![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)
















































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)







































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)









































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
























































































![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)
































































































































MCP+Database: A New Approach with Better Retrieval Effects Than RAG!
In recent years, Large Language Models (LLMs) have demonstrated impressive capabilities in natural language processing tasks. However, the limitations of these models, such as outdated knowledge and the generation of hallucinations, have prompted researchers to develop various enhancement techniques. Among these, Model Context Protocol (MCP) and Retrieval-Augmented Generation (RAG) are two important concepts. MCP is indeed a very significant technical standard that can help us solve many previously difficult problems. Therefore, in today's tutorial, I will start with a practical case to discuss MCP with you. Before we start learning, let's first understand the current limitations of RAG technology. Background: Limitations of RAG RAG, or Retrieval-Augmented Generation, is currently a popular direction in the field of large models. It combines information retrieval technology with generative models to address the challenges faced by large models in terms of knowledge accuracy, contextual understanding, and the utilization of the latest information. However, many people may have some misunderstandings about RAG, believing that as long as we import some additional knowledge through RAG, the model can perfectly master and answer questions related to this knowledge. But the reality and imagination are quite different. You may find after actual attempts that the accuracy of RAG does not seem to be that good. From the perspective of the technical principles of RAG itself, the following problems currently exist: Insufficient Retrieval Accuracy: First and foremost, the core of RAG is to first convert knowledge into "vectors", import them into a "vector database", then convert the user's input information into "vectors", then match similar "vectors" in the vector database, and finally have the large model summarize the retrieved content. Incomplete Generated Content: Since RAG processes slices of documents, and the locality of these slices means it cannot see the information of the entire document, the answers are generally incomplete when answering questions such as "list XXX" or "summarize XXX". Lack of a Holistic View: RAG cannot determine how many slices are needed to answer a question, nor can it determine the connections between documents. For example, in legal provisions, new interpretations may override old ones, but RAG cannot determine which is the latest. Weak Multi-Turn Retrieval Ability: RAG lacks the ability to perform multi-turn, multi-query retrieval, which is essential for reasoning tasks. Although some newly emerging technologies, such as GraphRAG and KAG, can solve these problems to some extent, they are still immature, and current RAG technology is far from reaching the expected results. Theory: Understanding the Basics of MCP Before we start learning about MCP, there is an unavoidable topic: Function Call. Let's understand it first. Function Call In the past, AI large models were like knowledgeable individuals trapped in a room, only able to answer questions based on their existing knowledge, unable to directly access real-time data or interact with external systems. For example, they could not directly access the latest information in a database, nor could they use external tools to complete specific tasks. Function Call is a very important concept introduced by OPEN AI in 2023: Function Call essentially provides large models with the ability to interact with external systems, similar to installing a "plug-in toolbox" for the models. When a large model encounters a question it cannot directly answer, it will proactively call predefined functions (such as querying the weather, calculating data, accessing a database, etc.) to obtain real-time or accurate information before generating a response. This capability is indeed quite good, giving large models more possibilities. However, it has a significant drawback: the implementation cost is too high. Before the emergence of MCP, the cost for developers to implement Function Call was relatively high. First, the model itself needed to stably support the invocation of Function Call. If we chose certain models that indicated they did not support plug-in invocation, this actually meant they did not support Function Call. This also means that the model itself needs to undergo specialized fine-tuning for Function Call invocation to stably support this capability. Another major problem is that when OPEN AI first proposed this technology, it did not intend for it to become a standard. Therefore, although many subsequent models also supported Function Call invocation, their respective implementation methods were quite different. This means that if we want to develop a Function Call tool, we need to adapt it to different models, including parameter formats, triggering logic, return structures, etc., which is a very high cost. This greatly increased the development threshold of AI Agents. Therefore, in th

In recent years, Large Language Models (LLMs) have demonstrated impressive capabilities in natural language processing tasks. However, the limitations of these models, such as outdated knowledge and the generation of hallucinations, have prompted researchers to develop various enhancement techniques. Among these, Model Context Protocol (MCP) and Retrieval-Augmented Generation (RAG) are two important concepts. MCP is indeed a very significant technical standard that can help us solve many previously difficult problems. Therefore, in today's tutorial, I will start with a practical case to discuss MCP with you.
Before we start learning, let's first understand the current limitations of RAG technology.
Background: Limitations of RAG
RAG, or Retrieval-Augmented Generation, is currently a popular direction in the field of large models. It combines information retrieval technology with generative models to address the challenges faced by large models in terms of knowledge accuracy, contextual understanding, and the utilization of the latest information.
However, many people may have some misunderstandings about RAG, believing that as long as we import some additional knowledge through RAG, the model can perfectly master and answer questions related to this knowledge. But the reality and imagination are quite different. You may find after actual attempts that the accuracy of RAG does not seem to be that good.
