












































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.png?#)

































_Christophe_Coat_Alamy.jpg?#)
 (1).webp?#)






































































































![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)
![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)





























































































































Semantic Kernel – Parte 03: Embeddings y Retrieval-Augmented Generation (RAG)
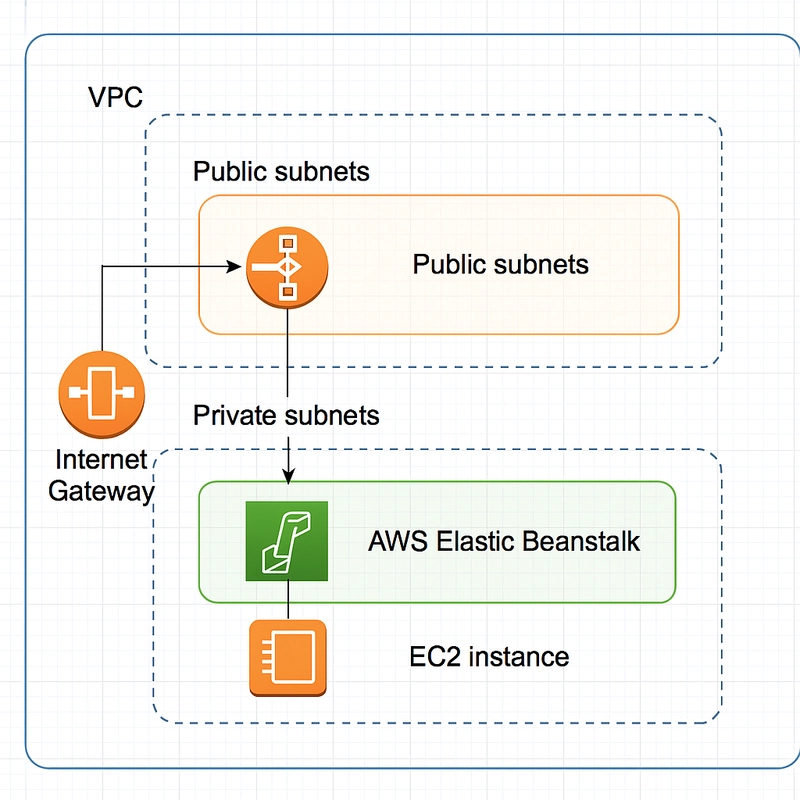
Introducción En esta tercera parte de nuestra serie sobre Semantic Kernel, nos adentramos en la integración de Embeddings y Retrieval-Augmented Generation (RAG) para mejorar la generación de contenido y la recuperación de información. Utilizando herramientas como Ollama para la creación de embeddings y Qdrant como vector store, podemos construir sistemas más inteligentes capaces de generar respuestas más precisas basadas en datos externos y actualizados, en lugar de depender únicamente de los datos con los que fue entrenado el modelo. A través de esta configuración, aprovechamos la sinergia entre el poder de los modelos de lenguaje y la capacidad de búsqueda semántica para proporcionar soluciones más efectivas a las consultas de los usuarios. En este artículo, exploraremos cómo implementar estas tecnologías en Semantic Kernel, con ejemplos prácticos para configurar los servicios y gestionar los embeddings de manera eficiente. ¿Qué son los Embeddings? Los embeddings son representaciones numéricas de texto en un espacio vectorial de alta dimensión. Estas representaciones permiten medir la similitud semántica entre palabras, frases o documentos completos. En el contexto de Semantic Kernel, los embeddings se utilizan para mejorar la búsqueda de información y la generación de respuestas basadas en conocimiento almacenado. Características clave de los Embeddings: Capturan el significado semántico del texto. Permiten encontrar contenido relacionado aunque no se utilicen exactamente las mismas palabras. Se almacenan en bases de datos especializadas llamadas vector stores (como Qdrant). Se generan con modelos de lenguaje avanzados, como los proporcionados por Ollama u Open AI. ¿Qué es RAG (Retrieval-Augmented Generation)? Retrieval-Augmented Generation (RAG) es una técnica que combina la recuperación de información con la generación de respuestas mediante un modelo de lenguaje. En lugar de confiar solo en los datos con los que fue entrenado el modelo, RAG permite buscar información relevante en bases de conocimiento externas y utilizarla para generar respuestas más precisas y actualizadas. Funcionamiento de RAG en Semantic Kernel: Consulta del usuario: Un usuario hace una pregunta o solicitud. Búsqueda semántica: Se generan embeddings de la consulta. Se comparan con los embeddings almacenados en el vector store (Qdrant) para recuperar información relevante. Generación de respuesta: La información recuperada se pasa como contexto al modelo de lenguaje. Se genera una respuesta más precisa y fundamentada en los datos encontrados. Beneficios de RAG en Semantic Kernel: Mejor comprensión de consultas: Permite obtener respuestas relevantes incluso si el usuario no usa palabras exactas. Conocimiento actualizado: Se pueden agregar nuevos datos al sistema sin necesidad de reentrenar el modelo de IA. Optimización del procesamiento: Reduce el costo computacional al recuperar solo la información relevante en lugar de analizar todo el corpus de datos. Configurando Semantic Kernel con Embeddings y un Vector Store En esta sección, configuraremos Semantic Kernel para trabajar con Embeddings y un Vector Store, utilizando Aspire para orquestar los servicios. Los servicios principales que vamos a configurar son: llama3.2: Modelo generador de texto. nomic-embed-text: Modelo generador de embeddings. Qdrant: Almacenamiento y recuperación de embeddings. Aspire: Orquestación y despliegue de los servicios. Configuración de Aspire Aspire nos permite definir y gestionar los servicios necesarios en un solo archivo de configuración. En este caso, configuramos Qdrant como nuestro vector store y llama3.2 y nomic-embed-text como proveedor de embeddings. Nota

