












































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.png?#)

































_Christophe_Coat_Alamy.jpg?#)
 (1).webp?#)






































































































![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)
![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)





























































































































Llama 4 Unleashed: Revolutionizing AI with Multimodal Models and Massive Context Windows
Hey Dev.to community! As a tech enthusiast and content writer, I’m thrilled to dive into Meta’s latest bombshell: the Llama 4 release. This isn’t just another update—it’s a game-changer for AI developers everywhere. With Llama 4 Scout and Llama 4 Maverick hitting the scene, we’re talking natively multimodal models, insane context lengths, and an open-weight approach that’s got the open-source crowd buzzing. Let’s unpack this beast of an announcement and see what it means for you, the builders of tomorrow’s AI. The Big Reveal: What’s Llama 4 Bringing to the Table? Artificial intelligence is moving fast, and Meta’s Llama 4 suite is leading the charge. These models—Llama 4 Scout and Llama 4 Maverick—are built from the ground up to handle text, images, and more, all while packing some seriously efficient architecture. Oh, and they’re open-weight, so you can grab them right now and start tinkering. Here’s the lowdown: Llama 4 Scout: Small but Mighty Specs: 17 billion active parameters, 16 experts. Fit: Squeezes into a single NVIDIA H100 GPU. Superpower: A jaw-dropping 10 million token context window—perfect for crunching huge datasets, summarizing multiple docs, or diving deep into codebases. Performance: Outshines Gemma 3, Mistral 3.1, and Gemini 2.0 Flash-Lite on benchmarks. Yep, it’s a compact contender. Llama 4 Maverick: The Multimodal Maestro Specs: 17 billion active parameters, 128 experts. Fit: Runs on a single H100 host. Superpower: Best-in-class multimodal capabilities, excelling at text and image tasks like nobody’s business. Performance: Trades blows with GPT-4o and Gemini 2.0 Flash, matches DeepSeek v3 on reasoning and coding—all with fewer active parameters. Plus, it’s got an ELO score of 1417 on LMArena’s experimental chat version. Both models owe their smarts to Llama 4 Behemoth, a 288 billion active parameter beast still in training. Behemoth’s already outpacing GPT-4.5 and Claude Sonnet 3.7 on STEM benchmarks, and it’s the “teacher” distilling its wisdom into Scout and Maverick. More on that later. Technical Goodies: What’s Under the Hood? Alright, let’s geek out a bit. Llama 4’s got some cutting-edge tech that’ll make any developer’s heart race. Mixture-of-Experts (MoE) Magic How it Works: Only a fraction of parameters activate per token, making these models lean and mean. Maverick, for example, has 400 billion total parameters but only uses 17 billion at a time. Why It Matters: Lower serving costs, faster inference—think efficient deployment without breaking the bank. Multimodal from Birth Early Fusion: Text and vision tokens blend seamlessly from the start, trained on a massive mix of text, images, and video. Payoff: Scout nails image grounding (pinpointing objects in pics), while Maverick crushes sophisticated AI apps needing text-image synergy. Training Like Champs Scale: Over 30 trillion tokens—double Llama 3’s haul—across text, images, and video. Precision: FP8 training hit 390 TFLOPs/GPU on 32K GPUs for Behemoth. That’s raw power, optimized for efficiency. Techniques: Lightweight supervised fine-tuning (SFT), online reinforcement learning (RL), and direct preference optimization (DPO) keep these models sharp and chatty. Benchmark Bragging Rights Numbers don’t lie, and Llama 4’s got plenty to flex: Scout: Beats Gemma 3 and Mistral 3.1 hands-down. Maverick: Holds its own against GPT-4o and Gemini 2.0 Flash, rivals DeepSeek v3 with half the active parameters. Behemoth: Still training, but already topping GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on STEM tasks like MATH-500 and GPQA Diamond. These models aren’t just fast—they’re smart, efficient, and ready to tackle real-world dev challenges. Open Source Love: Accessibility for All Meta’s doubling down on openness, and that’s music to the Dev.to crowd’s ears. Llama 4 Scout and Maverick are up for grabs on llama.com and Hugging Face. No gatekeeping here—just pure, downloadable AI goodness. This isn’t just good for you; it’s a win for the whole ecosystem, sparking innovation across the board. Plus, you can test Meta AI built with Llama 4 on WhatsApp, Messenger, Instagram Direct, and Meta.AI. Keeping It Safe and Fair Power like this needs guardrails, and Meta’s on it: Safety: Data filtering, Llama Guard, Prompt Guard, and red-teaming keep risks in check. Bias: Llama 4’s refusal rate on debated topics dropped from 7% (Llama 3.3) to under 2%, with a balanced approach rivaling Grok. It’s not perfect, but it’s progress. Your Turn: Build with Llama 4 So, what’s next? Get your hands on Llama 4 Scout and Maverick and start experimenting! Whether you’re crafting a chatbot, analyzing massive codebases, or blending text and visuals in wild new ways, these models are your playground. The 10M-token context window alone opens doors to projects we’ve only dream
Hey Dev.to community! As a tech enthusiast and content writer, I’m thrilled to dive into Meta’s latest bombshell: the Llama 4 release. This isn’t just another update—it’s a game-changer for AI developers everywhere. With Llama 4 Scout and Llama 4 Maverick hitting the scene, we’re talking natively multimodal models, insane context lengths, and an open-weight approach that’s got the open-source crowd buzzing. Let’s unpack this beast of an announcement and see what it means for you, the builders of tomorrow’s AI.