From the perspective of the technical principles of RAG itself, the following problems currently exist:
- Insufficient Retrieval Accuracy: First and foremost, the core of RAG is to first convert knowledge into "vectors", import them into a "vector database", then convert the user's input information into "vectors", then match similar "vectors" in the vector database, and finally have the large model summarize the retrieved content.
- Incomplete Generated Content: Since RAG processes slices of documents, and the locality of these slices means it cannot see the information of the entire document, the answers are generally incomplete when answering questions such as "list XXX" or "summarize XXX".
- Lack of a Holistic View: RAG cannot determine how many slices are needed to answer a question, nor can it determine the connections between documents. For example, in legal provisions, new interpretations may override old ones, but RAG cannot determine which is the latest.
- Weak Multi-Turn Retrieval Ability: RAG lacks the ability to perform multi-turn, multi-query retrieval, which is essential for reasoning tasks.
Although some newly emerging technologies, such as GraphRAG and KAG, can solve these problems to some extent, they are still immature, and current RAG technology is far from reaching the expected results.
Theory: Understanding the Basics of MCP
Before we start learning about MCP, there is an unavoidable topic: Function Call. Let's understand it first.
Function Call
In the past, AI large models were like knowledgeable individuals trapped in a room, only able to answer questions based on their existing knowledge, unable to directly access real-time data or interact with external systems. For example, they could not directly access the latest information in a database, nor could they use external tools to complete specific tasks.
Function Call is a very important concept introduced by OPEN AI in 2023:
Function Call essentially provides large models with the ability to interact with external systems, similar to installing a "plug-in toolbox" for the models. When a large model encounters a question it cannot directly answer, it will proactively call predefined functions (such as querying the weather, calculating data, accessing a database, etc.) to obtain real-time or accurate information before generating a response.
This capability is indeed quite good, giving large models more possibilities. However, it has a significant drawback: the implementation cost is too high.
Before the emergence of MCP, the cost for developers to implement Function Call was relatively high. First, the model itself needed to stably support the invocation of Function Call. If we chose certain models that indicated they did not support plug-in invocation, this actually meant they did not support Function Call.
This also means that the model itself needs to undergo specialized fine-tuning for Function Call invocation to stably support this capability.
Another major problem is that when OPEN AI first proposed this technology, it did not intend for it to become a standard. Therefore, although many subsequent models also supported Function Call invocation, their respective implementation methods were quite different.
This means that if we want to develop a Function Call tool, we need to adapt it to different models, including parameter formats, triggering logic, return structures, etc., which is a very high cost.
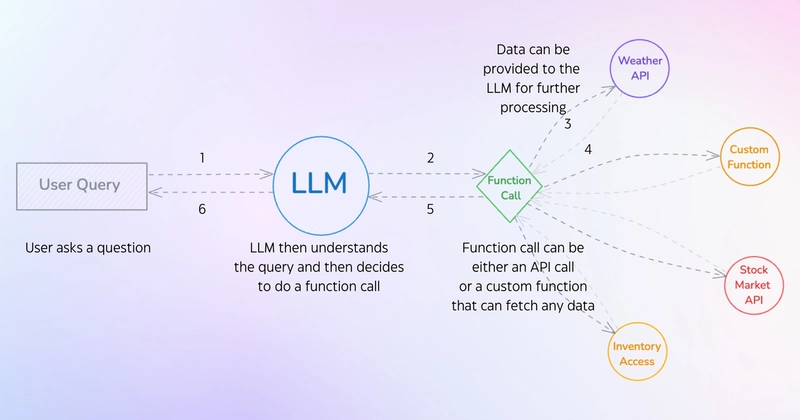
This greatly increased the development threshold of AI Agents. Therefore, in the past, we could mostly only build Agents through platforms like Dify and Wordware.
MCP
MCP (Model Context Protocol) is an open standard protocol introduced by Anthropic (the company that developed the Claude model), with the aim of solving the difficult problem of interaction between AI models and external data sources and tools.
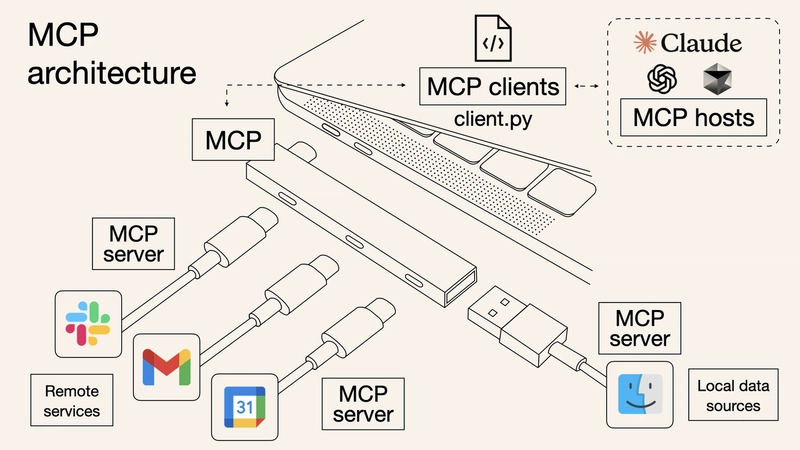
With Function Call, every time a model needs to connect to a new data source or use a new tool, developers have to write a large amount of code specifically for integration, which is both troublesome and error-prone. The emergence of MCP is to solve these problems. It is like a "universal plug" or "USB interface" that establishes unified specifications. Whether connecting to databases, third-party APIs, or local files and other external resources, it can all be done through this "universal interface", making the interaction between AI models and external tools or data sources more standardized and reusable.
