

























































































































































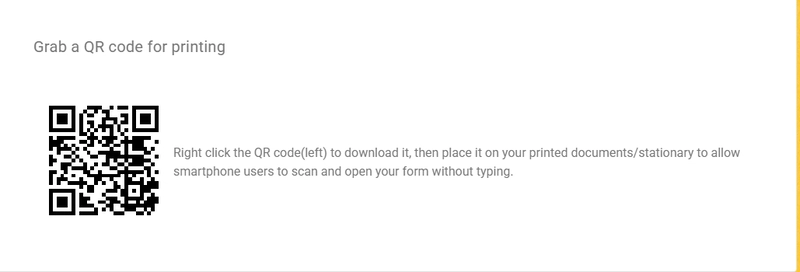
![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)




































































































































































































![Blue Archive tier list [April 2025]](https://media.pocketgamer.com/artwork/na-33404-1636469504/blue-archive-screenshot-2.jpg?#)

































.png?#)







.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)





























.webp?#)



















































































![[Update: Optional] Google rolling out auto-restart security feature to Android](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-2.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)












![Apple Releases iOS 18.4.1 and iPadOS 18.4.1 [Download]](https://www.iclarified.com/images/news/97043/97043/97043-640.jpg)
![Apple Releases visionOS 2.4.1 for Vision Pro [Download]](https://www.iclarified.com/images/news/97046/97046/97046-640.jpg)
![Apple Vision 'Air' Headset May Feature Titanium and iPhone 5-Era Black Finish [Rumor]](https://www.iclarified.com/images/news/97040/97040/97040-640.jpg)




















































































































