










































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)



















































































































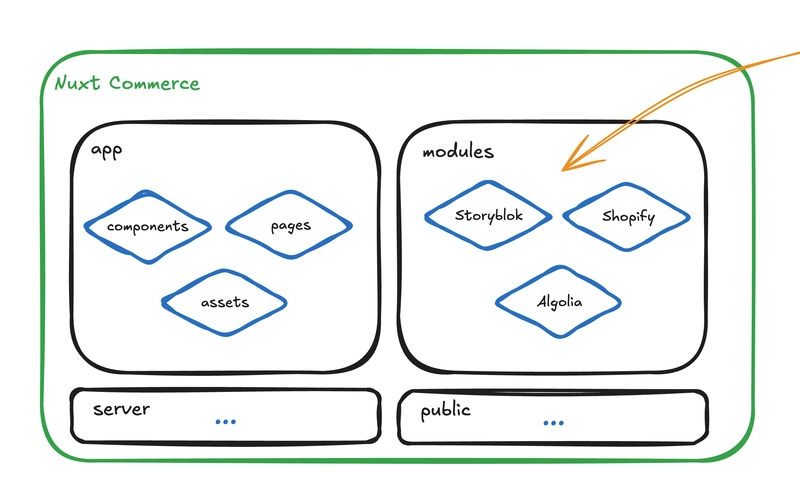














![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.png?#)