When it was first introduced, only the Claude client supported it, and people didn't pay much attention to it. However, due to the support of Cursor (everyone understands the relationship between Cursor and Claude), various plug-ins and tools also began to provide support one after another. In addition, the recent hype surrounding AI Agents by the "conceptual" tool Manus has gradually brought MCP into the public eye. Until recently, OPEN AI also announced support for MCP.

This made me truly realize that MCP has indeed succeeded; it has become the "industry standard" for AI tool invocation.
MCP Hosts, such as Claude Desktop and Cursor, internally implement the MCP Client. The MCP Client then interacts with the MCP Server through the standard MCP protocol. The MCP Server, provided by various third-party developers, is responsible for implementing the logic for interacting with various third-party resources, such as accessing databases, browsers, and local files. Finally, it returns the results to the MCP Client through the standard MCP protocol, which are then displayed on the MCP Host.
Developers develop according to the MCP protocol without having to repeatedly write adaptation code for connecting each model to different resources, which can greatly save development workload. In addition, the already developed MCP Servers, because the protocol is universal, can be directly opened for everyone to use, which greatly reduces the repetitive work of developers.
For example, if you want to develop a plug-in with the same logic, you don't need to write it once in Cursor and then again in Dify. If they both support MCP, you can directly use the same plug-in logic.
Practice: Learning the Basic Usage of MCP
To use MCP technology, the first step is to find a client that supports the MCP protocol, then find an MCP server that meets your needs, and then invoke these services in the MCP client.
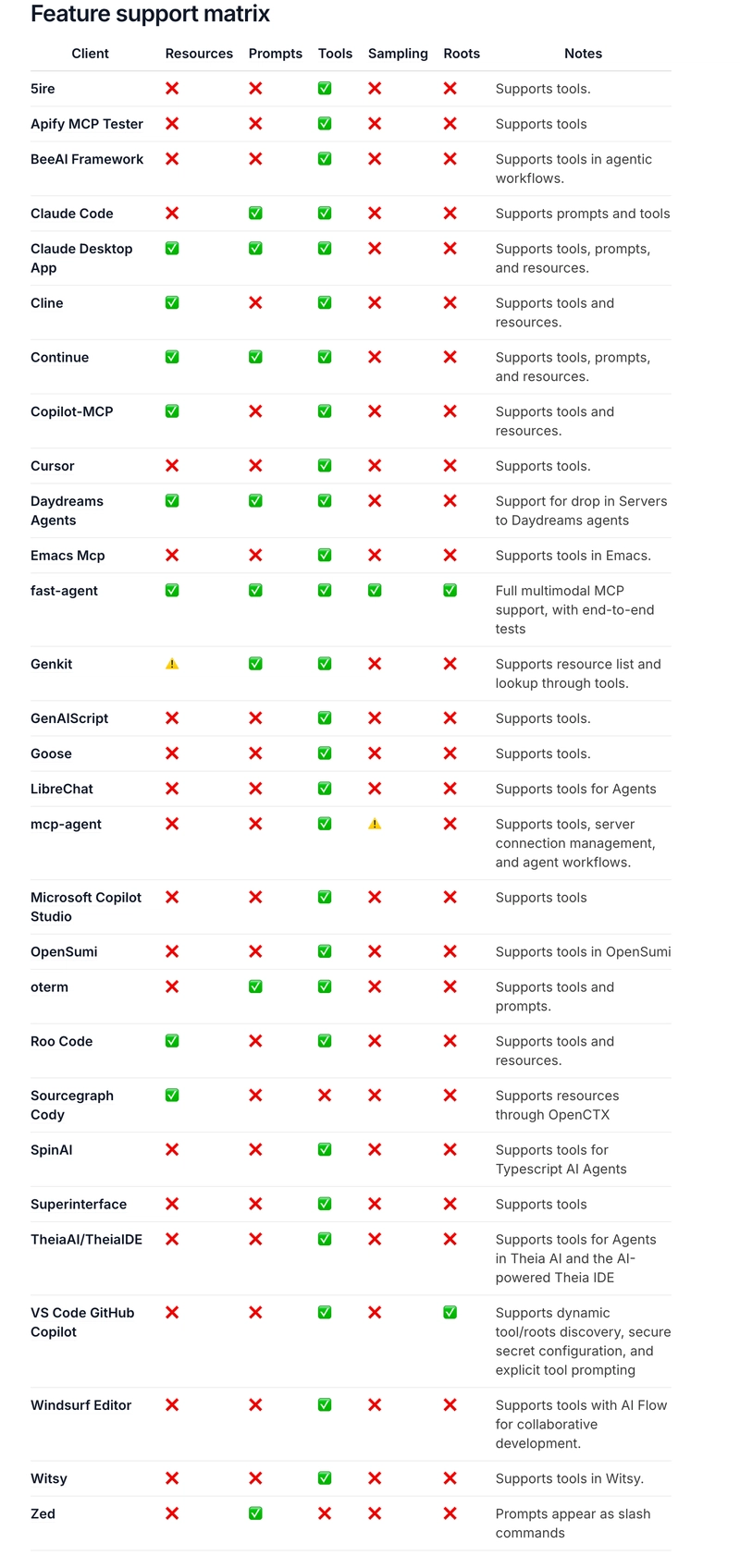
From the table, we can see that MCP divides the capabilities supported by clients into five categories. We will briefly understand them here:
- Tools: Servers expose executable functions for LLMs to invoke to interact with external systems.
