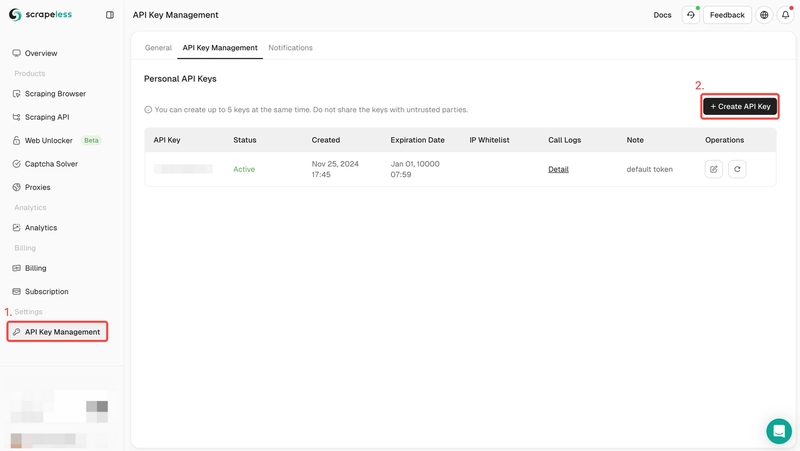
![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.png?#)

































_Christophe_Coat_Alamy.jpg?#)
 (1).webp?#)






































































































![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)
![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)





























































































































Pull GitHub data into Databricks with dbutils
In this blog, we'll show you how to pull GitHub data across several formats into Databricks. This is a frequent request because it allows you to use large existing GitHub datasets for developing and training AI and ML models, enable Unity Catalog to access repositories like US Zip Code data, and work with unstructured data such as JSON logs. By linking GitHub and Databricks, you can improve your workflows and access critical data. The first step is to select the data that you would like to bring into the Databricks environment to analyze. For this example, we will be looking at baby name data. Before starting, you should create a catalog, schema, and volume to pull the data into – this process has been covered in prior blogs. Define your variables You must define your variables before you start the process of pulling in data, because you will reference catalog, schema, and volume to overwrite the GitHub data into your the Databricks Unity Catalog. Additionally, you need the raw link to the GitHub data, which can be generated by selecting 'View Raw' on the GitHub page, and copying the contents of your address bar. The code for defining your variables should look like the following: # Define the variables you are going to use to save the Github data to Unity Catalog # Before starting, you can create the catalog, etc. in the UI or with SQL code # For download_url, go to GitHub file you would like to download, select view raw, copy address from address bar catalog = "github_catalog" schema = "github_schema" volume = "github_volume" download_url = "https://raw.githubusercontent.com/dxdc/babynames/refs/heads/main/all-names.csv" file_name = "github_new_baby_names.csv" table_name = "github_table" path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume path_table = catalog + "." + schema print(path_table) # Show the complete path print(path_volume) # Show the complete path Import GitHub to DataBricks utilizing dbutils Databricks Utilities (dbutils) are utilities that provide commands that enable you to work with your Databricks environment from notebooks. The commands are wide ranging but we will focus on the module dbutils.fs which covers the utilities that are used for accessing the Databricks File System. To write the GitHub csv to Unity Catalog, utilize the following code: # Import the CSV file from Github into your Unity Catalog Volume utilizing the Databricks dbutils command dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}") The f" strings in the above provide a concise way to embed expresisons and variables directly into strings, replacing str.format(). You can read more about f-strings in Python here. The .fs.cp module and command serve to copy the file to the specified volume with the specified file name. Load volume to dataframe and table in Unity Catalog As a next step, you need to convert the volume data into a dataframe so it can subsequently be converted back into a table in Unity Catalog. At this point, we could drop columns or change headers as needed, but the data we are utilizing for this example does not require any adjustments. df = spark.read.csv(f"{path_volume}/{file_name}", header=True, inferSchema=True, sep=",") Note that we are using a CSV here, but several other file formats are supported by the spark.read command, including JSON, txt, Parquet, ORC< XML, Avro, and more. Before saving the dataframe to Unity Catalog, you should review the headers, and data and check for anything that needs to be cleansed. display(df) df.describe() f_count = df.filter(df.sex == 'F').count() print(f_count) m_count = df.filter(df.sex == 'M').count() print(m_count) total_count = df.count() print(total_count) check_total_count = "ERROR: The total count does not match the sum of the female and male counts" if f_count + m_count - total_count == 0 else f_count + m_count - total_count print(check_total_count) Add Links at the Bottom for References and Additional Learning https://sparkbyexamples.com/spark/spark-read-options/