The Big Reveal: What’s Llama 4 Bringing to the Table?
Artificial intelligence is moving fast, and Meta’s Llama 4 suite is leading the charge. These models—Llama 4 Scout and Llama 4 Maverick—are built from the ground up to handle text, images, and more, all while packing some seriously efficient architecture. Oh, and they’re open-weight, so you can grab them right now and start tinkering. Here’s the lowdown:
Llama 4 Scout: Small but Mighty
- Specs: 17 billion active parameters, 16 experts.
- Fit: Squeezes into a single NVIDIA H100 GPU.
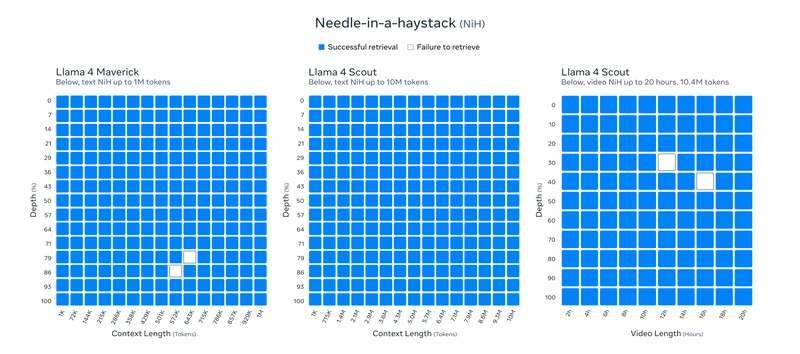
- Superpower: A jaw-dropping 10 million token context window—perfect for crunching huge datasets, summarizing multiple docs, or diving deep into codebases.
- Performance: Outshines Gemma 3, Mistral 3.1, and Gemini 2.0 Flash-Lite on benchmarks. Yep, it’s a compact contender.
Llama 4 Maverick: The Multimodal Maestro
- Specs: 17 billion active parameters, 128 experts.
- Fit: Runs on a single H100 host.
- Superpower: Best-in-class multimodal capabilities, excelling at text and image tasks like nobody’s business.
- Performance: Trades blows with GPT-4o and Gemini 2.0 Flash, matches DeepSeek v3 on reasoning and coding—all with fewer active parameters. Plus, it’s got an ELO score of 1417 on LMArena’s experimental chat version.
Both models owe their smarts to Llama 4 Behemoth, a 288 billion active parameter beast still in training. Behemoth’s already outpacing GPT-4.5 and Claude Sonnet 3.7 on STEM benchmarks, and it’s the “teacher” distilling its wisdom into Scout and Maverick. More on that later.
Technical Goodies: What’s Under the Hood?
Alright, let’s geek out a bit. Llama 4’s got some cutting-edge tech that’ll make any developer’s heart race.
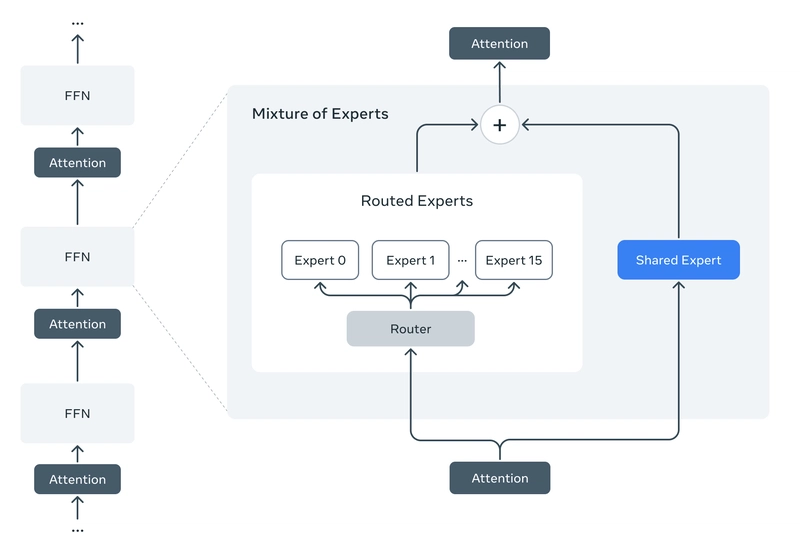
Mixture-of-Experts (MoE) Magic
- How it Works: Only a fraction of parameters activate per token, making these models lean and mean. Maverick, for example, has 400 billion total parameters but only uses 17 billion at a time.