- Resources: Servers expose data and content for clients to read and use as LLM context.
- Prompts: Servers define reusable prompt templates to guide LLM interactions.
- Sampling: Allows servers to initiate completion requests to LLMs through clients, enabling complex intelligent behaviors.
- Roots: Some addresses specified by the client to the server to tell the server which resources to pay attention to and where to find them.
Currently, the most commonly used and widely supported is the Tools (tool invocation) capability.
For the MCP-supported tools mentioned above, they can be roughly divided into the following categories:
- AI Chat Tools: Such as 5ire, LibreChat, Cherry Studio
- AI Coding Tools: Such as Cursor, Windsurf, Cline
- AI Development Frameworks: Such as Genkit, GenAIScript, BeeAI
MCP Server
The official description of MCP Server is: A lightweight program, each exposing specific functionality through the standardized Model Context Protocol.
Simply put, it interacts with clients through a standardized protocol, enabling models to invoke specific data sources or tool functions. Common MCP Servers include:
- File and Data Access: Enables large models to operate and access local files or databases, such as File System MCP Server.
- Web Automation: Enables large models to operate browsers, such as Pupteer MCP Server.
- Third-Party Tool Integration: Enables large models to call APIs exposed by third-party platforms, such as Gaode Map MCP Server.
Here are some ways to find the MCP Server you need:
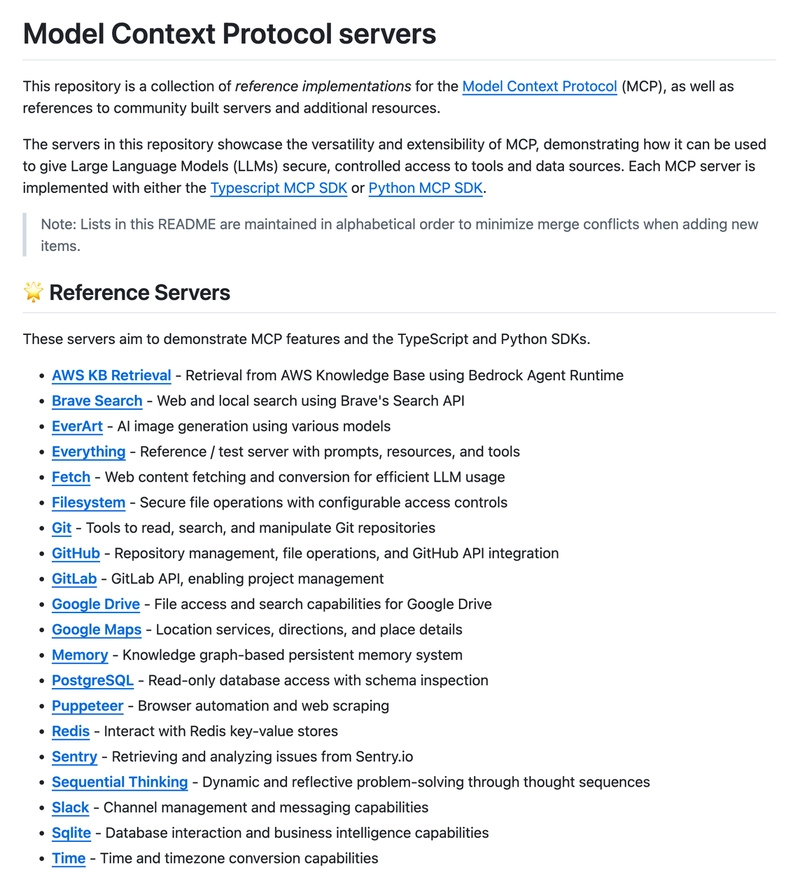
The first is the official MCP Server collection on Github (https://github.com/modelcontextprotocol/servers), which includes MCP Servers as official reference examples, MCP Servers integrated by the official team, and some community-developed third-party MCP Servers:
Another one is MCP.so (https://mcp.so/): a third-party MCP Server aggregation platform that currently includes over 5000 MCP Servers:
It provides a very user-friendly display method, with specific configuration examples for each MCP Server:

MCP Market (https://mcpmarket.com/), with good access speed, allows filtering by tool type:

Hands-on: Using MCP to Call a Database
ServBay+Mongodb
First, for the convenience of demonstration, let's construct a simple database example.
Here, we choose MongoDB: a popular open-source document database. MongoDB uses a document data model, and data is stored in JSON format.
Why choose MongoDB instead of relational databases like SQLite? The main reason is that in relational databases, the table structure is fixed. Adding new fields or modifying the table structure often requires complex migration operations. MongoDB's document data model allows storing documents with different structures in the same collection. Applications can flexibly add or modify fields as needed without having to define strict table structures in advance. This is very friendly for scenarios where we want to build a continuously supplemented structured knowledge base.
Here, we use ServBay to deploy MongoDB. ServBay is a development environment management platform that provides rich database suite support, covering SQL and NoSQL databases, including MySQL, MariaDB, PostgreSQL, MongoDB, Redis, and Memcached.
For beginners, installing MongoDB with ServBay is very convenient. Just click to download without having to consider other things. You can even use ServBay to deploy local LLMs.
