucially, concepts with similar meanings ("king," "queen," "monarch") end up close together on this map. This proximity represents semantic similarity. How do they capture meaning? Tokens to Vectors: Every token from the vocabulary gets its own unique vector. For instance (simplified!): "King" → [1.2, 3.4, -0.8, ...] "Queen" → [1.1, 3.5, -0.7, ...] Semantic Relationships: These vectors are learned in a way that captures relationships. A famous example is that the vector math vector("King") - vector("Man") + vector("Woman") often results in a vector very close to vector("Queen"). This shows the model has learned gender and royalty relationships! Finding Similarities: Because similar concepts cluster together, the model can find related ideas just by looking for vectors that are "close" in this mathematical space. "Cat" will be nearer to "dog" than to "car." Why are embeddings so important? Vector embeddings are critical for AI to: Grasp relationships between words (synonyms, analogies, concepts). Power recommendation systems (finding "similar" items). Understand context and nuance far beyond simple keyword matching. Without embeddings, AI would struggle to understand the rich tape

Hey there, developers!
AI is absolutely everywhere these days, right? And let's be honest, so is the jargon: tokenization, embeddings, self-attention... it's enough to make your head spin! If you've ever found yourself nodding along in a meeting while secretly wondering what these terms really mean, trust me, you're not alone. I've been there too.
That's why I wrote this post. My goal is to break down some of the most common AI buzzwords you'll encounter, especially in Large Language Models (LLMs), using plain language. Forget the dense academic papers and overwhelming math for now – we're focusing on simple explanations to help you grasp how these concepts work and why they actually matter in the models we use.
Ready to make sense of the AI hype together? Let's dive in!
Tokenization: Chopping Up Language
First things first: before any AI model can even begin to understand text, it needs to break it down into smaller, manageable pieces. This crucial first step is called tokenization.
What's it really doing?
Think of it like slicing a loaf of bread before you can make sandwiches. You take a whole sentence (the loaf) and chop it into smaller bits – words or even parts of words (the slices). These pieces are called "tokens."
For example, the sentence "Hello, world!" might get tokenized into something like:
[Hello] [ , ] [world] [ ! ]
Why bother? Because computers don't speak English, French, or Hindi – they speak the language of numbers. Tokenization is the bridge. Each token gets assigned a numerical ID, turning language into a format the machine can actually perform calculations on.
- A Simple Analogy: I found it helpful to think of reading a complex recipe. You don't tackle it all at once; you break it down ingredient by ingredient, step by step. Tokenization does this for language, making it digestible for the AI.
Key Things to Remember about Tokenization:
- Vocab Size Matters: Every model has a pre-defined "vocabulary" – a list of all the unique tokens it recognizes. This might include letters (A-Z, a-z), numbers (0-9), punctuation, common words, or subwords. If a model's vocab size is, say, 50,000, it knows 50,000 unique pieces it can represent numerically.
- Different Models, Different Strategies: Some models tokenize purely by words (
[Hello],[world]). Others use "subword" tokenization, which is really clever. It can break down unknown or long words into smaller known parts, like tokenizing "Unbelievable" into[Un] [believ] [able]. This helps handle new words without needing an infinitely large vocabulary.
Why should you care?
Tokenization is the absolute foundation. Without it, text remains meaningless squiggles to an AI. It's the essential first step in turning human language into something a machine can process and learn from.
Vector Embeddings: Giving Words Mathematical Meaning
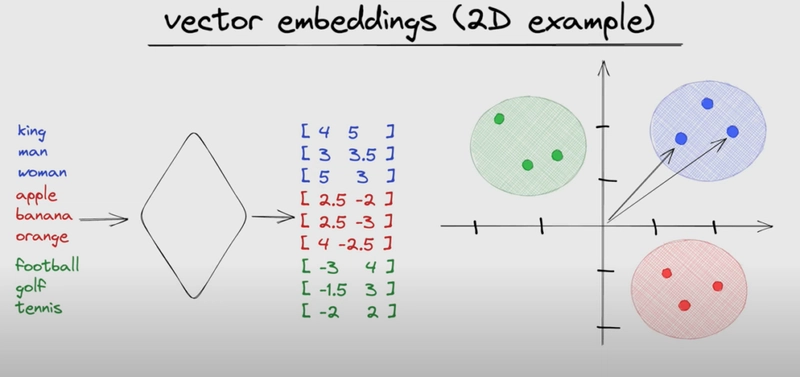
So, we've chopped our text into tokens and given each a number. But those numbers are just IDs – they don't capture the meaning or context of the token. That's where the magic of vector embeddings comes in.