- Why It Matters: Lower serving costs, faster inference—think efficient deployment without breaking the bank.
Multimodal from Birth
- Early Fusion: Text and vision tokens blend seamlessly from the start, trained on a massive mix of text, images, and video.
- Payoff: Scout nails image grounding (pinpointing objects in pics), while Maverick crushes sophisticated AI apps needing text-image synergy.
Training Like Champs
- Scale: Over 30 trillion tokens—double Llama 3’s haul—across text, images, and video.
- Precision: FP8 training hit 390 TFLOPs/GPU on 32K GPUs for Behemoth. That’s raw power, optimized for efficiency.
- Techniques: Lightweight supervised fine-tuning (SFT), online reinforcement learning (RL), and direct preference optimization (DPO) keep these models sharp and chatty.
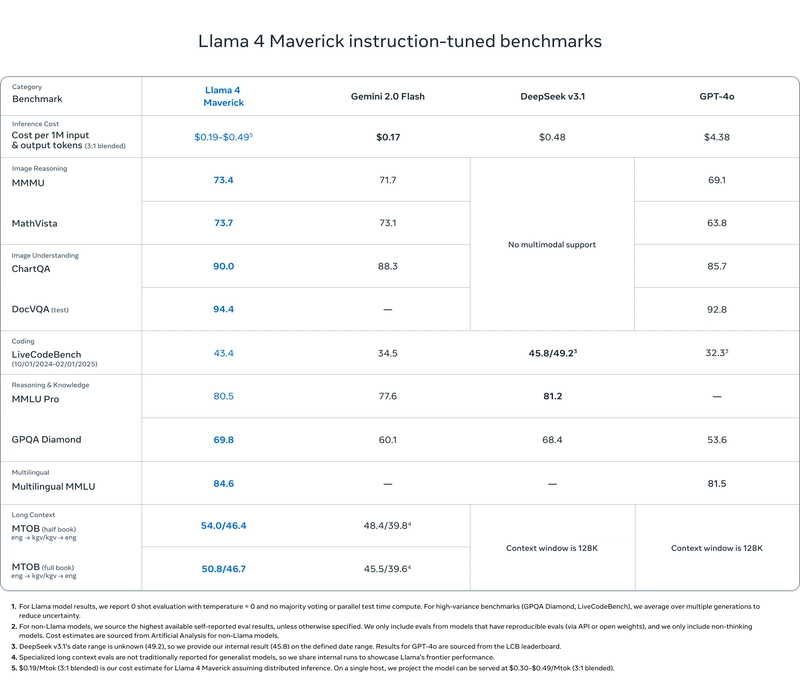
Benchmark Bragging Rights
Numbers don’t lie, and Llama 4’s got plenty to flex:
- Scout: Beats Gemma 3 and Mistral 3.1 hands-down.
- Maverick: Holds its own against GPT-4o and Gemini 2.0 Flash, rivals DeepSeek v3 with half the active parameters.
- Behemoth: Still training, but already topping GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on STEM tasks like MATH-500 and GPQA Diamond.
These models aren’t just fast—they’re smart, efficient, and ready to tackle real-world dev challenges.
Open Source Love: Accessibility for All
Meta’s doubling down on openness, and that’s music to the Dev.to crowd’s ears. Llama 4 Scout and Maverick are up for grabs on llama.com and Hugging Face. No gatekeeping here—just pure, downloadable AI goodness. This isn’t just good for you; it’s a win for the whole ecosystem, sparking innovation across the board. Plus, you can test Meta AI built with Llama 4 on WhatsApp, Messenger, Instagram Direct, and Meta.AI.
Keeping It Safe and Fair
Power like this needs guardrails, and Meta’s on it:
- Safety: Data filtering, Llama Guard, Prompt Guard, and red-teaming keep risks in check.
- Bias: Llama 4’s refusal rate on debated topics dropped from 7% (Llama 3.3) to under 2%, with a balanced approach rivaling Grok. It’s not perfect, but it’s progress.
Your Turn: Build with Llama 4
So, what’s next? Get your hands on Llama 4 Scout and Maverick and start experimenting! Whether you’re crafting a chatbot, analyzing massive codebases, or blending text and visuals in wild new ways, these models are your playground. The 10M-token context window alone opens doors to projects we’ve only dreamed of. And with the open-weight approach, you’re not just a user—you’re a co-creator in this AI revolution.
Download them now on llama.com or Hugging Face, and let’s see what you build. Share your projects in the comments—I’m pumped to geek out over your creations!
Big thanks to Meta’s partners fueling this release: Accenture, AWS, AMD, Arm, CentML, Cerebras, CloudFlare, Databricks, Deepinfra, DeepLearning.AI, Dell, Deloitte, Fireworks AI, Google Cloud, Groq, Hugging Face, IBM Watsonx, Infosys, Intel, Kaggle, Mediatek, Microsoft Azure, Nebius, NVIDIA, ollama, Oracle Cloud, PwC, Qualcomm, Red Hat, SambaNova, Sarvam AI, Scale AI, Scaleway, Snowflake, TensorWave, Together AI, vLLM, and Wipro.