You can directly download and install ServBay from the official website: https://www.servbay.com
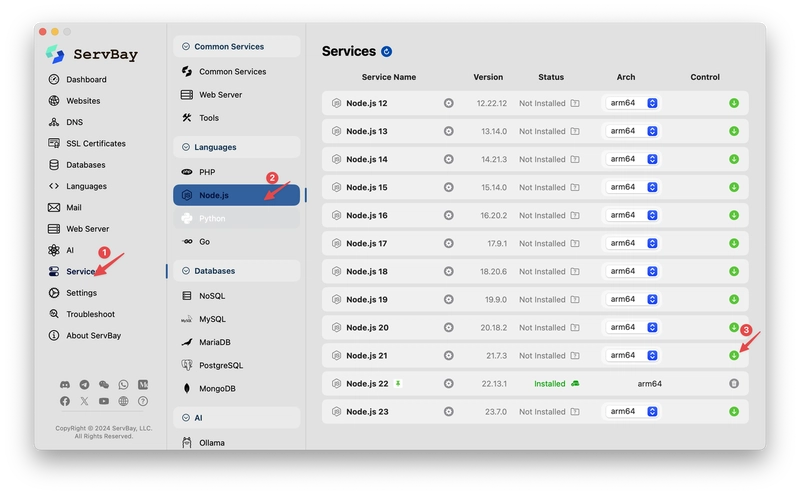
After downloading, go to "Services" on the left, find the MongoDB option under the database section, and click to download the desired version.
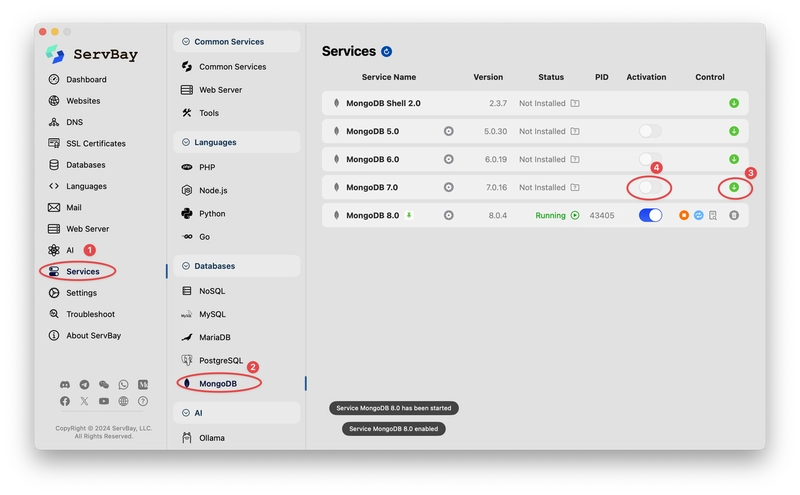
After installation, it will listen on our local port 27017 by default.

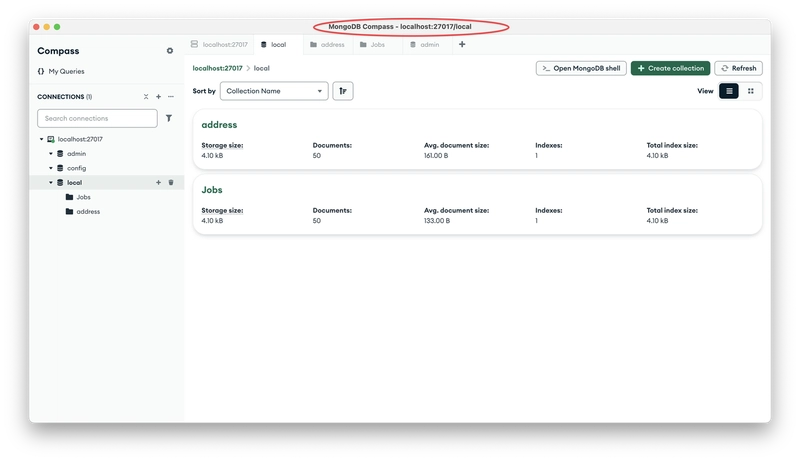
Then, to visualize the data, we also need to install MongoDB Compass (a local GUI visualization tool provided by MongoDB).
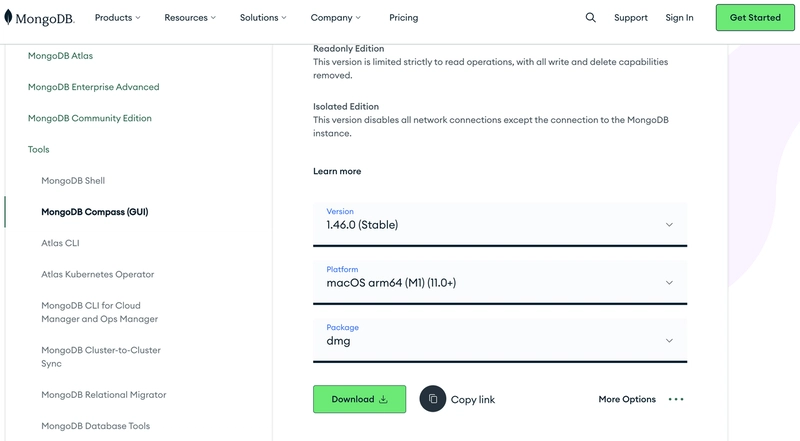
Download address: https://www.mongodb.com/try/download/compass
After installation, we connect to the local MongoDB Server through the MongoDB Compass client.