What are they, exactly?
Imagine giving each word (or token) a rich, multi-faceted mathematical identity. Instead of just one ID number, each token gets mapped to a vector – basically, a list of numbers (often hundreds of them!). This vector isn't random; it's carefully calculated to represent the token's meaning and its relationships to other tokens.
Why vectors? Because while machines don't understand "king" or "queen," they excel at comparing lists of numbers. Embeddings translate semantic meaning into a format computers can work with.
- Think of it like this: You're plotting concepts on a complex, multi-dimensional map. Each concept (token) gets coordinates (its vector). Crucially, concepts with similar meanings ("king," "queen," "monarch") end up close together on this map. This proximity represents semantic similarity.
How do they capture meaning?
- Tokens to Vectors: Every token from the vocabulary gets its own unique vector. For instance (simplified!):
-
"King" →
[1.2, 3.4, -0.8, ...] -
"Queen" →
[1.1, 3.5, -0.7, ...]
-
"King" →
- Semantic Relationships: These vectors are learned in a way that captures relationships. A famous example is that the vector math
vector("King") - vector("Man") + vector("Woman")often results in a vector very close tovector("Queen"). This shows the model has learned gender and royalty relationships! - Finding Similarities: Because similar concepts cluster together, the model can find related ideas just by looking for vectors that are "close" in this mathematical space. "Cat" will be nearer to "dog" than to "car."
Why are embeddings so important?
Vector embeddings are critical for AI to:
- Grasp relationships between words (synonyms, analogies, concepts).
- Power recommendation systems (finding "similar" items).
- Understand context and nuance far beyond simple keyword matching.
Without embeddings, AI would struggle to understand the rich tapestry of meaning woven into human language. They are the secret sauce for capturing semantics.
Positional Encoding: Keeping Track of Word Order
Okay, we have meaningful vectors for our tokens. But there's a big problem, especially for newer models like Transformers: they look at all the tokens in a sentence simultaneously. This is great for speed, but it means they might lose track of the original word order.
Consider "The cat chased the dog" vs. "The dog chased the cat." Same tokens, same embeddings, but completely different meanings! How do we solve this? Enter positional encoding.
What is it?
Positional encoding is a clever trick to inject information about a token's position in the sequence directly into its embedding. It modifies the token's vector slightly, giving the model a signal about where that token appeared (first, second, third, etc.).
- Analogy Time: Imagine numbering the books on your shelf. Even if you pull them all off, the numbers tell you how to put them back in the correct order. Positional encoding gives each token's vector a unique "position number" or signal.
How does it work (conceptually)?
- Adding Positional Info: A unique positional value (itself a vector, often generated using sine and cosine functions of different frequencies) is added to each token's embedding vector.
- Token Embedding + Positional Vector = Combined Embedding
- Unique Signal for Each Position: The mathematical functions used ensure that each position (1st, 2nd, 3rd...) gets a distinct positional vector pattern that the model can learn to recognize.
- Preserving Order: Now, even though the model processes tokens in parallel, the combined embeddings contain the necessary clues to understand the original sequence and differentiate "cat chased dog" from "dog chased cat."
Why is this necessary?
Older models like RNNs processed words one by one, inherently keeping track of order. Transformers, by processing tokens in parallel for speed and capturing long-range dependencies better, lose this built-in sequential awareness. Positional encoding adds it back explicitly. It's like giving the Transformer a GPS for the sentence structure. Without it, meaning derived from word order would be lost.
