![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)





































































































































































































































































































































































![Hostinger Horizons lets you effortlessly turn ideas into web apps without coding [10% off]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/IMG_1551.png?resize=1200%2C628&quality=82&strip=all&ssl=1)




![This new Google TV streaming dongle looks just like a Chromecast [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/04/thomson-cast-150-google-tv-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)












![Apple Drops New Immersive Adventure Episode for Vision Pro: 'Hill Climb' [Video]](https://www.iclarified.com/images/news/97133/97133/97133-640.jpg)

![Most iPhones Sold in the U.S. Will Be Made in India by 2026 [Report]](https://www.iclarified.com/images/news/97130/97130/97130-640.jpg)





























































































































A coordinated dance to identify the editor
Adding login logic - rationale In a previous article, I described how to take a web page source file, edit it, then send the edited source back to Github. In that post, the authorisation token id-token was one I generated for myself as a Github user. It would also be possible to assign to the hallowed glade (see previous article) an authorisation for a pseudo user or bot specifically set up to take user generated editing. However, when the edit is merged into the source, the author of the commit would be the bot, and not the author of the edit. Suppose, though, we want a 'credits' page listing authors and the number of commits they have made. We could run a command in the repo such as: git log --pretty="%an %n" | sort | uniq -c | sort -n -r and filter the results into a table. But authors who have entered our hallowed glade will not be listed. Another concern is spamming. If we require a community user to have a Github identity, then Github will handle authorisation. If there is spamming by a forest troll, it is in Github's best interest to hold that troll to account. This post explains (mostly to myself) the steps that are needed to insert a login layer. When I finally got the whole thing working, it was like a weird dance between three different entities. Looking at the documentation for the first time, all the steps seemed odd and unrelated, but once they were all put into motion, there is a logic to the whole thing. Overview We already have a hallowed glade, which is the suggestion_box server. The server runs in a docker container, and has a Cro server to handle input from a websocket, a Cro client to interact with Github to create a new branch, store the edited file, and raise a Pull Request. Github allows the owner of a repo to register a 'Github app' and assign it permissions. So, the token granted during the authorisation process is a combination of the permissions of the app and those of a user. It is always scary for a user to have to authorise someone else to do something on their behalf, so here is what Github says about the authorisation token: A token has the same capabilities to access resources and perform actions on those resources that the owner of the token has, and is further limited by any scopes or permissions granted to the token. A token cannot grant additional access capabilities to a user. Github authorisation documentation Coordination Here is diagram of the interaction between the browser, the server (in our case suggestion_box) and Github from a great article by Tony on OAuth2: Suppose we add in the request that if an editor wants to make edits on several documents (which means the page is refreshed), then it is inefficient for Github to generate an id-token for each page. We can keep an object in local storage with the name of the editor and the time the first submission is accepted. Note that Github issues its web tokens for a fixed period of time, by default 8 hours. A pre-requisite is that the Github app, which is our suggestion-box is already registered with Github. Steps The brief laid out above suggests the following series of steps: When a submission is made, the editor field in the submission form must be consistent with Github rules: Github has a user name policy of only alphanumeric characters + -, with a minimum of three characters and a maximum of 39. Letters are case insensitive and other characters are replaced by -. The browser checks to see if the editor has made a successful submission within the last 8 hours, and that 10 minutes is still left. if there is no or insufficient time, the local storage is deleted. If the editor has not been verified, the editor is sent to the Github login page, together with a state string that contains information for the suggestion_box to be able to issue a successful submission message back to the browser. Whether or not the editor has been verified, and in parallel with the Github verification, the suggestion information is sent to the suggestion_box as outlined in my previous article. Inside the suggestion_box server: The editor is verified to see whether an id-token with enough time (10 minutes) is available. If so, the suggestion is queued, and a successful message is sent back together with the remaining time on the token. If there is not enough time left, a failure message is sent back from the server to the browser. If there is no id-token and ten minutes have passed after the suggestion was received with no message from Github, a failure message is sent back to the browser. When a message is received from Github, it is compared with waiting suggestions. If there is not a match between the state field of a suggestion, the Github message is ignored. If the state matches a waiting suggestion, the suggestion-box server starts the process to get a id-token. If successful, the suggestion is queued and a message is sent back to the brows
Adding login logic - rationale
In a previous article, I described how to take a web page source file, edit it, then send the edited source back to Github.