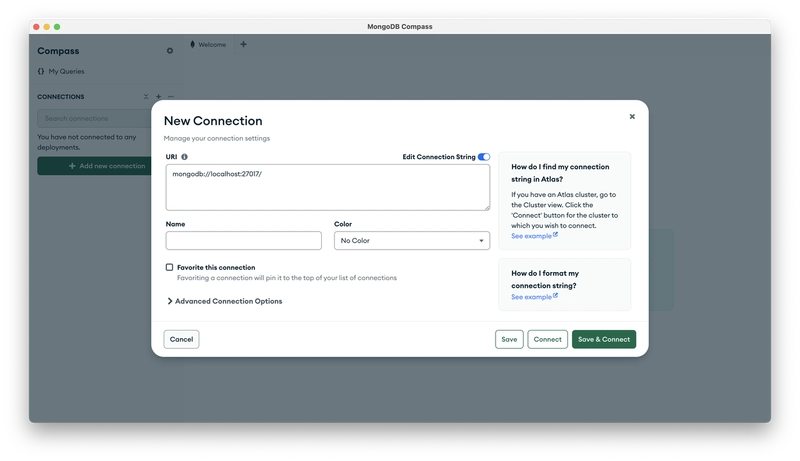
Subsequently, you can import your data into the MongoDB database through the client.
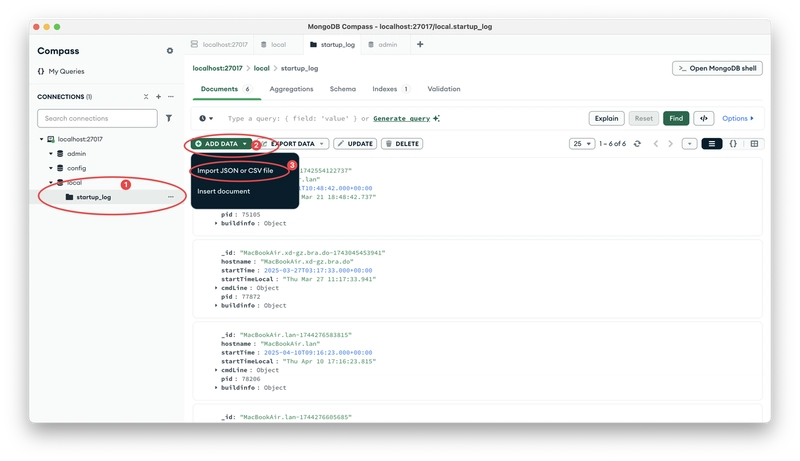
In the following example, we will use student information data for demonstration. Assume our data is like this:
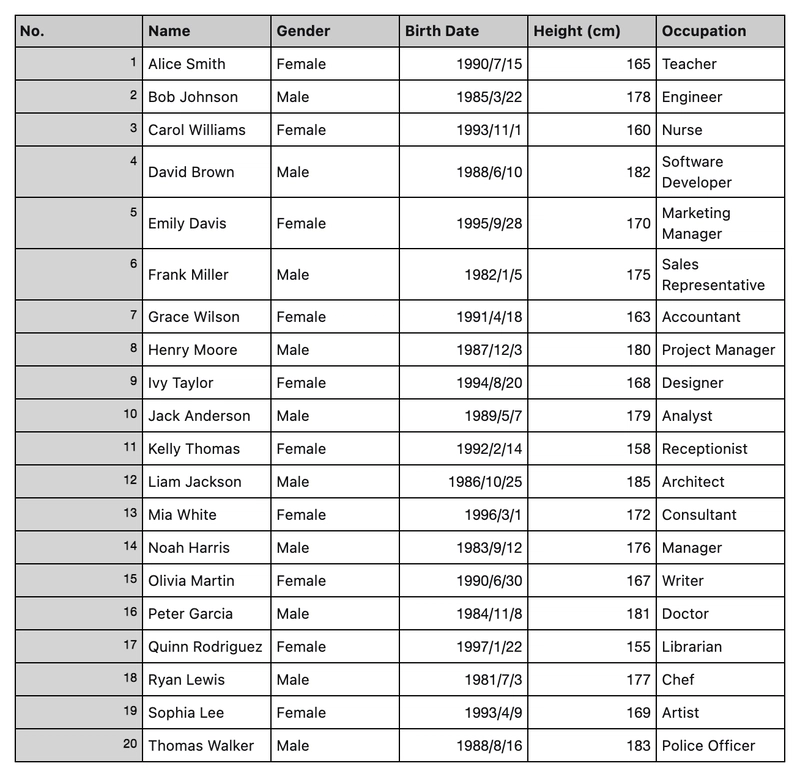
If you don't know how to import into MongoDB, you can use AI to help you write the import script and then follow the AI prompts to import.
Prompt: Help me write a script that can import the data in the current table into my local MongoDB database. The database name is datamanagement.
Then, run the script according to the AI prompts to import. The effect after successful import.
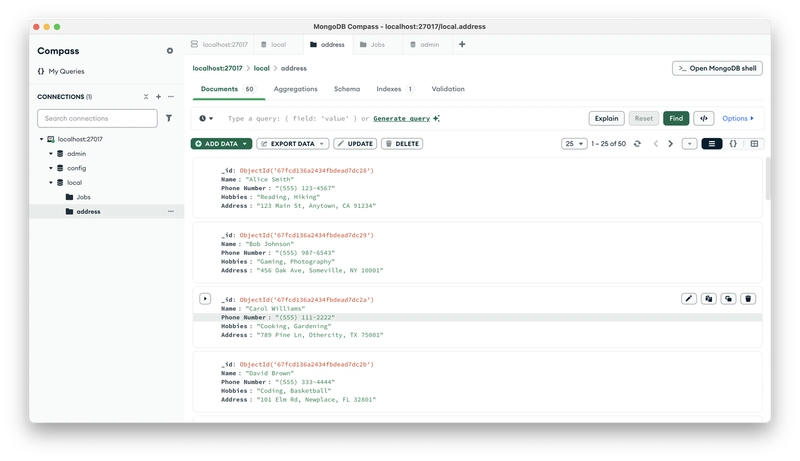
VSCode+Cline
We choose Cline for configuration. Cline is an AI coding assistant plugin based on VS Code. It is completely open source and directly provided as a VS Code plugin, supporting the configuration of various third-party AI APIs, making it very flexible. Therefore, if you are an AI programming beginner, it is also recommended to use VS Code + Cline for getting started.