Introducción
En esta tercera parte de nuestra serie sobre Semantic Kernel, nos adentramos en la integración de Embeddings y Retrieval-Augmented Generation (RAG) para mejorar la generación de contenido y la recuperación de información. Utilizando herramientas como Ollama para la creación de embeddings y Qdrant como vector store, podemos construir sistemas más inteligentes capaces de generar respuestas más precisas basadas en datos externos y actualizados, en lugar de depender únicamente de los datos con los que fue entrenado el modelo. A través de esta configuración, aprovechamos la sinergia entre el poder de los modelos de lenguaje y la capacidad de búsqueda semántica para proporcionar soluciones más efectivas a las consultas de los usuarios. En este artículo, exploraremos cómo implementar estas tecnologías en Semantic Kernel, con ejemplos prácticos para configurar los servicios y gestionar los embeddings de manera eficiente.
¿Qué son los Embeddings?
Los embeddings son representaciones numéricas de texto en un espacio vectorial de alta dimensión. Estas representaciones permiten medir la similitud semántica entre palabras, frases o documentos completos. En el contexto de Semantic Kernel, los embeddings se utilizan para mejorar la búsqueda de información y la generación de respuestas basadas en conocimiento almacenado.
Características clave de los Embeddings:
- Capturan el significado semántico del texto.
- Permiten encontrar contenido relacionado aunque no se utilicen exactamente las mismas palabras.
- Se almacenan en bases de datos especializadas llamadas vector stores (como Qdrant).
- Se generan con modelos de lenguaje avanzados, como los proporcionados por Ollama u Open AI.
¿Qué es RAG (Retrieval-Augmented Generation)?
Retrieval-Augmented Generation (RAG) es una técnica que combina la recuperación de información con la generación de respuestas mediante un modelo de lenguaje. En lugar de confiar solo en los datos con los que fue entrenado el modelo, RAG permite buscar información relevante en bases de conocimiento externas y utilizarla para generar respuestas más precisas y actualizadas.
Funcionamiento de RAG en Semantic Kernel:
- Consulta del usuario: Un usuario hace una pregunta o solicitud.
-
Búsqueda semántica:
- Se generan embeddings de la consulta.
- Se comparan con los embeddings almacenados en el vector store (Qdrant) para recuperar información relevante.
-
Generación de respuesta:
- La información recuperada se pasa como contexto al modelo de lenguaje.
- Se genera una respuesta más precisa y fundamentada en los datos encontrados.
Beneficios de RAG en Semantic Kernel:
- Mejor comprensión de consultas: Permite obtener respuestas relevantes incluso si el usuario no usa palabras exactas.
- Conocimiento actualizado: Se pueden agregar nuevos datos al sistema sin necesidad de reentrenar el modelo de IA.
- Optimización del procesamiento: Reduce el costo computacional al recuperar solo la información relevante en lugar de analizar todo el corpus de datos.
Configurando Semantic Kernel con Embeddings y un Vector Store
En esta sección, configuraremos Semantic Kernel para trabajar con Embeddings y un Vector Store, utilizando Aspire para orquestar los servicios.
Los servicios principales que vamos a configurar son:
- llama3.2: Modelo generador de texto.
- nomic-embed-text: Modelo generador de embeddings.
- Qdrant: Almacenamiento y recuperación de embeddings.
- Aspire: Orquestación y despliegue de los servicios.
Configuración de Aspire
Aspire nos permite definir y gestionar los servicios necesarios en un solo archivo de configuración. En este caso, configuramos Qdrant como nuestro vector store y llama3.2 y nomic-embed-text como proveedor de embeddings.
Nota