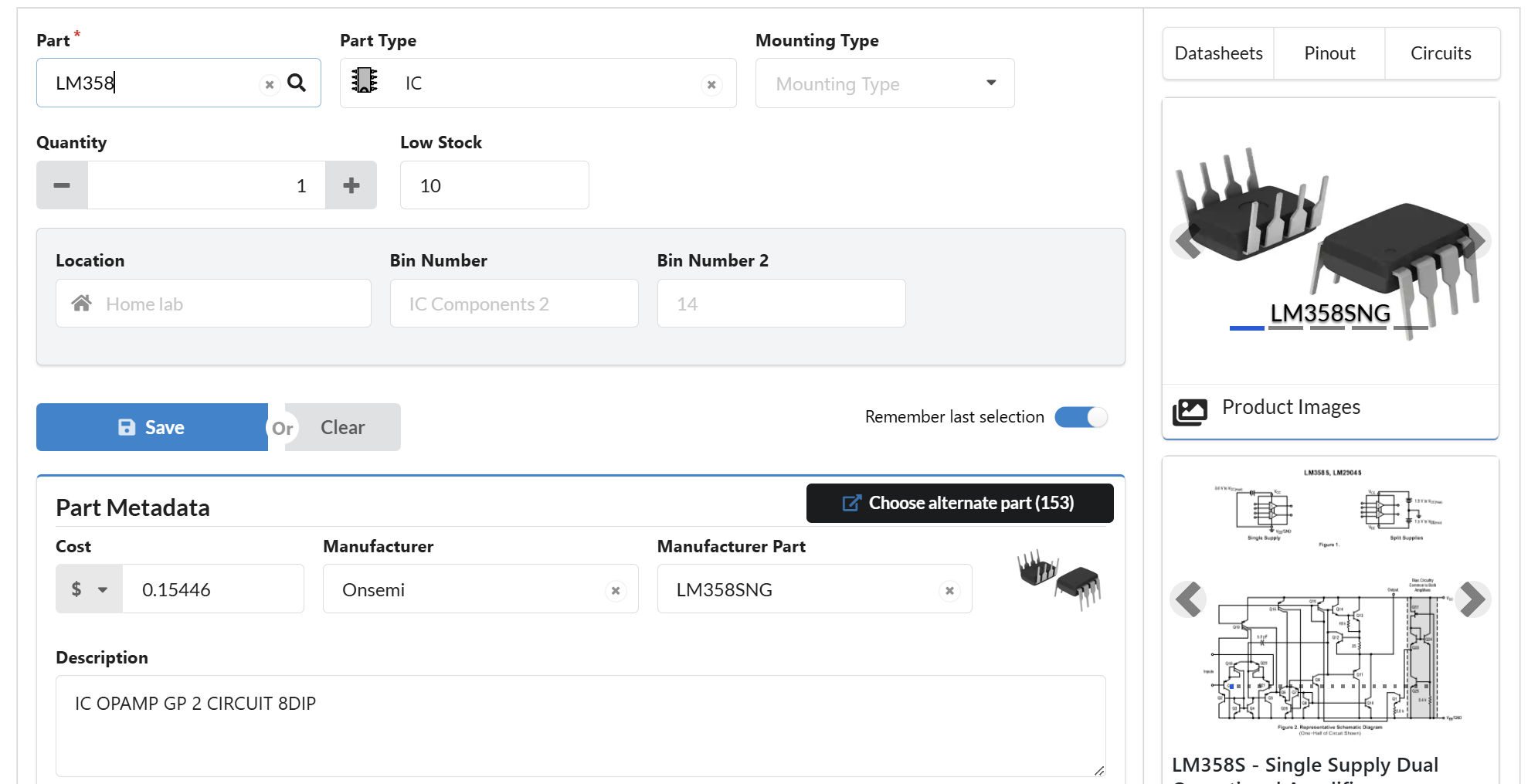
A beginner's guide to the Clip-Embeddings model by Krthr on Replicate
This is a simplified guide to an AI model called Clip-Embeddings maintained by Krthr. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Model overview The clip-embeddings model, developed by krthr, generates CLIP text and image embeddings using the clip-vit-large-patch14 model. CLIP (Contrastive Language-Image Pre-Training) is a computer vision model developed by researchers at OpenAI to learn about robustness and generalization in zero-shot image classification tasks. The clip-embeddings model allows users to generate CLIP embeddings for both text and image inputs, which can be useful for tasks like image-text similarity matching, retrieval, and multimodal analysis. This model is similar to other CLIP-based models like clip-vit-large-patch14, clip-vit-base-patch16, clip-vit-base-patch32, and clip-interrogator, all of which use different CLIP model variants and configurations. Model inputs and outputs The clip-embeddings model takes two inputs: text and image. The text input is a string of text, while the image input is a URI pointing to an image. The model outputs a single object with an "embedding" field, which is an array of numbers representing the CLIP embedding for the input text and image. Inputs text: Input text as a string image: Input image as a URI Outputs embedding: An array of numbers representing the CLIP embedding for the input text and image Capabilities The clip-embeddings model can be use... Click here to read the full guide to Clip-Embeddings
This is a simplified guide to an AI model called Clip-Embeddings maintained by Krthr. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Model overview
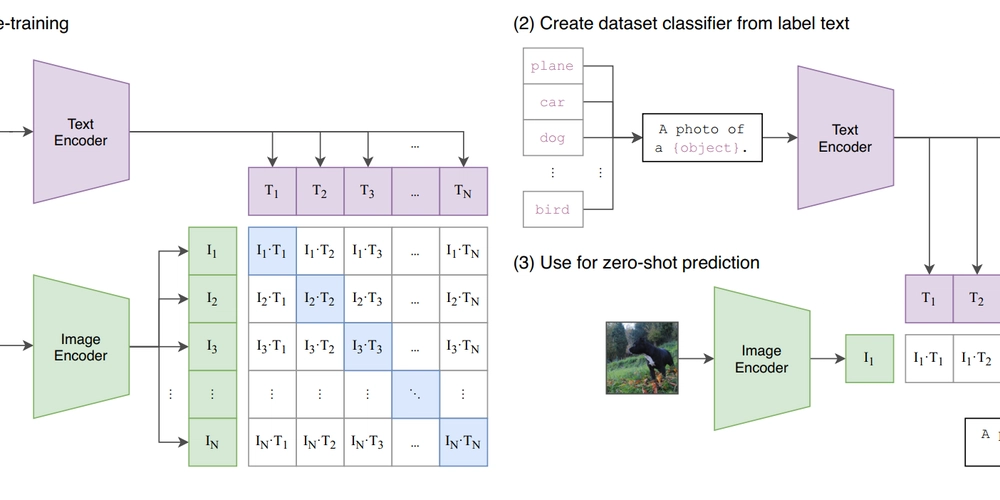
The clip-embeddings model, developed by krthr, generates CLIP text and image embeddings using the clip-vit-large-patch14 model. CLIP (Contrastive Language-Image Pre-Training) is a computer vision model developed by researchers at OpenAI to learn about robustness and generalization in zero-shot image classification tasks. The clip-embeddings model allows users to generate CLIP embeddings for both text and image inputs, which can be useful for tasks like image-text similarity matching, retrieval, and multimodal analysis.
This model is similar to other CLIP-based models like clip-vit-large-patch14, clip-vit-base-patch16, clip-vit-base-patch32, and clip-interrogator, all of which use different CLIP model variants and configurations.
Model inputs and outputs
The clip-embeddings model takes two inputs: text and image. The text input is a string of text, while the image input is a URI pointing to an image. The model outputs a single object with an "embedding" field, which is an array of numbers representing the CLIP embedding for the input text and image.
Inputs
- text: Input text as a string
- image: Input image as a URI
Outputs
- embedding: An array of numbers representing the CLIP embedding for the input text and image
Capabilities
The clip-embeddings model can be use...