The installation of Cline is also relatively simple. Directly search for Cline in the VS Code extension marketplace and click install after finding it (note that there are many unofficial versions, just install the one with the most downloads):
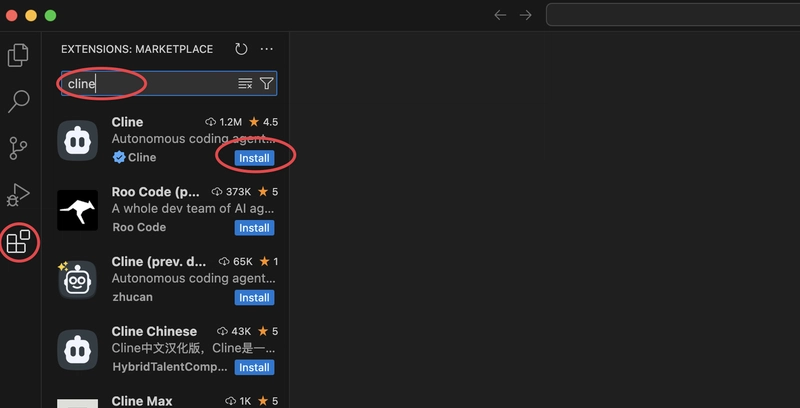
After installation, find the Cline icon in the left sidebar, click to open the settings, and then configure the model. It supports various model providers; you can choose as needed.
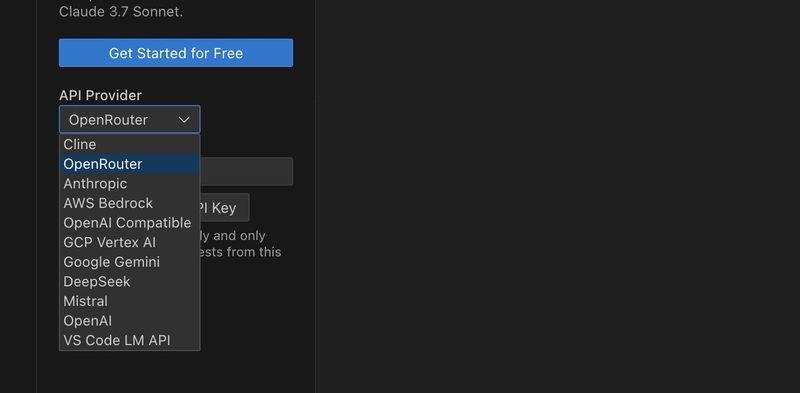
After the model configuration is complete, we can test it in the chat window. If it outputs normally, it means the configuration is successful.
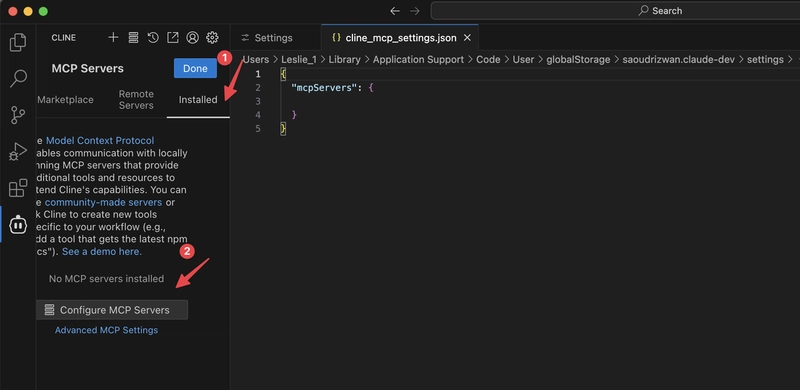
Configure mcp-mongo-server
Next, we need to find an MCP Server that supports MongoDB. There are many online; here, I choose mcp-mongo-server.
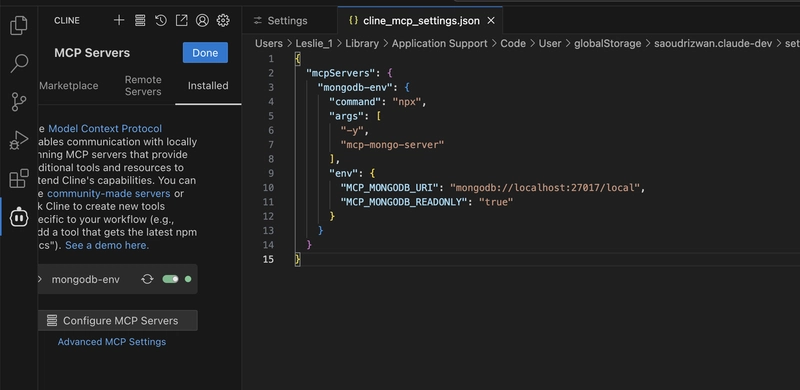
Open VS Code, click the installed tab, and then click Configure MCP Servers at the bottom. You will find that a JSON file opens, which is where Cline stores the MCP configuration. It initially contains only an empty object.
We copy the code command provided on Github and change MCP_MONGODB_URI to our own MongoDB address.