Self-Attention: Understanding Context Within a Sentence
How do you understand the meaning of "bank" in "The bank is near the river" versus "I need to go to the bank to deposit this check"? You use context – the surrounding words. Self-attention is the mechanism that allows AI models, particularly Transformers, to do the same thing.
What is Self-Attention?
It's a process that lets the model weigh the importance of all other tokens in the input sequence when processing a specific token. Instead of looking at words in isolation, the model "attends" to the relationships between them to better understand the context-dependent meaning.
- A Human Parallel: Think of a group discussion. When someone says a potentially ambiguous word like "address," you pay attention to the rest of their sentence ("Do you need my home address?" vs. "How should I address this issue?") to get the real meaning. Self-attention lets the model do this internal "listening" across the sentence.
How does it work (the gist)?
- Token Interactions: For every single token, the model calculates an "attention score" between it and every other token (including itself) in the sequence. This score represents how relevant token B is for understanding token A in this specific context.
- Calculating Weighted Importance: High scores mean strong relevance, low scores mean weak relevance. For "The bank is near the river," the token "river" would likely get a high attention score when the model processes "bank."
- Refining Embeddings: The model then recalculates each token's embedding by creating a weighted sum of all tokens' embeddings, guided by these attention scores. This means the final representation of "bank" is heavily influenced by the representation of "river," helping it resolve ambiguity.
Why is this a game-changer?
Language is slippery! Words change meaning based on context. Self-attention gives models the power to:
- Disambiguate words: Understand "bank" (river) vs. "bank" (financial).
- Understand relationships: Figure out what pronouns like "it" or "they" refer to earlier in the text.
- Grasp the holistic meaning of a sentence rather than just processing word-by-word.
It's fundamental to how modern AI truly understands language nuances.
Multi-Head Attention: Looking at Context from Multiple Angles
Self-attention is powerful, letting tokens consider context. But what if one perspective isn't enough? What if different types of relationships are important? That's the idea behind multi-head attention.
What is it?
Instead of calculating attention just once, multi-head attention performs the self-attention process multiple times in parallel, using different, learned "perspectives" or "heads." Each head can potentially focus on different aspects of the relationships between tokens.
- Analogy Upgrade: Remember the group meeting analogy for self-attention? Multi-head attention is like having multiple subgroups in that meeting, each analyzing the project from a specific angle (budget, timeline, resources, technical feasibility). Afterwards, they combine their findings for a much richer, comprehensive understanding.
How does it enhance self-attention?
- Splitting and Projecting: The original token embeddings are split and transformed (projected) differently for each "head."
- Parallel Attention: Each head performs the self-attention calculation independently on its transformed version of the embeddings. This allows different heads to learn to focus on different things:
- One head might capture subject-verb relationships.
- Another might focus on how adjectives modify nouns.
- A third might track long-distance dependencies.
- Combining the Insights: The outputs from all the attention heads are combined (concatenated and projected again) to produce the final output for that layer. This final representation benefits from the diverse perspectives captured by the individual heads.
Why bother with multiple heads?
Language is complex! A single attention mechanism might latch onto the most obvious relationship but miss others. Multi-head attention allows the model to simultaneously consider various types of syntactic and semantic relationships, leading to a deeper and more robust understanding of the input text. It's a key ingredient in the success of powerful models like Transformers for tasks demanding nuanced understanding (translation, summarization, etc.).
