



























![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)













































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)








































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)








































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


























































































![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)





























































































































Overview of Voice Cloning
Over the last week, I've been experimenting with ElevenLabs' voice cloning service, and I'm genuinely amazed at what modern AI can accomplish. With just two minutes of my own recorded speech, I was able to generate synthetic audio that captured my voice with remarkable accuracy, intonation, rhythm, and vocal characteristics were uncannily similar to my own. ElevenLabs has established itself as a pioneer in AI audio research, making content accessible across 32 languages while powering everything from audiobooks and video games to critical accessibility applications. As I explored their platform, I became fascinated by a fundamental question: how do these systems learn to mimic a unique voice from such minimal input? Let's unpack the technology behind this seemingly magical capability, breaking down the components that work together to clone human voices. Voice cloning systems transform the way we interact with synthetic speech by allowing machines to speak with customized, human-like voices after analyzing just seconds of audio. Understanding how this technology works reveals both its complexity and elegance. Core Components and Process Modern voice cloning operates through three interconnected modules working in harmony: 1. Feature Encoder The journey begins with a reference audio clip—typically 10-30 seconds of someone speaking. The Speaker Encoder analyzes this sample to extract a "voice fingerprint" or speaker embedding. This compact vector (usually 128-512 dimensions) captures the essence of a voice: its timbre, pitch characteristics, accent patterns, and vocal resonance. Advanced systems use deep neural networks like ECAPA-TDNN or ResNet architectures trained through contrastive learning techniques. These networks excel at differentiating speakers while maintaining consistency across various utterances from the same person. 2. Acoustic Model The Acoustic Model bridges linguistic content with vocal identity. It takes two inputs: processed text (representing what to say) and the speaker embedding (representing how to say it). Text processing begins with normalization and grapheme-to-phoneme conversion, mapping written language to phonetic representations. This linguistic information combines with the speaker embedding to generate intermediate representations—typically mel spectrograms that encode frequency, amplitude, and timing information. The most effective acoustic models implement attention mechanisms that help align linguistic features with the appropriate timing and emphasis patterns characteristic of natural speech. 3. Vocoder The final component transforms abstract audio representations into actual sound waves. Neural vocoders like HiFi-GAN or WaveGlow have revolutionized this step, replacing traditional signal processing methods with neural networks that generate high-fidelity audio. These vocoders create realistic speech by synthesizing subtle features like breath noises, mouth movements, and room acoustics. Modern architectures operate in parallel rather than sequentially, enabling generation speeds hundreds of times faster than real-time playback. Technical Innovations Enabling Few-Shot Learning Voice cloning's ability to work with minimal samples relies on transfer learning principles. By pre-training on thousands of speakers, these systems develop a universal understanding of speech mechanics, requiring only a small adaptation to capture a new voice's unique characteristics. Additional techniques like data augmentation artificially expand the limited reference audio through controlled manipulations, while speaker disentanglement methods separate content from style, allowing seamless application of voice characteristics to any text input. For developers implementing these systems, the tradeoffs typically involve balancing computational efficiency, audio quality, and the amount of reference audio needed for convincing results.
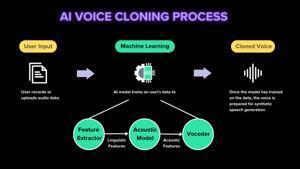
Over the last week, I've been experimenting with ElevenLabs' voice cloning service, and I'm genuinely amazed at what modern AI can accomplish. With just two minutes of my own recorded speech, I was able to generate synthetic audio that captured my voice with remarkable accuracy, intonation, rhythm, and vocal characteristics were uncannily similar to my own. ElevenLabs has established itself as a pioneer in AI audio research, making content accessible across 32 languages while powering everything from audiobooks and video games to critical accessibility applications. As I explored their platform, I became fascinated by a fundamental question: how do these systems learn to mimic a unique voice from such minimal input? Let's unpack the technology behind this seemingly magical capability, breaking down the components that work together to clone human voices.
Voice cloning systems transform the way we interact with synthetic speech by allowing machines to speak with customized, human-like voices after analyzing just seconds of audio. Understanding how this technology works reveals both its complexity and elegance.
Core Components and Process
Modern voice cloning operates through three interconnected modules working in harmony:
1. Feature Encoder
The journey begins with a reference audio clip—typically 10-30 seconds of someone speaking. The Speaker Encoder analyzes this sample to extract a "voice fingerprint" or speaker embedding. This compact vector (usually 128-512 dimensions) captures the essence of a voice: its timbre, pitch characteristics, accent patterns, and vocal resonance.
Advanced systems use deep neural networks like ECAPA-TDNN or ResNet architectures trained through contrastive learning techniques. These networks excel at differentiating speakers while maintaining consistency across various utterances from the same person.
2. Acoustic Model
The Acoustic Model bridges linguistic content with vocal identity. It takes two inputs: processed text (representing what to say) and the speaker embedding (representing how to say it).
Text processing begins with normalization and grapheme-to-phoneme conversion, mapping written language to phonetic representations. This linguistic information combines with the speaker embedding to generate intermediate representations—typically mel spectrograms that encode frequency, amplitude, and timing information.
The most effective acoustic models implement attention mechanisms that help align linguistic features with the appropriate timing and emphasis patterns characteristic of natural speech.
3. Vocoder
The final component transforms abstract audio representations into actual sound waves. Neural vocoders like HiFi-GAN or WaveGlow have revolutionized this step, replacing traditional signal processing methods with neural networks that generate high-fidelity audio.
These vocoders create realistic speech by synthesizing subtle features like breath noises, mouth movements, and room acoustics. Modern architectures operate in parallel rather than sequentially, enabling generation speeds hundreds of times faster than real-time playback.
Technical Innovations Enabling Few-Shot Learning
Voice cloning's ability to work with minimal samples relies on transfer learning principles. By pre-training on thousands of speakers, these systems develop a universal understanding of speech mechanics, requiring only a small adaptation to capture a new voice's unique characteristics.
Additional techniques like data augmentation artificially expand the limited reference audio through controlled manipulations, while speaker disentanglement methods separate content from style, allowing seamless application of voice characteristics to any text input.
For developers implementing these systems, the tradeoffs typically involve balancing computational efficiency, audio quality, and the amount of reference audio needed for convincing results.


