![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)



















































































































































































































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



























































































![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)












![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)































































































































The Singoff-agen — Learning Through Dumb Projects
I’m not a software engineer. I’m a systems engineer. For those wondering, this is a lot like being a “business analyst”. You’re a generic problem solver, and usually you become a systems engineer after hanging up the tools and your technical skills in favor of high-level problem solving. Trade studies, crafting requirements, system integration, verification and validation; all the classics for anyone that’s worked in big engineering corporations pushing paper. Losing your technical skills is rough, but it happens to a lot of us. But over the past few years this changed a little. I started a new job that gave me some room to experiment with data science. Here is where I actually started to learn some programming skills, mostly in Python which is the go-to for data science. While doing this I really discovered the fun of programming. I found myself with a thirst to practice more, but I had been battling some issues with unhealthy workaholism. I didn’t want to crack open the work laptop on a weekend to practice, so I found myself searching for personal projects at home. I discovered ThePrimeagen’s YouTube channel 6 months ago and I found it a nice ritual watching his videos with my morning coffee. Technically informative and entertaining, I became an avid watcher of every new video (though I’m not part of the Twitch community where he streams). And some of his advice really stuck with me, specifically that dumb projects are often a great way to learn. I don't know why this makes him look like James Franco... The Project You all know it by now, Primeagen’s signoffs; “The Name… is the primeagen”. His signoff has variability though. It’s often something like “the name… -agen”. These are a feature of Prime’s comedy, and I found myself wondering “What’s the longest, most meandering signoff this guy’s ever dropped?” And so I found my dumb project. ⚠️WARNING: You’re going to see a lot of shady REGEX being rawdogged in to parse XML and other data in this article. Before anyone posts comments freaking out about this, understand that I am fully aware of (and lovingly embrace) the danger of this. There are no stakes here. Getting The Data First, I had to get the data. I thought this would be a good place to use Google Cloud API which can extract Youtube transcripts. But while setting up this service, I realized there was an even easier way; by extracting the auto-generated captions from YouTube. (Thankyou _jdepoix _for the library to do so, https://github.com/jdepoix/youtube-transcript-api). “How do I get a list of all Primeagen video links?” I hear you say. Wellp! I just scroll to the bottom of this youtube channel. I saved the HTML out and simply regexed each titleand href from the file. Yes there’s probably an API somewhere that would have given this to me, but I wasn’t immediately able to find it. So I’m left with a list of ~860 videos as of March, 2025. I then iterate through these and query for the captions from the API. Note, there were a handful of videos that didn’t have captions enabled, so they’re not in this dataset. Parsing The Dialogue The captions files contain the individual snippets which is quite useful. Each snippet of text has a start time and duration in seconds. { "text": "didn't see coming back and uh well ", "start": 11.679, "duration": 4.921, }, The Start Delimiter (“the name…”) To isolate the signoffs, I consider the following rules: Rule 1. The signoff will start with “the name” Rule 2. The signoff will be contained between the last mention of "the name" and the end of the video. The first problem I encounter is, sometimes “the name” is split into 2 snippets in the captions. { "text": "Engineers are in fact not Engineers the ", "start": 1414.919, "duration": 7.401 }, { "text": "name is the primagen ", "start": 1418.32, "duration": 4.0 } I decide to just merge all the dialog into a single block of text per episode and now I’m able to capture “the name” and all text that follows. There’s a few different regex rules to try and isolate stronger and weaker signals for “the name”: pos_theNameIsThe = re.split(r'\Wthe name is the\W', transcript) pos_theNameIsThe = len_script - len(pos_theNameIsThe[-1]) pos_theNameIs = re.split(r'\Wthe name is\W', transcript) pos_theNameIs = len_script - len(pos_theNameIs[-1]) pos_theName = re.split(r'\Wthe name (?!(of|for))', transcript) pos_theName = len_script - len(pos_theName[-1]) Not that simple, it turns out. Sometimes the simple words “the name” are spoken thoughout a video just in conversation, but it’s not actually the signoff. (e.g.: https://youtu.be/drCnFueS4og&t=3650). I was going to need some more evidence to properly isolate the true signoff; and this means looking for the “-agen!”. Side Quest: Navigability Before this, I needed to make things easier to navigate