Transformers: The Architecture Powering Modern AI
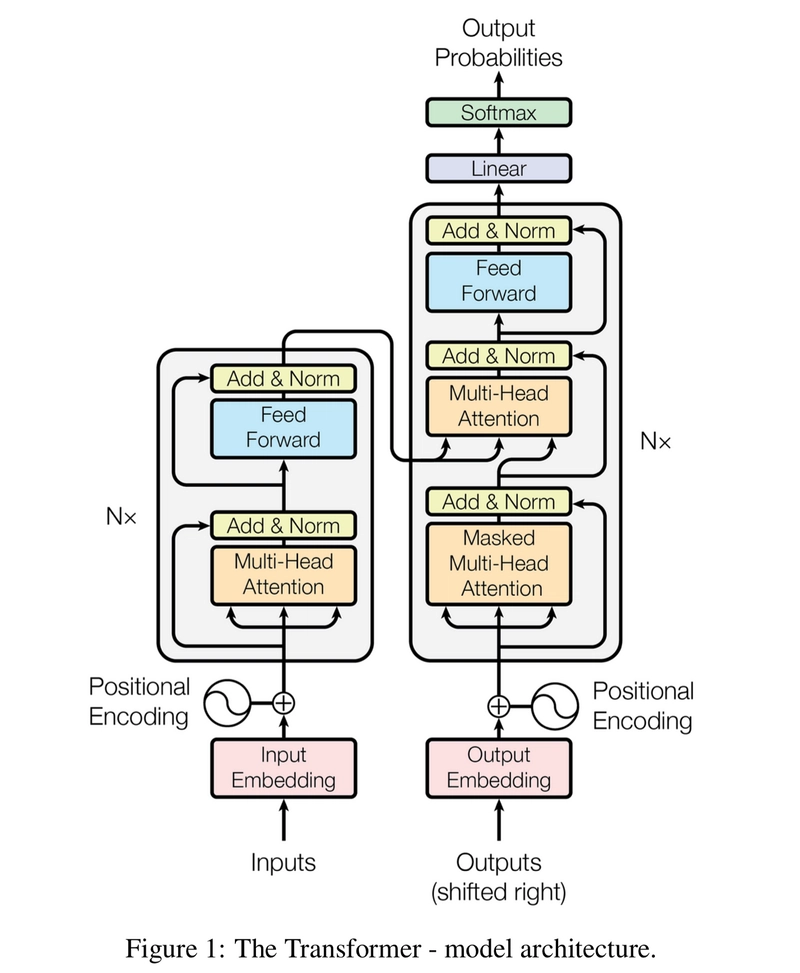
You've likely heard of ChatGPT, BERT, Google Translate, DALL·E... These incredible AI systems often have one thing in common under the hood: the Transformer architecture. Introduced in the seminal paper "Attention Is All You Need," Transformers revolutionized how we process sequential data, especially language.
What is a Transformer?
It's a specific type of neural network architecture designed primarily for sequence-to-sequence tasks (like translation or summarization). Its defining characteristics are:
Parallel Processing: Unlike older models (RNNs/LSTMs) that process sequences word-by-word, Transformers can process all tokens in a sequence simultaneously.
Attention Mechanisms: They heavily rely on self-attention and multi-head attention (which we just discussed!) to understand context and relationships between tokens, regardless of their distance in the sequence.
Positional Encoding: They use positional encodings to keep track of word order, compensating for the parallel processing.
The Big Picture: Think of a Transformer as a highly efficient information processing pipeline, built specifically to leverage attention mechanisms for understanding complex dependencies in data like text.
Core Components Often Include:
- Input Processing: Tokenization, embedding generation, and adding positional encoding.
- Encoder: A stack of layers (often including multi-head attention and feed-forward networks) that processes the input sequence and builds a rich, context-aware representation.
- Decoder: Another stack of layers that takes the encoder's output and generates the target sequence (e.g., the translated sentence), also using attention mechanisms. (More on this next!)
Why are Transformers so dominant?
- Efficiency & Speed: Parallel processing makes them much faster to train on modern hardware (GPUs/TPUs) compared to sequential RNNs.
- Superior Context Handling: Self-attention excels at capturing long-range dependencies (connecting words far apart in a text) which was a struggle for older models.
- Scalability: They scale remarkably well with more data and larger model sizes, leading to increasingly powerful AI capabilities.
Transformers are the backbone of much of the current AI revolution in natural language processing and beyond.
Encoder and Decoder: The Two Halves of Many Transformers
Many Transformer models, especially those used for tasks like machine translation or summarization, consist of two main parts working in tandem: the encoder and the decoder.
What do they do?
