![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)















































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)







































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)









































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

























































































![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)































































































































Taking Machine Learning to Production: A Practical Guide Through the ML Lifecycle
Machine learning in production is a completely different game from training models on your local machine. It’s not just about achieving 95% accuracy on a test set — it’s about building a system that can operate reliably, adapt to real-world inputs, and deliver consistent value to users. In this post, we'll walk through the end-to-end machine learning development lifecycle, focusing on the key stages and common pitfalls teams face when transitioning from a prototype to a production-ready system. This framework is structured into four key stages: Scoping → Data → Modeling → Deployment Let’s take a closer look at each. 1. Scoping: Define the Problem, Not the Model Many ML projects fail because teams jump into modeling before they truly understand the problem. What to focus on: Problem Statement: What specific issue are you solving? Is ML even the right tool? User Impact: Who are the stakeholders? What is the desired outcome? System Design: How will this solution integrate with existing workflows or infrastructure? This phase is about asking the right questions. For example, if you're building an intent classification model for customer support, think beyond "classify correctly." Consider how the model will handle ambiguity, unseen queries, and evolving language trends. Tip: Define success not just in terms of accuracy, but also in terms of business value and usability. 2. Data: The Backbone of Any ML System a) Define Data & Establish a Baseline You can’t improve what you can’t measure. Start by collecting representative samples of your problem space and build a simple baseline — even rule-based if necessary. This helps: Validate assumptions Spot edge cases early Set realistic performance expectations b) Label & Organize Baseline Labeled data is your fuel. Without a consistent, well-maintained dataset, your model's performance will plateau — or worse, degrade over time. Best practices: Create clear labeling guidelines Use tooling to streamline annotation Continuously validate your labels with subject matter experts Store data in a way that supports versioning and retrieval (e.g., a hybrid SQL/NoSQL system) Challenge: Data ambiguity is common. Establish processes for resolving conflicting labels and expanding your intent or class taxonomy over time. 3. Modeling: More Than Just Training a) Select and Train Model Choose a model architecture based on the nature of your problem, the complexity of the data, and the performance constraints of your system. Example considerations: Sequence models like BiLSTM or Transformers for NLP tasks CNNs or ViTs for image classification Model inference time if deploying on edge devices Also consider the ecosystem: PyTorch may be preferable for research or flexibility TensorFlow may offer better tooling for deployment and mobile Track: Training and validation performance Model size and inference time Confidence scores for better threshold tuning b) Perform Error Analysis Your test accuracy only tells part of the story. Dive deeper: What types of examples is your model failing on? Are errors consistent across categories or biased toward certain inputs? Are false positives or false negatives more costly? Use confusion matrices, manual review, and feedback data to drive iterative improvements. Tip: Error analysis is where the real value of experimentation lies. The goal is to uncover why your model behaves the way it does — not just whether it performs well. 4. Deployment: Build for Reality, Not Just for Demo Day a) Deploy in Production Serving your model in production comes with trade-offs: Latency vs. Accuracy Scalability vs. Cost Security vs. Accessibility Common approaches: Containerized APIs using FastAPI, Flask, or Django Serverless endpoints for lightweight models Model serialization with ONNX, TorchScript, or TensorFlow SavedModel Ensure observability is built in from day one — logs, metrics, and versioning. b) Monitor and Maintain Once deployed, models are exposed to data drift, user behavior changes, and edge cases. What to monitor: Prediction distribution over time API latency and error rates Confidence score distributions Real-time user feedback and corrections Build pipelines to: Flag low-confidence predictions Trigger model retraining based on drift Track feedback loops for human-in-the-loop retraining Important: Your model is part of a larger system. Treat monitoring and maintenance as first-class citizens, not afterthoughts. Summary: ML Lifecycle in Production Stage What to Focus On Scoping Clear problem definition, integration points, measurable goals Data High-quality labeling, data pipelines, baseline models Modeling Framework trade-offs, metric analysis, interpretability Deployment Secure APIs, monitoring, version control, feedbac