I’m not a software engineer. I’m a systems engineer. For those wondering, this is a lot like being a “business analyst”. You’re a generic problem solver, and usually you become a systems engineer after hanging up the tools and your technical skills in favor of high-level problem solving. Trade studies, crafting requirements, system integration, verification and validation; all the classics for anyone that’s worked in big engineering corporations pushing paper. Losing your technical skills is rough, but it happens to a lot of us.
But over the past few years this changed a little. I started a new job that gave me some room to experiment with data science. Here is where I actually started to learn some programming skills, mostly in Python which is the go-to for data science. While doing this I really discovered the fun of programming.
I found myself with a thirst to practice more, but I had been battling some issues with unhealthy workaholism. I didn’t want to crack open the work laptop on a weekend to practice, so I found myself searching for personal projects at home.
I discovered ThePrimeagen’s YouTube channel 6 months ago and I found it a nice ritual watching his videos with my morning coffee. Technically informative and entertaining, I became an avid watcher of every new video (though I’m not part of the Twitch community where he streams). And some of his advice really stuck with me, specifically that dumb projects are often a great way to learn.
I don't know why this makes him look like James Franco...
The Project
You all know it by now, Primeagen’s signoffs; “The Name… is the primeagen”. His signoff has variability though. It’s often something like “the name… -agen”. These are a feature of Prime’s comedy, and I found myself wondering “What’s the longest, most meandering signoff this guy’s ever dropped?” And so I found my dumb project.
⚠️WARNING: You’re going to see a lot of shady REGEX being rawdogged in to parse XML and other data in this article. Before anyone posts comments freaking out about this, understand that I am fully aware of (and lovingly embrace) the danger of this. There are no stakes here.
Getting The Data
First, I had to get the data. I thought this would be a good place to use Google Cloud API which can extract Youtube transcripts. But while setting up this service, I realized there was an even easier way; by extracting the auto-generated captions from YouTube. (Thankyou _jdepoix _for the library to do so, https://github.com/jdepoix/youtube-transcript-api).
“How do I get a list of all Primeagen video links?” I hear you say. Wellp! I just scroll to the bottom of this youtube channel. I saved the HTML out and simply regexed each titleand href from the file. Yes there’s probably an API somewhere that would have given this to me, but I wasn’t immediately able to find it.
So I’m left with a list of ~860 videos as of March, 2025. I then iterate through these and query for the captions from the API. Note, there were a handful of videos that didn’t have captions enabled, so they’re not in this dataset.
Parsing The Dialogue
The captions files contain the individual snippets which is quite useful. Each snippet of text has a start time and duration in seconds.
{
"text": "didn't see coming back and uh well ",
"start": 11.679,
"duration": 4.921,
},
The Start Delimiter (“the name…”)
To isolate the signoffs, I consider the following rules:
Rule 1. The signoff will start with “the name”
Rule 2. The signoff will be contained between the last mention of "the name" and the end of the video.
The first problem I encounter is, sometimes “the name” is split into 2 snippets in the captions.
{
"text": "Engineers are in fact not Engineers the ",
"start": 1414.919,
"duration": 7.401
},
{
"text": "name is the primagen ",
"start": 1418.32,
"duration": 4.0
}
I decide to just merge all the dialog into a single block of text per episode and now I’m able to capture “the name” and all text that follows. There’s a few different regex rules to try and isolate stronger and weaker signals for “the name”:
pos_theNameIsThe = re.split(r'\Wthe name is the\W', transcript)
pos_theNameIsThe = len_script - len(pos_theNameIsThe[-1])
pos_theNameIs = re.split(r'\Wthe name is\W', transcript)
pos_theNameIs = len_script - len(pos_theNameIs[-1])