- The Encoder: Its job is to understand the input sequence. It reads the entire input sentence (e.g., English text), uses layers of self-attention to build a rich internal representation that captures the meaning and context, and outputs this representation. Think of it as creating a detailed summary or "meaning vector" of the input.
- The Decoder: Its job is to generate the output sequence (e.g., the French translation). It takes the encoder's output (the meaning vector) and, typically one token at a time, generates the target sentence. Crucially, the decoder also uses attention mechanisms:
- Self-attention on the words it has already generated, to maintain coherence.
- Cross-attention looking back at the encoder's output, to ensure the generated output stays true to the original input's meaning.
- A Communication Analogy: Imagine translating a message. The encoder is like carefully reading and fully understanding the original message in English. The decoder is then taking that deep understanding and carefully crafting the message word-by-word in French, constantly referring back to the original meaning.
Why the split?
This separation of concerns is powerful:
- The encoder can focus entirely on deeply understanding the source material.
- The decoder can focus entirely on generating fluent and accurate target output, guided by the encoder's understanding.
Note: Not all Transformers have both. Models focused purely on understanding (like BERT) might primarily use the encoder part, while models focused purely on generation (like GPT) might primarily use the decoder part, often pre-trained without a specific encoder input for generation tasks.
Softmax: Making the Final Choice
When an AI model needs to predict the next word in a sentence or classify something, it usually ends up with a bunch of raw scores (called "logits") for each possible option. But how does it turn those scores into a single, confident choice? That's often the job of the softmax function.
What does Softmax do?
Softmax is a mathematical function that takes a list of raw scores and converts them into a list of probabilities that all add up to 1 (or 100%). It essentially highlights the most likely option while still giving some probability to less likely ones.
For example, predicting the next word after "How are you...":
- Raw scores (logits):
{"doing": 3.1, "feeling": 2.5, "today": 1.0} - Softmax output (probabilities):
{"doing": 0.65, "feeling": 0.30, "today": 0.05}(approx.)
The model would then typically choose "doing" as the next word because it has the highest probability (65%).
- Voting Analogy: Think of it like vote counts in an election. The raw scores are the initial tallies. Softmax converts these into percentages of the total vote, making it clear who the winner is, but also showing the support for other candidates.
The Key Steps (Simplified):
- Exponentiate: It makes all scores positive and emphasizes the higher scores (e^score).
- Normalize: It divides each exponentiated score by the sum of all exponentiated scores, ensuring the results sum to 1.
Why is Softmax used?
- Interpretability: Turns arbitrary scores into meaningful probabilities.
- Decision Making: Provides a clear basis for choosing the most likely output.
- Training: It's mathematically convenient for training models using methods like cross-entropy loss.
Softmax is the standard way models often convert internal calculations into final predictions or choices.
Temperature: Dialing Up the AI's Creativity
When using generative AI, you might notice you can sometimes adjust a setting called temperature. This parameter directly influences how the model uses the probabilities generated by softmax (or a similar process) when picking the next word. It controls the randomness or "creativity" of the output.
What is Temperature?
Temperature is a scaling factor applied to the logits before they go into the softmax function.
Low Temperature (e.g., < 1.0, like 0.2): Dividing logits by a small number makes the differences between scores larger. This makes the softmax probability distribution sharper, meaning the model becomes more confident, more focused, and more likely to pick the absolute highest-probability word. The output becomes predictable, deterministic, and sometimes repetitive.
High Temperature (e.g., > 1.0, like 1.2): Dividing logits by a larger number makes the differences between scores smaller. This flattens the softmax distribution, meaning probabilities are spread more evenly across different words. The model becomes less confident, more adventurous, more random, and more likely to pick less common words. The output becomes more surprising, diverse, and creative – but also potentially less coherent or relevant.
Temperature = 1.0: This is the default, using the original softmax probabilities without modification.
Creativity Thermostat Analogy: Low temp is like sticking strictly to the recipe – safe and predictable. High temp is like improvising in the kitchen – more experimental, potentially brilliant, potentially disastrous!
Why control Temperature?
