![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






















































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)



























































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



























































































![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)
































































































































The Algorithm of Resilience: How Neural Networks Teach Us to Embrace Life’s Training Loop
Imagine if every human struggle, every setback, and every hard-won triumph were encoded into a simple loop of instructions. The truth is, they already are. We often imagine progress as a straight line leading us from one triumph to another, but anyone who has faced a real challenge knows life is more like a winding staircase. Each step is a small advance forward, although you may find yourself pausing or backtracking at times. This same iterative nature can be seen in the training of a deep learning model. A process centered on constant refinement and adaptation. Through examining a simple piece of machine learning code, we can uncover a striking parallel to our own pathways of personal growth. for epoch in range(num_epochs): ... This line says we will repeat our process for a certain number of epochs or cycles. No neural network converges in a single epoch. Loss curves spike and dip; progress is erratic. Yet over time, the trend bends toward mastery. Human lives mirror this. We cycle through seasons of growth and plateaus, joy and grief. The poet Rilke wrote, “No feeling is final,” and neither is any failure—or any success. The loop continues. outputs = model(inputs) loss = criterion(outputs, labels) The model takes in inputs: its best effort at interpreting the information it is given, and then calculates a loss, which measures how far its output is from the desired goal. In life, our “inputs” might be our natural talents, experiences, or ideas we choose to share with the world. These efforts are never perfect from the start, and a certain measure of failure is inevitable. Mistakes and shortcomings are not meant to break us; instead, they serve as the feedback we need to see where we fall short and how we can get closer to success. Loss is not defeat! It is feedback!!. So we must act before we feel ready. Think of the first drafts of novels, the shaky startup prototypes, or the tentative steps of a new relationship. Consider Thomas Edison’s 1,000 failed lightbulb prototypes or J.K. Rowling’s 12 publisher rejections. These were not endpoints but data points. The loss function teaches us to measure our missteps objectively, not as moral failures, but as directional arrows pointing toward refinement. Like the model, we won’t get it right on the first try. But without that initial output, there’s nothing to improve. optimizer.zero_grad() loss.backward() optimizer.step() Here lies the heart of growth: backpropagation. The model doesn’t cling to its mistakes; it uses them to adjust its weights. The zero_grad() command is a act of radical clarity—a reset button for the mind. For humans, this is the pause after failure: the deep breath before the next attempt. Reflecting on this process can inspire a healthier relationship with success and failure. We come to see that mistakes are not the end of the story. Rather, they are signals pointing us toward the steps we must take to grow. Just like a neural network striving to reduce its loss, we only reach our strongest potential by learning from every stumble, pivoting when we must, and trying again. Knowledge without action is inert. The optimizer step is where theory becomes practice where gradients transform into updated parameters. For us, this is the decision to act differently. It’s Malala Yousafzai advocating for education after surviving violence, or SpaceX iterating on rocket designs after explosive failures. Progress isn’t passive; it requires the courage to change course, even when the old ways feel comfortable. Every optimizer step in life: a new habit, an apology, a risk taken is a declaration that growth matters more than comfort. Here is the quiet truth written into every training loop: Life is not linear. You will repeat epochs. You’ll face losses that feel insurmountable. You’ll question whether the loop is worth continuing. But remember: every “backward pass” in your life. Every moment of reflection contains the seeds of wisdom. Every “optimizer step” you take, no matter how small, accumulates into transformation. The universe itself operates in cycles: seasons tides, celestial orbits. Why should your journey be any different? So when the loss feels too heavy, when the gradients of doubt threaten to vanish, return to the loop. Clear the gradients of yesterday’s regrets. Compute the backward pass of honest reflection. Take the optimizer step of courageous action. Repeat. The model doesn’t know when it will converge. It only knows to keep iterating. Neither do we. And that’s where the magic hides: not in the certainty of success, but in the stubborn, beautiful act of showing up for the next epoch. Your training loop is still running. Keep compiling.