Paste this configuration into Cline's MCP configuration file. Then, we see the mongodb green light on the left turn on, indicating successful configuration.
Note that we need to use the npx command here, which requires you to have a Node.js environment on your computer. You can download and install it with one click from ServBay.
Then, let's test the effect.
We ask a question about counting the number of females: How many females are there in total?
Then, we find that the chat window automatically recognizes that this question requires calling MCP and asks if we allow calling the mongodb MCP. We click allow.
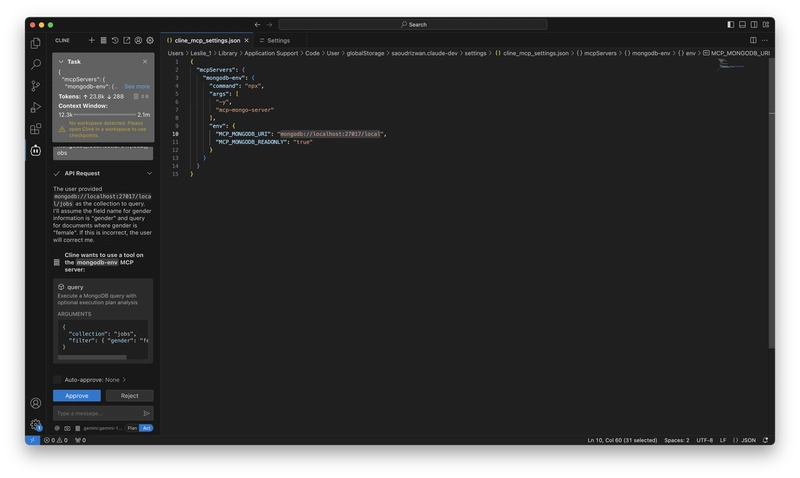
Then, MCP accurately queried the result from the database and provided the answer.
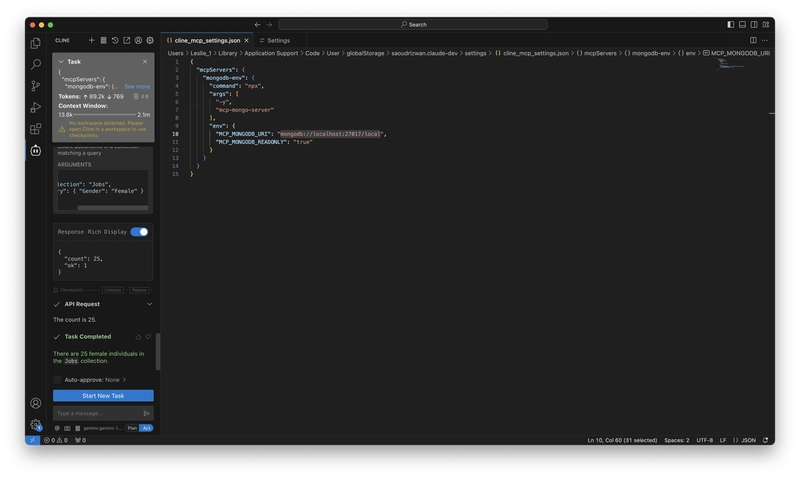
Then we ask a slightly more complex question: How many males are there whose occupation is bus driver?
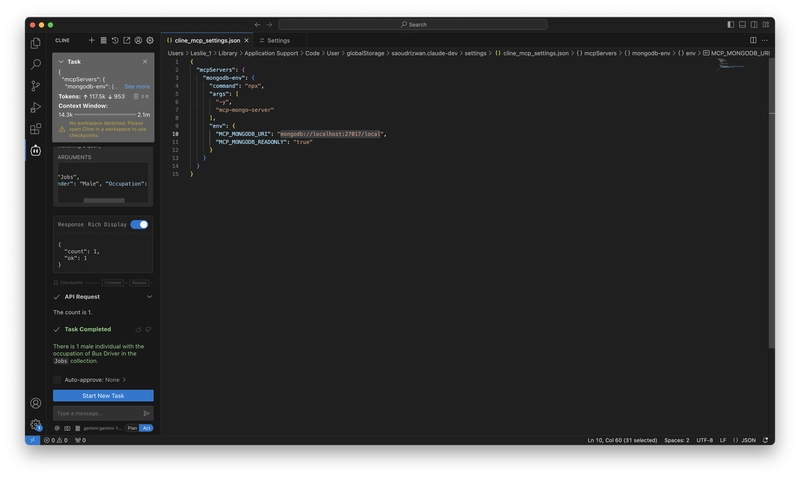
The model still gave the correct answer.
Current Limitations
Since MCP technology is just emerging, many aspects are still immature, and this solution currently has certain limitations:
- Avoid letting AI retrieve excessively large amounts of data. Unlike RAG, which only retrieves a small portion of the needed content each time, this method actually executes SQL. The amount of data you query is the amount of data retrieved. If the query returns a large amount of data at once, it will consume a large number of tokens and may even freeze the MCP client.
- Many MCP clients rely on a large number of system prompts to communicate with MCP tools. Therefore, once MCP is used, the token consumption will definitely increase significantly.
However, the future is promising. Before this, there were actually some similar capabilities based on Function Call + Text2SQL, and I have tried them, but they did not become popular due to development costs and accuracy recovery issues.
The MCP + database approach we learned together today truly reduces development costs, even to zero code, and the accuracy is very high. I believe it will definitely become a very popular query method in the future and should replace traditional RAG methods in structured data retrieval scenarios such as intelligent customer service, warehouse management, and information management.