In that post, the authorisation token id-token was one I generated for myself as a Github user. It would also be possible to assign to the hallowed glade (see previous article) an authorisation for a pseudo user or bot specifically set up to take user generated editing.
However, when the edit is merged into the source, the author of the commit would be the bot, and not the author of the edit.
Suppose, though, we want a 'credits' page listing authors and the number of commits they have made. We could run a command in the repo such as:
git log --pretty="%an %n" | sort | uniq -c | sort -n -r
and filter the results into a table. But authors who have entered our hallowed glade will not be listed.
Another concern is spamming. If we require a community user to have a Github identity, then Github will handle authorisation. If there is spamming by a forest troll, it is in Github's best interest to hold that troll to account.
This post explains (mostly to myself) the steps that are needed to insert a login layer.
When I finally got the whole thing working, it was like a weird dance between three different entities. Looking at the documentation for the first time, all the steps seemed odd and unrelated, but once they were all put into motion, there is a logic to the whole thing.
Overview
We already have a hallowed glade, which is the suggestion_box server. The server runs in a docker container, and has a Cro server to handle input from a websocket, a Cro client to interact with Github to create a new branch, store the edited file, and raise a Pull Request.
Github allows the owner of a repo to register a 'Github app' and assign it permissions. So, the token granted during the authorisation process is a combination of the permissions of the app and those of a user.
It is always scary for a user to have to authorise someone else to do something on their behalf, so here is what Github says about the authorisation token:
A token has the same capabilities to access resources and perform actions on those resources that the owner of the token has, and is further limited by any scopes or permissions granted to the token. A token cannot grant additional access capabilities to a user. Github authorisation documentation
Coordination
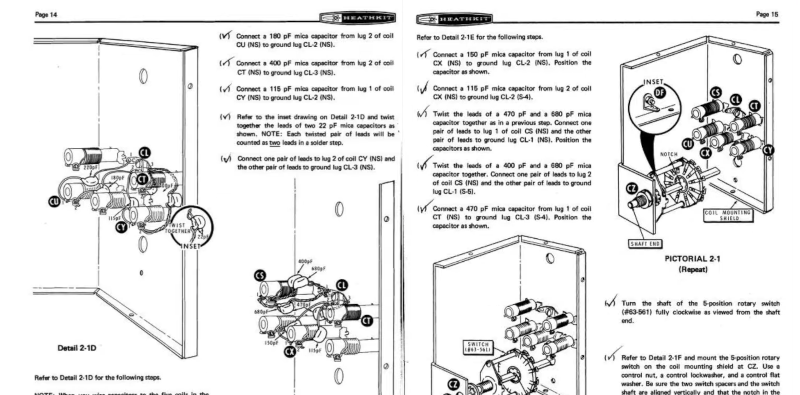
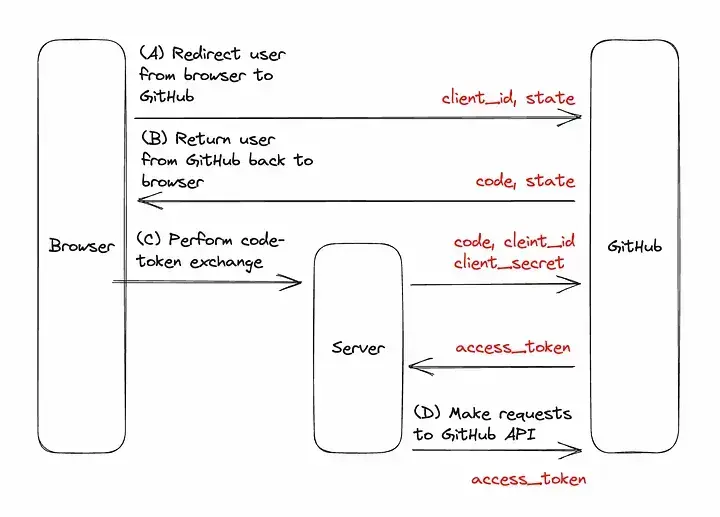
Here is diagram of the interaction between the browser, the server (in our case suggestion_box) and Github from a great article by Tony on OAuth2:
Suppose we add in the request that if an editor wants to make edits on several documents (which means the page is refreshed), then it is inefficient for Github to generate an id-token for each page.