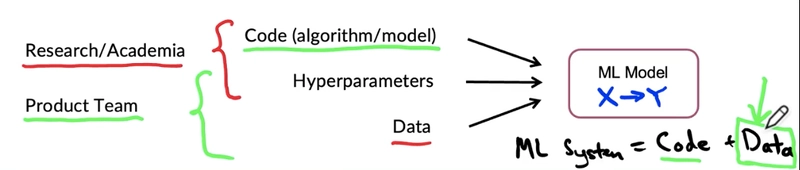
Machine learning in production is a completely different game from training models on your local machine. It’s not just about achieving 95% accuracy on a test set — it’s about building a system that can operate reliably, adapt to real-world inputs, and deliver consistent value to users.
In this post, we'll walk through the end-to-end machine learning development lifecycle, focusing on the key stages and common pitfalls teams face when transitioning from a prototype to a production-ready system.
This framework is structured into four key stages:
Scoping → Data → Modeling → Deployment
Let’s take a closer look at each.
1. Scoping: Define the Problem, Not the Model
Many ML projects fail because teams jump into modeling before they truly understand the problem.
What to focus on:
- Problem Statement: What specific issue are you solving? Is ML even the right tool?
- User Impact: Who are the stakeholders? What is the desired outcome?
- System Design: How will this solution integrate with existing workflows or infrastructure?
This phase is about asking the right questions. For example, if you're building an intent classification model for customer support, think beyond "classify correctly." Consider how the model will handle ambiguity, unseen queries, and evolving language trends.
Tip: Define success not just in terms of accuracy, but also in terms of business value and usability.
2. Data: The Backbone of Any ML System
a) Define Data & Establish a Baseline
You can’t improve what you can’t measure. Start by collecting representative samples of your problem space and build a simple baseline — even rule-based if necessary.
This helps:
- Validate assumptions
- Spot edge cases early
- Set realistic performance expectations
b) Label & Organize Baseline
Labeled data is your fuel. Without a consistent, well-maintained dataset, your model's performance will plateau — or worse, degrade over time.
Best practices:
- Create clear labeling guidelines
- Use tooling to streamline annotation
- Continuously validate your labels with subject matter experts
- Store data in a way that supports versioning and retrieval (e.g., a hybrid SQL/NoSQL system)
Challenge: Data ambiguity is common. Establish processes for resolving conflicting labels and expanding your intent or class taxonomy over time.
3. Modeling: More Than Just Training
a) Select and Train Model
Choose a model architecture based on the nature of your problem, the complexity of the data, and the performance constraints of your system.
Example considerations:
- Sequence models like BiLSTM or Transformers for NLP tasks
- CNNs or ViTs for image classification
- Model inference time if deploying on edge devices
Also consider the ecosystem:
- PyTorch may be preferable for research or flexibility
- TensorFlow may offer better tooling for deployment and mobile
Track:
- Training and validation performance
- Model size and inference time
- Confidence scores for better threshold tuning
b) Perform Error Analysis
Your test accuracy only tells part of the story. Dive deeper:
- What types of examples is your model failing on?
- Are errors consistent across categories or biased toward certain inputs?
- Are false positives or false negatives more costly?
Use confusion matrices, manual review, and feedback data to drive iterative improvements.
Tip: Error analysis is where the real value of experimentation lies. The goal is to uncover why your model behaves the way it does — not just whether it performs well.
4. Deployment: Build for Reality, Not Just for Demo Day
a) Deploy in Production
Serving your model in production comes with trade-offs:
- Latency vs. Accuracy
- Scalability vs. Cost
- Security vs. Accessibility
Common approaches:
- Containerized APIs using FastAPI, Flask, or Django
- Serverless endpoints for lightweight models
- Model serialization with ONNX, TorchScript, or TensorFlow SavedModel
Ensure observability is built in from day one — logs, metrics, and versioning.
b) Monitor and Maintain
Once deployed, models are exposed to data drift, user behavior changes, and edge cases.
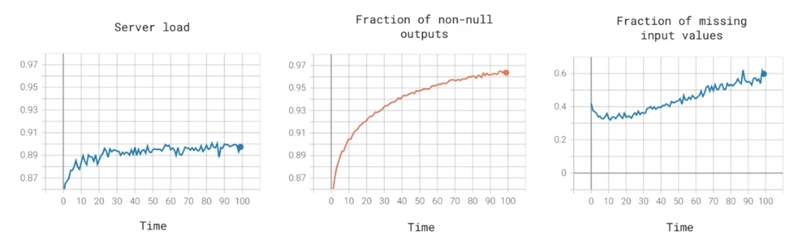
What to monitor:
- Prediction distribution over time
- API latency and error rates
- Confidence score distributions
- Real-time user feedback and corrections
Build pipelines to:
- Flag low-confidence predictions
- Trigger model retraining based on drift
- Track feedback loops for human-in-the-loop retraining
Important: Your model is part of a larger system. Treat monitoring and maintenance as first-class citizens, not afterthoughts.
Summary: ML Lifecycle in Production
| Stage | What to Focus On |
|---|---|
| Scoping | Clear problem definition, integration points, measurable goals |
| Data | High-quality labeling, data pipelines, baseline models |
| Modeling | Framework trade-offs, metric analysis, interpretability |
| Deployment | Secure APIs, monitoring, version control, feedback integration |
Closing Thoughts
Shipping a machine learning system is not a one-time event — it's an ongoing process of learning, adapting, and iterating. The best teams approach this as a system design problem, not just a data science exercise.
By thinking end-to-end — from scoping to deployment — and preparing for the realities of production, you build systems that don’t just work in a notebook, but thrive in the wild.