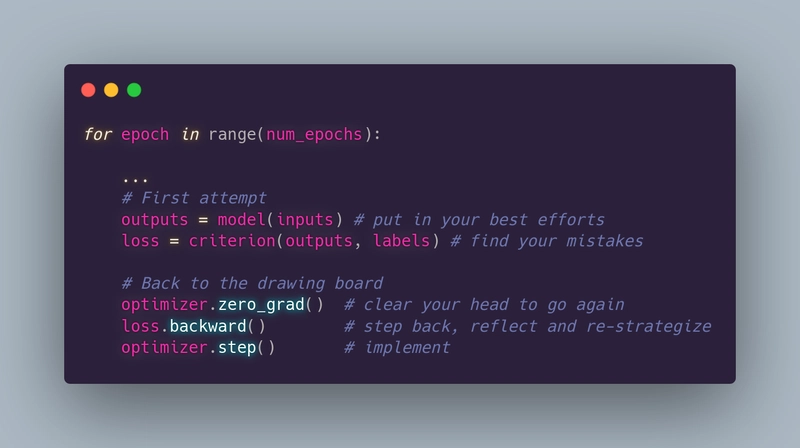
Imagine if every human struggle, every setback, and every hard-won triumph were encoded into a simple loop of instructions. The truth is, they already are. We often imagine progress as a straight line leading us from one triumph to another, but anyone who has faced a real challenge knows life is more like a winding staircase. Each step is a small advance forward, although you may find yourself pausing or backtracking at times. This same iterative nature can be seen in the training of a deep learning model. A process centered on constant refinement and adaptation. Through examining a simple piece of machine learning code, we can uncover a striking parallel to our own pathways of personal growth.
for epoch in range(num_epochs):
...
This line says we will repeat our process for a certain number of epochs or cycles. No neural network converges in a single epoch. Loss curves spike and dip; progress is erratic. Yet over time, the trend bends toward mastery. Human lives mirror this. We cycle through seasons of growth and plateaus, joy and grief. The poet Rilke wrote, “No feeling is final,” and neither is any failure—or any success. The loop continues.
outputs = model(inputs)
loss = criterion(outputs, labels)
The model takes in inputs: its best effort at interpreting the information it is given, and then calculates a loss, which measures how far its output is from the desired goal. In life, our “inputs” might be our natural talents, experiences, or ideas we choose to share with the world. These efforts are never perfect from the start, and a certain measure of failure is inevitable. Mistakes and shortcomings are not meant to break us; instead, they serve as the feedback we need to see where we fall short and how we can get closer to success. Loss is not defeat! It is feedback!!. So we must act before we feel ready. Think of the first drafts of novels, the shaky startup prototypes, or the tentative steps of a new relationship. Consider Thomas Edison’s 1,000 failed lightbulb prototypes or J.K. Rowling’s 12 publisher rejections. These were not endpoints but data points. The loss function teaches us to measure our missteps objectively, not as moral failures, but as directional arrows pointing toward refinement. Like the model, we won’t get it right on the first try. But without that initial output, there’s nothing to improve.
optimizer.zero_grad()
loss.backward()
optimizer.step()
Here lies the heart of growth: backpropagation. The model doesn’t cling to its mistakes; it uses them to adjust its weights. The zero_grad() command is a act of radical clarity—a reset button for the mind. For humans, this is the pause after failure: the deep breath before the next attempt.
Reflecting on this process can inspire a healthier relationship with success and failure. We come to see that mistakes are not the end of the story. Rather, they are signals pointing us toward the steps we must take to grow. Just like a neural network striving to reduce its loss, we only reach our strongest potential by learning from every stumble, pivoting when we must, and trying again.
Knowledge without action is inert. The optimizer step is where theory becomes practice where gradients transform into updated parameters. For us, this is the decision to act differently. It’s Malala Yousafzai advocating for education after surviving violence, or SpaceX iterating on rocket designs after explosive failures. Progress isn’t passive; it requires the courage to change course, even when the old ways feel comfortable. Every optimizer step in life: a new habit, an apology, a risk taken is a declaration that growth matters more than comfort.
Here is the quiet truth written into every training loop: Life is not linear. You will repeat epochs. You’ll face losses that feel insurmountable. You’ll question whether the loop is worth continuing. But remember: every “backward pass” in your life. Every moment of reflection contains the seeds of wisdom. Every “optimizer step” you take, no matter how small, accumulates into transformation. The universe itself operates in cycles: seasons tides, celestial orbits. Why should your journey be any different?
So when the loss feels too heavy, when the gradients of doubt threaten to vanish, return to the loop. Clear the gradients of yesterday’s regrets. Compute the backward pass of honest reflection. Take the optimizer step of courageous action. Repeat. The model doesn’t know when it will converge. It only knows to keep iterating. Neither do we. And that’s where the magic hides: not in the certainty of success, but in the stubborn, beautiful act of showing up for the next epoch.
Your training loop is still running. Keep compiling.