pos_theName = re.split(r'\Wthe name (?!(of|for))', transcript)
pos_theName = len_script - len(pos_theName[-1])
Not that simple, it turns out. Sometimes the simple words “the name” are spoken thoughout a video just in conversation, but it’s not actually the signoff. (e.g.: https://youtu.be/drCnFueS4og&t=3650). I was going to need some more evidence to properly isolate the true signoff; and this means looking for the “-agen!”.
Side Quest: Navigability
Before this, I needed to make things easier to navigate between the script and the actual video. I was finding it tedious exploring these videos trying to find the actual signoff. I had the position of the start delimiter in the script in terms of character position in the entire script for a video. But I didn’t have the position in time in order to navigate to a position in the video.
I adjusted the function that farmed the video captions to also capture how far each snipped was in characters from the start of the video, and the snippets length in characters. So, this now gives me all the dialogue’s location in both time and characters.
{
"text": "didn't see coming back and uh well ",
"start": 11.679,
"duration": 4.921,
"start_chars": 196,
"duration_chars": 35,
},
So whenever I found the “the name” delimiter position, I could cross reference to the last snippet with a character distance under this position (which should be the caption in the video just before “the name” is mentioned). I then formed the YouTube shareable link with a timestamp of this snippets “start” time.
The End Delimiter (“-agen”)
The signoff always ends with something like “-agen!”. But this is always mis-captured by YouTube’s captions function because it’s not a full word, it’s a word fragment. Below are some of the “species” of mistranslations:
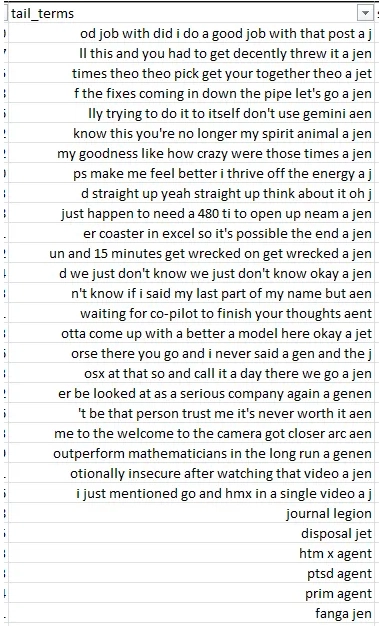
Though inconsistently translated, they are usually something similar to “aen”, “jen”, “gen”, “j” or “gin”. So this can be used as a signal to indicate that we actually have the signoff in the video.
Rule 3. The signoff will end with a word that matches “aen”, “jen”, “gen”, “j” or “gin”, etc.
If you’re really curious, the full pattern looks like this (gross…)
\W(primy|prime|primon|primeagen|primeag|genen|chen|genin|jen|jet|jin|jit|j|jan|ait|aen|ged|aent|agen|agent|legion)\W
So now with all the rules above I was able to extract the signoff (if it existed) from every video. I put all of this into a Pandas dataframe for processing. I captures the timestamps of both start and end delimiters and the timespan between them in seconds. Then I sorted the dataframe on the length of this timepsan (the signoff duration).
The Anomalies
In the end, I couldn’t treat the rules above as hard rules. I did need to inspect the table of results manually to remove anomalies, as listed below.
One-sided signoffs
Sometimes Prime will start a signoff with “the name” but he won't actually close off with “-agen”. Likewise, sometimes he’ll close of with “-agen”, but “the name” wasn’t uttered earlier. Perhaps these happen because Flip edits them out or Prime simply forgets one half of the signoff.
For example, this would have been the longest signoff if there was an “-agen” at the end:
Meet Devin — The End Of Programmers As We Know It https://youtu.be/80MPXoRHvK8&t=1665 (3:15 long)
I inserted checks in the code to detect when only one side was available and filter these out of the dataset.
False Positives
These videos have a one-sided signoff, specifically an orphaned “-agen” at the end of the video. But they also have a point earlier where Prime says “the name” early in the video just conversationally, not an actual signoff. So this gets picked up as a very long signoff.
I wasn’t able to come up with a reliable way of removing these cases without the possibility of losing some signoffs. So I just resigned to the fact that I’d need to manually QA these at the end.
Profanity Censoring
Now and again, you’ll get strange characters in the captions where swear words have been censored. e.g. “just [Â __Â ] a gen”, where the word “bullshit” is removed (https://youtu.be/XHl_9oXVui4&t=1787). This didn’t really cause any issues, just something I noticed.
The Findings
After manually filtering out the anomalies discovered above, I am left with the following: