![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)














































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)







































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)








































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)






































































































![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)





























































































































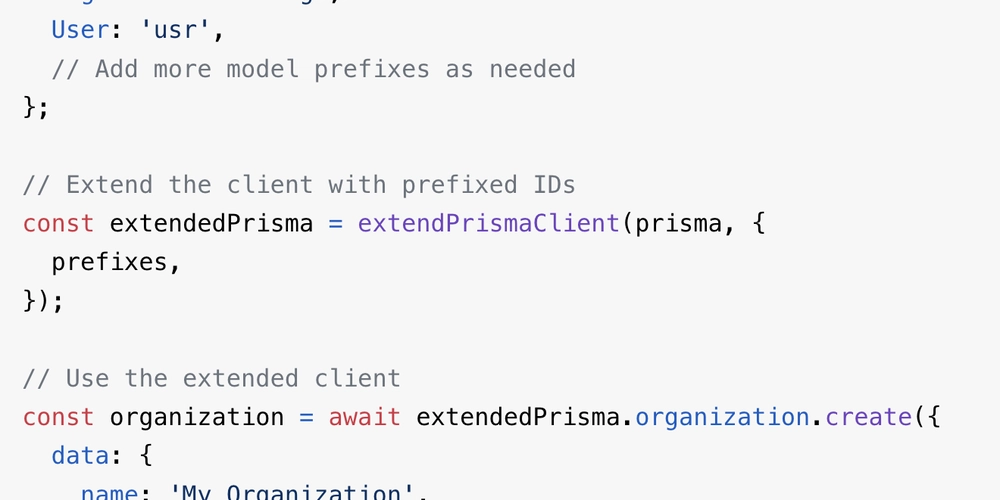
Scikit-learn Essentials for Data science
Introduction Scikit-learn is one of the most popular machine learning libraries for python. It's built on top of NumPy, SciPy, and Matplotlib, making it an efficient and user-friendly toolkit for data analysis, predictive modeling and AI-driven applications. Key Features of Scikit-learn: Simple and efficient tools for data mining and analysis. Built-in algorithms for classification, regression, clustering and more. Support for preprocessing tasks like feature selection, normalization and dimensionality reduction. Extensive documentation and active community to help developers and data scientists. Code import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # Step 1: Generate Sample Data np.random.seed(42) X = np.random.rand(100, 2) # 100 samples, 2 features y = (X[:, 0] + X[:, 1] > 1).astype(int) # Labels based on sum of features # Step 2: Split the Data into Training and Testing Sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Step 3: Standardize the Features scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test) # Step 4: Train the Logistic Regression Model model = LogisticRegression() model.fit(X_train_scaled, y_train) # Step 5: Make Predictions y_pred = model.predict(X_test_scaled) # Step 6: Evaluate the Model accuracy = accuracy_score(y_test, y_pred) print(f"Model Accuracy: {accuracy:.2f}") Explanation: Data Generation: We create random data points and define labels based on a simple rule. Splitting the Dataset: The dataset is divided into training(80%) and testing(20%) parts. Feature Scaling: Standardizing features helps improve the performance of many models. Model Training: We use logistic Regression, a popular algorithm for binary classification. Prediction: After training, the model predicts labels for the test data. Evaluation: We measure how well the model performs using accuracy score.

Introduction
Scikit-learn is one of the most popular machine learning libraries for python. It's built on top of NumPy, SciPy, and Matplotlib, making it an efficient and user-friendly toolkit for data analysis, predictive modeling and AI-driven applications.
Key Features of Scikit-learn:
- Simple and efficient tools for data mining and analysis.
- Built-in algorithms for classification, regression, clustering and more.
- Support for preprocessing tasks like feature selection, normalization and dimensionality reduction.
- Extensive documentation and active community to help developers and data scientists.
Code
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# Step 1: Generate Sample Data
np.random.seed(42)
X = np.random.rand(100, 2) # 100 samples, 2 features
y = (X[:, 0] + X[:, 1] > 1).astype(int) # Labels based on sum of features
# Step 2: Split the Data into Training and Testing Sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Step 3: Standardize the Features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Step 4: Train the Logistic Regression Model
model = LogisticRegression()
model.fit(X_train_scaled, y_train)
# Step 5: Make Predictions
y_pred = model.predict(X_test_scaled)
# Step 6: Evaluate the Model
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy:.2f}")
Explanation:
- Data Generation: We create random data points and define labels based on a simple rule.
- Splitting the Dataset: The dataset is divided into training(80%) and testing(20%) parts.
- Feature Scaling: Standardizing features helps improve the performance of many models.
- Model Training: We use logistic Regression, a popular algorithm for binary classification.
- Prediction: After training, the model predicts labels for the test data.
- Evaluation: We measure how well the model performs using accuracy score.