We can keep an object in local storage with the name of the editor and the time the first submission is accepted.
Note that Github issues its web tokens for a fixed period of time, by default 8 hours.
A pre-requisite is that the Github app, which is our suggestion-box is already registered with Github.
Steps
The brief laid out above suggests the following series of steps:
- When a submission is made, the
editorfield in the submission form must be consistent with Github rules:- Github has a user name policy of only alphanumeric characters +
-, with a minimum of three characters and a maximum of 39. - Letters are case insensitive and other characters are replaced by
-.
- Github has a user name policy of only alphanumeric characters +
- The browser checks to see if the editor has made a successful submission within the last 8 hours, and that 10 minutes is still left.
- if there is no or insufficient time, the local storage is deleted.
- If the editor has not been verified, the editor is sent to the Github login page, together with a
statestring that contains information for the suggestion_box to be able to issue asuccessful submissionmessage back to the browser. - Whether or not the editor has been verified, and in parallel with the Github verification, the suggestion information is sent to the suggestion_box as outlined in my previous article.
Inside the suggestion_box server:
- The editor is verified to see whether an id-token with enough time (10 minutes) is available. If so, the suggestion is queued, and a successful message is sent back together with the remaining time on the token.
- If there is not enough time left, a failure message is sent back from the server to the browser.
- If there is no id-token and ten minutes have passed after the suggestion was received with no message from Github, a failure message is sent back to the browser.
- When a message is received from Github, it is compared with waiting suggestions. If there is not a match between the state field of a suggestion, the Github message is ignored.
- If the state matches a waiting suggestion, the suggestion-box server starts the process to get a id-token. If successful, the suggestion is queued and a message is sent back to the browser containing the success and the expiration time.
- if unsuccessful, a failure message is sent back to the browser
In this scheme,
- the browser never sees the editor's id-token.
- the actual name provided by the editor in the suggestion form does not have to be the Github name of the editor because the Github authorisation is independent of the editor's name, but future submissions must use the same editor name to use the id-token, which is time-limited in any case.
- an editor may edit several files in one session.
The Cro setup
In the previous post, the Cro app had a route for the websocket and a Client section to handle putting suggestions into Github.
We need to modify the Client section to use the editor's id-token, but essentially it remains the same.
We also need to add a route which is used by Github to send login information to the server. In addition, there needs to be a way for the webserver route and the authorisation route to interact.
These modifications imply a shared resource to match editor-name, id-token, id-token expiration date. Since Cro assumes concurrency, the storage has to be thread-safe and ensure that only one thread at a time can access it.
Although the Cro documentation uses
OO::Monitorfor this purpose, I prefer the simplerMethod::Protectedmodule. Theis protectedtrait ensures that only one thread at a time can access the shared resource. For example,
use Method::Protected;
class Editor-Store {
#| has key = editor, with two attributes :token and :time (a Date::Time)
has %!storage;
#| if False, makes sure editor key is deleted
method is-editor-active( $editor --> Bool) is protected {
return False unless %!storage{ $editor }:exists;
return True if %!storage{ $editor } > (now.DateTime + Duration.new(10 * 60));
sink %!storage{$editor}:delete;
return False
}
#| if there is no editor, an emptry string is returned
method get-token( $editor --> Str) is protected {
if self.is-editor-active( $editor ) { %!storage{$editor} }
else { '' }
}
#| expiration date
method expiration( $editor ) is protected { %!storage{$editor} }
#| returns the remaining time in seconds as an integer
method time-remaining( $editor --> Int ) is protected {
if self.is-editor-active( $editor ) { ( %!storage{ $editor } - now.DateTime).Int }
else { 0 }
}
#| adds editor
method add-editor( Str $editor, DateTime $expiration, Str $token ) is protected {
%!storage{$editor} = :$expiration, :$token;
}
}
The Websocket route of the Cro app needed refactoring completely. Instead of getting all the information for an edit from the browser, typically, the edit suggestion comes first but the editor and their id-token comes later. So the Webocket needs to create a promise and also to put a timer on it.
My first-draft solution is (the code needs to be cleaned up somewhat):
get -> 'suggestion_box' {
web-socket :json, -> $incoming {
supply whenever $incoming -> $message {
my $json = await $message.body;
# first filter out the handshake signal for opening a websocket
if $json {
say strftime(DateTime.now, '%v %R') ~ ': connection made'
if $debug;
emit({ :connection })
}
else {
if $debug {
say strftime(DateTime.now, '%v %R') ~ ': got suggestion, now at ' ~ +@suggestions;
for $json.kv -> $k, $v {
say "KEY $k =>\n$v"
}
say "edit suggestion finished\n";
}
my $response = sanitise( $json ); # sanitise returns an error message or 'ok'
my $editor := $json;
if $response ne 'OK' {
emit( {
:timestamp( DateTime.now.Str ),
:$response,
:$editor,
})
}
# handle the socket with an active editor
elsif $store.is-editor-active($editor) {
say strftime(DateTime.now, '%v %R') ~ ': editor is registered' if $debug;
# too little time left for token
if $store.time-remaining( $editor ) <= 10 * 60 {
say strftime(DateTime.now, '%v %R') ~ ': not enough time' if $debug;
emit( {
:timestamp( DateTime.now.Str ),
:response,
:$editor,
})
}
else {
say strftime(DateTime.now, '%v %R') ~ ': handling with stored token' if $debug;
$json = $store.get-token($editor);
@suggestions.push: $json;
emit( {
:timestamp( DateTime.now.Str),
:response,
:$editor,
:expiration( strftime($store.expiration($editor), '%v %R'))
} )
}
}
# the editor does not have a token, but may have in some period of time
else {
say strftime(DateTime.now, '%v %R') ~ ': editor without authorisation' if $debug;
my $timestamp;
my $response = 'NoAuthorisation';
my $expiration = '';
my $token = '';
my Promise $tapped-out .= new;
my $tap = $see-new-auths.tap( -> %a {
if %a eq $editor {
$timestamp = DateTime.now.Str;
$response = 'OK';
$token = %a;
$expiration = %a;
$tapped-out.keep;
}
});
await Promise.anyof(
$tapped-out,
my $timer = Promise.in($auth-wait-time).then: {
$response = 'NoAuthorisation';
}
).then( { $tap.close } );
if $response eq 'OK' {
$json = $token;
@suggestions.push: $json;
say strftime(DateTime.now, '%v %R') ~ ": authorising suggestion {$json.raku}, now at " ~ +@suggestions if $debug;
}
emit( %( :$timestamp, :$response, :$expiration, :$editor) )
}
}
}
}
The $tapped-out Promise is created so that it can be kept with .keep inside the code that listens for an authorisation event.
Then a separate Promise composed of the $tapped-out Promise and a timer Promise is created so that whichever comes first triggers the next step. If the timer exits before an authorisation, then the edit suggestion is discarded, otherwise it is combined with the id-token and queued.
In the code section above, the webserver is a supply and when the emit sub is called, the hash argument is mapped by Cro into a JSON object and returned to the browser that has connected to the Cro app. So it can be picked by the Javascript's websocket's onmessage function, and the data used by the browser program.
Authorisation event
When a Github app is registered, a route is supplied for the authorisation data. Consequently, the server section of the Cro app has to be set up to service this route. I chose the route /raku-auth (and in my code comes before the websocket, but since we are dealing with concurrent processes, the order of websocket and raku-auth is irrelevant):
get -> 'raku-auth', :%params {
CATCH {
default {
content 'text/html', 'Raku documentation
Authorisation error.
Please report';
say 'error is: ', .message;
for .backtrace.reverse {
next if .file.starts-with('SETTING::');
next unless .subname;
say " in block { .subname } at { .file } line { .line }";
last if .file.starts-with('NQP::')
}
}
}
my %decoded = from-json( base64-decode( %params).decode );
say strftime(DateTime.now, '%v %R') ~ ': got from Github params: ', %params , ' state decoded: ', %decoded
if $debug;
my $editor = %decoded;
my $resp = await Cro::HTTP::Client.post(
"https://github.com/login/oauth/access_token",
query => %(
:$client_id,
:$client_secret,
:code( %params ),
),
);
# Github returns an object with keys access_token, expires_in (& others not needed)
my $body = await $resp.body;
my %data = $body.decode.split('&').map(|*.split("=",2));
# first store the data for future suggestions
my $token = %data;
my $expiration = now.DateTime + Duration.new( %data);
$store.add-editor($editor, $expiration, $token );
# next put the data in a stream for suggestions that have already arrived
$auth-stream.emit( %( :$editor, :$expiration, :$token ) );
content 'text/html', 'Raku documentation
Editing has been authorised.
Thank you';
}
get -> 'suggestion_box' {
The CATCH phaser is only ever triggered if there is an error processing the route. If it is triggered, then the string after content is sent back to Github, which displays it in the tab containing the authorisation button. The HTML could be improved.
At the end of the code, the content sub similarly sends back an HTML string to indicated authorisation is successful.
When a route has a query appended to it, the Cro route function get captures the data into a named hash, which I have called %params. Github recommends that a state variable is sent when sending the user to Github for authorisation. I have chosen to send the name submitted by the editor with Base64 encoding. Since the editor name in the form and the user's Github id could be different, this adds some complexity to improve security.
I have to say that the Cro syntax is easy to work with. When the data is transmitted as a JSON, there is the named :body field, and with the data is transmitted as a query, there is the named :query field. Otherwise the get sub has a consistent syntax. Compare this to a cURL command.
The parameters sent to the route include a code field, which is then returned (again as a query) to Github. When it receives the code, it returns the id-token for the editor. This two-fold handshake makes it difficult to impersonate someone else.
In addition, Github returns the number of seconds the id-token is valid for. So this needs to be combined into a DateTime both for the suggestion-box server and the browser.
Finally, the editor name, id-token and expiration date are both stored in a thread-safe Hash, and placed in an event stream into which the websocket has tapped.
Raku's concurent structures make it easy to set up the event loop into which the raku-auth route injects information and the websocket listens for information. At the start of the code we have
my $auth-stream = Supplier.new;
my $see-new-auths = $auth-stream.Supply;
As can be seen from the code fragments, the raku-auth route has the line $auth-stream.emit( %(...) ) and the websocket code has the line my $tap = $see-new-auths.tap( -> %a { ... }).
The first stanza supplies an item, in this case as hash, while the second listens for all items supplied. The second then determines which item to react to.
Keeping secrets
One of the pieces of data required by a Github app is a 'secret' for the app. There are also several items to be provided to the Cro app.
Since this Cro app is intended for a docker container, the configuration data is conveyed in Environment variables. So at the start of the app, several secret variables are extracted as (just an example here):
my $client_id = %*ENV;
and these data can be temporarily saved in an environment file env-file. Then when the docker image is invoked the data can be supplied:
sudo docker run -d --rm --env-file env-file my-docker-image
Treading on toes
As can be seen from the diagram above, getting authorisation is delicate dance, and it took me days to stop the browser, Github and the suggestion-box treading on each others' toes.
First, the interaction between Github and the suggestion-box server to exchange a code for an id-token are all conducted using the query format. That is a url ending ?data-item=stuff&item-two=nonsense, which is in turn Base64 encoded. All the Github API calls use JSON data with authorisation headers.
In hindsight, we can recognise that the OAuth protocol is an industry standard, while the Github API protocols are not, so can be different. But it took me a while to work out what the strange data was being received by the server. I did not come across this behaviour as being explicitly documented.
Second, Github requires that the suggestion-box server is registered by the owner of the repo as a Github app and specific permissions need to be allocated to it. There are dozens of permissions in over a dozen categories and the correct ones have to be given to the Github app. I thought - mistakenly - that the permissions for Pull requests was what I needed.
Actually this was the last bug I had to overcome and it took a couple of days to figure out that the error was not in the server code, but that I had not allocated enough permissions.
To summarise, the suggestion-box server uses four separate Github API calls and the permissions are different:
-
api.github.com/repos/{$repo-name}/git/ref/heads/mainto get the commit sha for the repo-name - this is public data and the permission is mandatory for an App, so it does not need to be specifically added -
api.github.com/repos/{$repo-name}/git/refs(with data) to create a reference - this requires theContentspermission with read/write -
api.github.com/repos/{$repo-name}/contents/{$file-path}to supply the edited - this requires theContentspermission -
api.github.com/repos/{$repo-name}/pullsto create a pull request of the new branch - this requires thePull Requestpermission
Final thoughts
Some 'simple' requests have complex solutions. Although Cro and Raku's concurrent structures take a while to understand, they are easy to apply.