It allows you to tailor the AI's output style:
- Use low temperature for tasks needing accuracy and consistency (e.g., factual summarization, code generation based on strict rules).
- Use high temperature for tasks benefiting from creativity and diversity (e.g., brainstorming ideas, writing poetry, creating varied chatbot responses).
Temperature gives you a knob to turn, balancing between predictable coherence and creative exploration.
Vocab Size: The AI's Word Dictionary
We mentioned vocabularies back when discussing tokenization. The vocab size is simply the total number of unique tokens defined in that vocabulary. This number has significant implications for the model's performance and efficiency.
What determines Vocab Size?
It's determined during the tokenization setup phase, based on the training data and the chosen tokenization strategy (word, subword, character).
A model using character-level tokenization might have a tiny vocab size (e.g., ~100 for English letters, numbers, punctuation).
A model using word-level tokenization needs a huge vocab size (tens or hundreds of thousands) to cover most words.
Subword tokenization (like BPE or WordPiece used in many modern LLMs) offers a balance, typically having vocab sizes in the tens of thousands (e.g., 30k - 100k). It can represent common words as single tokens but break down rarer words into known subword pieces.
Dictionary Analogy: Vocab size is like the number of entries in the dictionary the AI carries. More entries mean it recognizes more words directly, but the dictionary gets heavier.
The Trade-offs:
-
Small Vocab (e.g., Characters):
- Pros: Can represent any text, handles typos/new words gracefully. Smaller model embedding layer.
- Cons: Sentences become very long sequences of tokens, potentially harder for the model to capture long-range meaning. Less semantically meaningful units.
-
Large Vocab (e.g., Words):
- Pros: Shorter sequences, tokens are semantically meaningful.
- Cons: Struggles with unknown words ("out-of-vocabulary" problem). Requires huge memory for the embedding layer.
-
Medium Vocab (e.g., Subwords):
- Pros: Good balance. Handles rare words by breaking them down. Keeps sequences reasonably short. Most common approach now.
- Cons: Tokenization itself is more complex. Tokens might not always align with intuitive word boundaries.
Why does it matter?
Vocab size directly impacts the model's size, speed, memory usage, and its ability to handle diverse text. It's a fundamental design choice in building an AI model.
Knowledge Cutoff: The AI's "Last Studied" Date
Ever asked an AI about a very recent event and gotten a vague answer or information that's clearly outdated? This happens because of the knowledge cutoff.
What is it?
The knowledge cutoff is simply the point in time when the data used to train the AI model was collected. The model generally cannot "know" about events, discoveries, or information that emerged after this date because it wasn't part of its learning material.
- Exam Analogy: Imagine studying for a history exam using only textbooks published up to the year 2020. Your knowledge would be "cut off" at 2020; you wouldn't know about major events from 2021 unless you got an updated textbook (or the model is retrained/updated).
Why does it exist?
- Training is Finite: Training these massive models takes enormous resources (data, computation, time). The process has to stop at some point to actually release and use the model.
- Static Models: Once trained, most large models don't continuously learn from the live internet (though some systems might integrate web search results post-generation). Their core knowledge remains fixed until a significant retraining effort occurs.
What's the Impact?
- Outdated Info: Be critical! AI responses about rapidly evolving topics (current events, latest tech, recent pop culture) might be inaccurate if the event happened after the cutoff.
- Reliability Varies: For stable knowledge (math principles, historical facts before the cutoff, core programming concepts), the cutoff is less relevant. For dynamic knowledge, it's crucial to be aware of.
Always check or ask for the model's knowledge cutoff date if you need up-to-the-minute information!
Wrapping Up
Phew, that was a lot! But hopefully, terms like tokenization, embeddings, attention, and transformers feel a bit less mysterious now. Understanding these core concepts really helps pull back the curtain on how modern AI, especially LLMs, actually works its magic with language.
These aren't the only terms you'll hear, but they form a solid foundation. Keep learning, keep experimenting, and don't be afraid to ask questions! AI is constantly evolving, and being curious is the best way to keep up.
What other AI terms have you found confusing? Let me know in the comments!