In this blog, we'll show you how to pull GitHub data across several formats into Databricks. This is a frequent request because it allows you to use large existing GitHub datasets for developing and training AI and ML models, enable Unity Catalog to access repositories like US Zip Code data, and work with unstructured data such as JSON logs. By linking GitHub and Databricks, you can improve your workflows and access critical data.
The first step is to select the data that you would like to bring into the Databricks environment to analyze. For this example, we will be looking at baby name data. Before starting, you should create a catalog, schema, and volume to pull the data into – this process has been covered in prior blogs.
Define your variables
You must define your variables before you start the process of pulling in data, because you will reference catalog, schema, and volume to overwrite the GitHub data into your the Databricks Unity Catalog. Additionally, you need the raw link to the GitHub data, which can be generated by selecting 'View Raw' on the GitHub page, and copying the contents of your address bar. The code for defining your variables should look like the following:
# Define the variables you are going to use to save the Github data to Unity Catalog
# Before starting, you can create the catalog, etc. in the UI or with SQL code
# For download_url, go to GitHub file you would like to download, select view raw, copy address from address bar
catalog = "github_catalog"
schema = "github_schema"
volume = "github_volume"
download_url = "https://raw.githubusercontent.com/dxdc/babynames/refs/heads/main/all-names.csv"
file_name = "github_new_baby_names.csv"
table_name = "github_table"
path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume
path_table = catalog + "." + schema
print(path_table) # Show the complete path
print(path_volume) # Show the complete path
Import GitHub to DataBricks utilizing dbutils
Databricks Utilities (dbutils) are utilities that provide commands that enable you to work with your Databricks environment from notebooks. The commands are wide ranging but we will focus on the module dbutils.fs which covers the utilities that are used for accessing the Databricks File System. To write the GitHub csv to Unity Catalog, utilize the following code:
# Import the CSV file from Github into your Unity Catalog Volume utilizing the Databricks dbutils command
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")
The f" strings in the above provide a concise way to embed expresisons and variables directly into strings, replacing str.format(). You can read more about f-strings in Python here. The .fs.cp module and command serve to copy the file to the specified volume with the specified file name.
Load volume to dataframe and table in Unity Catalog
As a next step, you need to convert the volume data into a dataframe so it can subsequently be converted back into a table in Unity Catalog. At this point, we could drop columns or change headers as needed, but the data we are utilizing for this example does not require any adjustments.
df = spark.read.csv(f"{path_volume}/{file_name}",
header=True,
inferSchema=True,
sep=",")
Note that we are using a CSV here, but several other file formats are supported by the spark.read command, including JSON, txt, Parquet, ORC< XML, Avro, and more.
Before saving the dataframe to Unity Catalog, you should review the headers, and data and check for anything that needs to be cleansed.
display(df)
df.describe()
f_count = df.filter(df.sex == 'F').count()
print(f_count)
m_count = df.filter(df.sex == 'M').count()
print(m_count)
total_count = df.count()
print(total_count)
check_total_count = "ERROR: The total count does not match the sum of the female and male counts" if f_count + m_count - total_count == 0 else f_count + m_count - total_count
print(check_total_count)
Add Links at the Bottom for References and Additional Learning
https://sparkbyexamples.com/spark/spark-read-options/