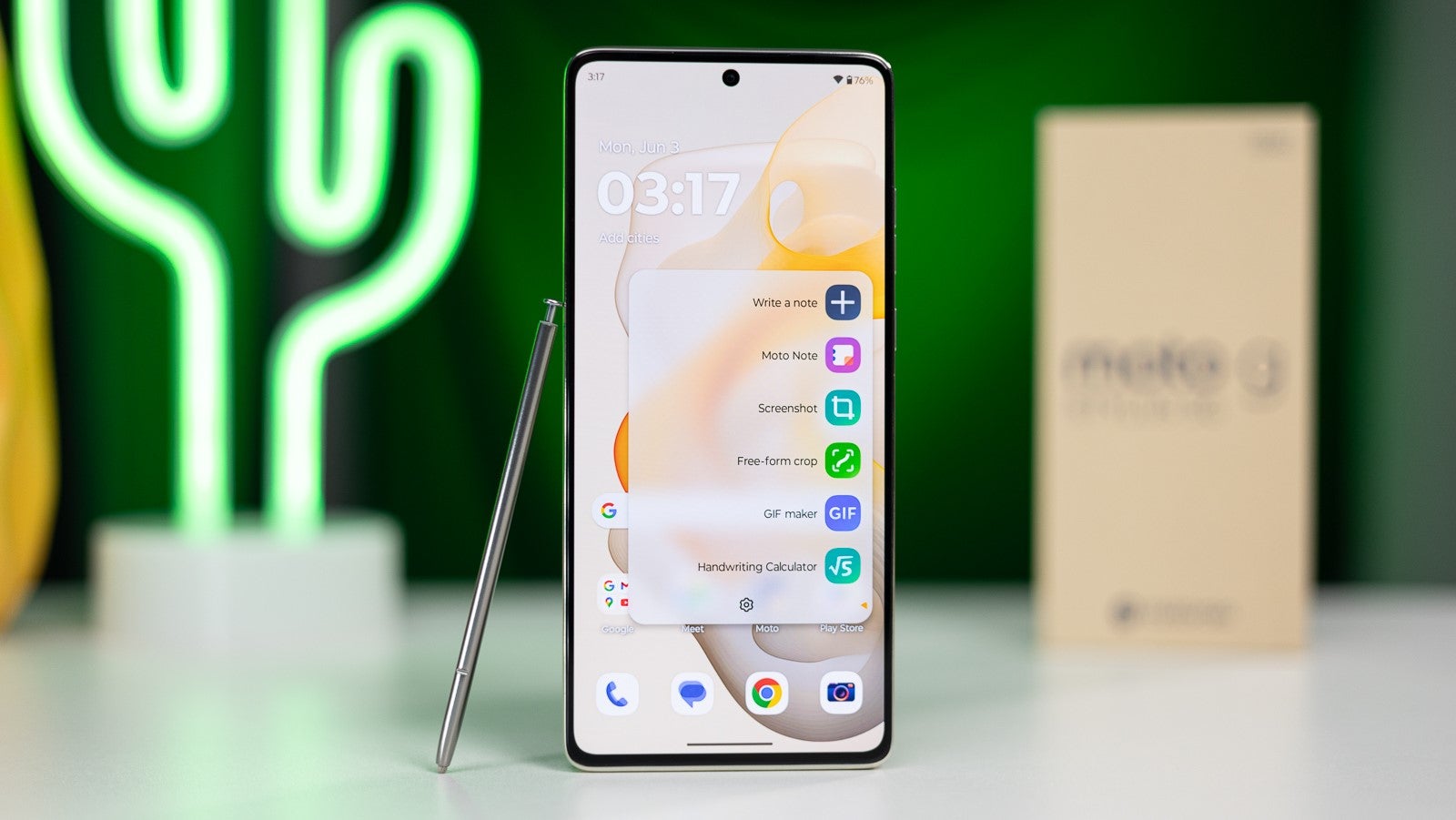










_Christophe_Coat_Alamy.jpg?#)



.webp?#)






































































































![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)
![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)

























































































































Why Is It So Hard to PDF Text Extraction?
Few tools can extract text from PDF correctly. But what’s the reason and how to overcome the difficulties? Let’s take a look. Reasons Reason 1: Complex, Various, and Similar PDF Text The following PDF text extraction problems occurred due to complex text writing, diverse writing systems, and similar character symbols. Text Spacing Issues: Text spacing can be defined in several ways, such as Character Spacing, Word Spacing, Leading, and Text Matrix. Errors in encoding or improper parsing can lead to overlapping text, abnormal spacing, or misaligned characters. Garbled Text/Strange Characters: If the PDF text extraction tool cannot access the full font or fails to parse font subsets correctly, text may appear as blanks or garbled characters. Issues with Hyphenated Words: Hyphenated words are often treated as separate text objects. The hyphenation logic is controlled by layout rules rather than text content, which can result in hyphens being deleted, extra spaces inserted, or incorrect hyphen placement. Similar Characters Distinguished Incorrectly: Glyph IDs in PDFs store characters visually, which can lead to misinterpretation during extraction. Reason 2: PDF Text Font Changes in PDF** ** Font recognition is another major reason why extracting PDF text is so hard. Due to the diversity of fonts and the possibility of dozens of fonts coexisting in a single PDF, font handling is a headache for many tech companies. If you encounter the following issues, it’s likely due to font recognition and restoration problems: Wrongly displayed Arial font when converting Garbled or blank text Missing or Replaced Special Characters Reason 3: Lack of Metadata of PDF Text Properties Why is PDF parsing hard? PDF files are page description formats that primarily store the visual layout of text rather than structural information. As a result, PDFs often lack data representing text properties such as headers, footers, boldness, size, and color. This leads to errors like Bold, Underline, and Italics when converting PDF text to other formats. Reason 4: Overlapping Text Layouts for Getting Wrong Text Position Text in PDFs is typically stored as drawing commands rather than in reading order. The following situations would identify the text position wrongly: Complex Layouts like Multi-Column: Overlapping text layers make it difficult to identify text positions. Disconnected Text Blocks: Independent text blocks may not be recognized as coherent content, leading to incorrect line breaks. Text Overlapping with Images: Mixed content of images and text can result in text being obscured or misplaced. Page Coordinate Systems: Scaling or rotating pages can cause errors in position information. Different PDF Generators: Various PDF generators may use different reference points or coordinate systems. Reason 5: Invisible PDF Text When extracting text from PDFs, the following text will reduce extraction quality: Hidden Text: Some text in PDFs may be extremely small or hidden. Off-Page Characters: PDFs often contain more text data than what is visible on the page. Reason 6: Text in Images or Scanned PDFs For the reason why it’s difficult to extract PDF text, images text must be a big problem. OCR (Optical Character Recognition) can help recognize and extract the text in scanned PDFs and images. The process typically involves the following steps and challenges: Recognition Steps: Image preprocessing Character segmentation Feature extraction and pattern matching Language model and context correction Challenges: Complex page layouts Handwritten text and unusual fonts Low-quality images Merged or broken characters Multilingual and mixed text Skewing, curvature, or distortion from the scan Reason 7: The correspondence between PDF table text and cells Extracting text and tables from PDF is generally straightforward, but the challenge lies in restoring the relationship between text and table cells. Issues like merged cells, missing borders, and text placement within cells complicate table recognition. Reason 8: Protect PDF from Copying Some PDFs restrict copying text. Embedded or encrypted content may require additional steps to access and decode before extraction. Security settings can prevent tools from accessing content unless proper permissions are provided or bypassed. How Do I Extract Text from a PDF Easily and Correctly — ComPDF Solution The latest version of ComPDFKit Conversion SDK addresses the challenges mentioned above, significantly improving the PDF text extraction for seamless PDF conversions to XLSX, TXT, Excel, and PPT. It parses and extracts text properties (bold, italics, size), spaces, location, layouts with AI models accurately like the following picture. Try our online PDF text recognition to test the latest PDF text extraction features.

Few tools can extract text from PDF correctly. But what’s the reason and how to overcome the difficulties? Let’s take a look.
Reasons
Reason 1: Complex, Various, and Similar PDF Text
The following PDF text extraction problems occurred due to complex text writing, diverse writing systems, and similar character symbols.
- Text Spacing Issues: Text spacing can be defined in several ways, such as Character Spacing, Word Spacing, Leading, and Text Matrix. Errors in encoding or improper parsing can lead to overlapping text, abnormal spacing, or misaligned characters.
- Garbled Text/Strange Characters: If the PDF text extraction tool cannot access the full font or fails to parse font subsets correctly, text may appear as blanks or garbled characters.
- Issues with Hyphenated Words: Hyphenated words are often treated as separate text objects. The hyphenation logic is controlled by layout rules rather than text content, which can result in hyphens being deleted, extra spaces inserted, or incorrect hyphen placement.
- Similar Characters Distinguished Incorrectly: Glyph IDs in PDFs store characters visually, which can lead to misinterpretation during extraction.
Reason 2: PDF Text Font Changes in PDF**
**
Font recognition is another major reason why extracting PDF text is so hard. Due to the diversity of fonts and the possibility of dozens of fonts coexisting in a single PDF, font handling is a headache for many tech companies. If you encounter the following issues, it’s likely due to font recognition and restoration problems:
- Wrongly displayed Arial font when converting
- Garbled or blank text
- Missing or Replaced Special Characters
Reason 3: Lack of Metadata of PDF Text Properties
Why is PDF parsing hard? PDF files are page description formats that primarily store the visual layout of text rather than structural information. As a result, PDFs often lack data representing text properties such as headers, footers, boldness, size, and color. This leads to errors like Bold, Underline, and Italics when converting PDF text to other formats.
Reason 4: Overlapping Text Layouts for Getting Wrong Text Position
Text in PDFs is typically stored as drawing commands rather than in reading order. The following situations would identify the text position wrongly:
- Complex Layouts like Multi-Column: Overlapping text layers make it difficult to identify text positions.
- Disconnected Text Blocks: Independent text blocks may not be recognized as coherent content, leading to incorrect line breaks.
- Text Overlapping with Images: Mixed content of images and text can result in text being obscured or misplaced.
- Page Coordinate Systems: Scaling or rotating pages can cause errors in position information.
- Different PDF Generators: Various PDF generators may use different reference points or coordinate systems.
Reason 5: Invisible PDF Text
When extracting text from PDFs, the following text will reduce extraction quality:
- Hidden Text: Some text in PDFs may be extremely small or hidden.
- Off-Page Characters: PDFs often contain more text data than what is visible on the page.
Reason 6: Text in Images or Scanned PDFs
For the reason why it’s difficult to extract PDF text, images text must be a big problem. OCR (Optical Character Recognition) can help recognize and extract the text in scanned PDFs and images. The process typically involves the following steps and challenges:
Recognition Steps:
- Image preprocessing
- Character segmentation
- Feature extraction and pattern matching
- Language model and context correction
Challenges:
- Complex page layouts
- Handwritten text and unusual fonts
- Low-quality images
- Merged or broken characters
- Multilingual and mixed text
- Skewing, curvature, or distortion from the scan
Reason 7: The correspondence between PDF table text and cells
Extracting text and tables from PDF is generally straightforward, but the challenge lies in restoring the relationship between text and table cells. Issues like merged cells, missing borders, and text placement within cells complicate table recognition.
Reason 8: Protect PDF from Copying
Some PDFs restrict copying text. Embedded or encrypted content may require additional steps to access and decode before extraction. Security settings can prevent tools from accessing content unless proper permissions are provided or bypassed.
How Do I Extract Text from a PDF Easily and Correctly — ComPDF Solution
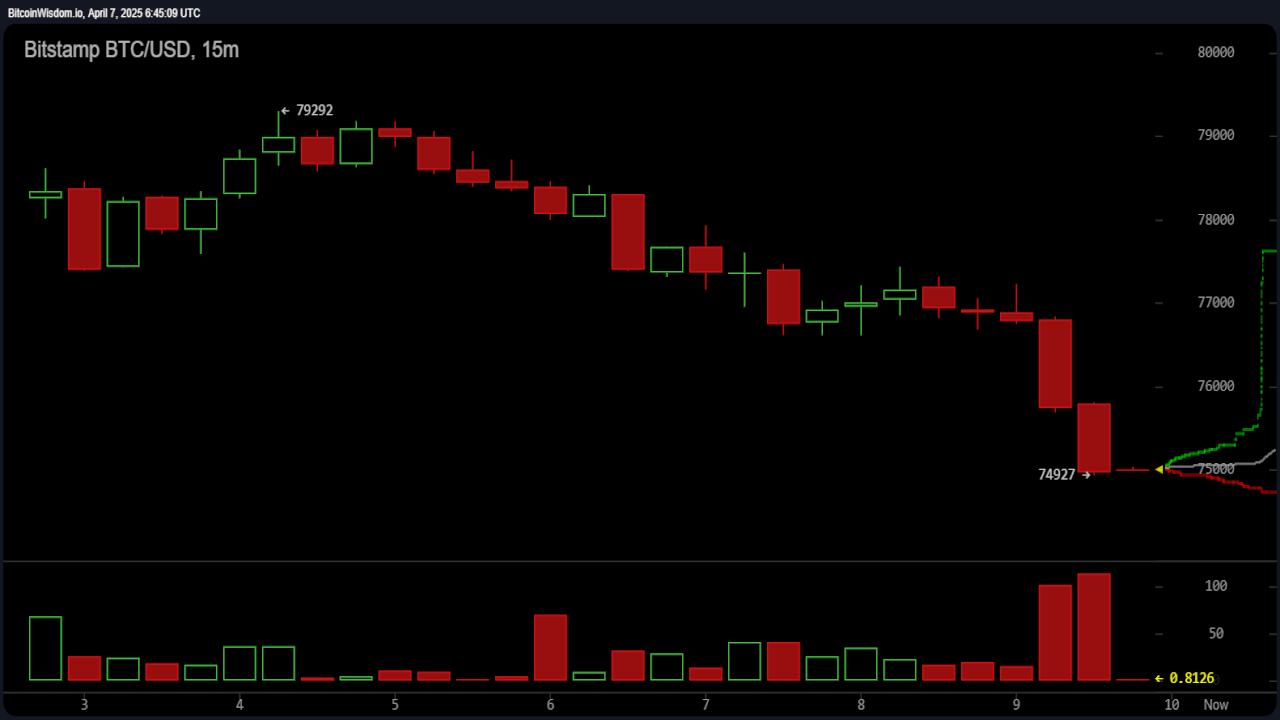
The latest version of ComPDFKit Conversion SDK addresses the challenges mentioned above, significantly improving the PDF text extraction for seamless PDF conversions to XLSX, TXT, Excel, and PPT. It parses and extracts text properties (bold, italics, size), spaces, location, layouts with AI models accurately like the following picture.
Try our online PDF text recognition to test the latest PDF text extraction features.



