![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)

































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)













































.jpg?#)































































.png?#)


(1).jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)






























_NicoElNino_Alamy.png?#)
_Igor_Mojzes_Alamy.jpg?#)

.webp?#)
.webp?#)










































































































![Blackmagic Design Unveils DaVinci Resolve 20 With Over 100 New Features and AI Tools [Video]](https://www.iclarified.com/images/news/96951/96951/96951-640.jpg)


![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)
























































































































Llama 4 Herd Released: Comparison with Claude 3.7 Sonnet, GPT-4.5, and Gemini 2.5, and more!
Meta has recently released the Llama 4 Herd. This announcement includes three models: Llama 4 Scout (lightweight), Llama 4 Maverick, and Llama 4 Behemoth (most powerful). Each model is designed for specific uses and aims to compete with GPT-4o, GPT-4.5, Claude 3.7 Sonnet, and Gemini 2.0/2.5 Pro. You can immediately download Llama 4 Scout and Maverick from llama.com and Hugging Face. However, Behemoth, which has an impressive 288 billion active parameters and almost 2 trillion total parameters, is still in training. Meta expects it to set new standards in STEM fields once it is complete. You might be curious about how Llama 4 compares to other models based on these numbers. Let's answer that question in this article. We discuss the Llama 4 Herd release and compare it with other advanced models, including Claude 3.7 Sonnet, Gemini 2.5/2.0, and GPT-4.5/4-o. We also share our thoughts on how well the new models might perform for coding tasks. Llama 4 Model Details and Specifications The Llama 4 Herd comprises three models. Each model uses a Mixture-of-Experts (MoE) architecture. This design activates only a subset of parameters per token, optimizing computational efficiency without sacrificing performance. Here’s a detailed breakdown of the specifications and use cases of each: Llama 4 Scout Parameters: 17 billion active, 109 billion total Experts: 16 Context Window: 10 million tokens Hardware: Fits on a single NVIDIA H100 GPU (80GB) Training Data: Pre-trained on 30 trillion tokens, including text, images, videos, and over 200 languages Post-Training: Lightweight Supervised Fine-Tuning (SFT), online Reinforcement Learning (RL), and Direct Preference Optimization (DPO) Purpose: Designed for efficiency and accessibility, Scout excels in tasks requiring long-context processing, such as summarizing entire books, analyzing massive codebases, or handling multimodal inputs like diagrams and text. Llama 4 Maverick Parameters: 17 billion active, 400 billion total Experts: 128 Context Window: 10 million tokens Hardware: Requires multiple GPUs (e.g., 2-4 H100s depending on workload) Training Data: Same 30 trillion token corpus as Scout, with a heavier emphasis on multimodal data Post-Training: Enhanced SFT, RL, and DPO for superior general-purpose performance Purpose: The workhorse of the herd, Maverick shines in general-use scenarios, including advanced image and text understanding, making it ideal for complex reasoning and creative tasks. Llama 4 Behemoth (In Training) Parameters: 288 billion active, nearly 2 trillion total Experts: Undisclosed (likely hundreds) Context Window: Expected to exceed 10 million tokens Hardware: Requires a large-scale cluster (specifics TBD) Training Data: Likely exceeds 50 trillion tokens, with a focus on STEM-specific datasets Projected Performance: Meta claims Behemoth will outperform GPT-4.5 and Claude 3.7 Sonnet on STEM benchmarks, though details remain speculative until release. The training corpus—double that of Llama 3’s 15 trillion tokens—incorporates diverse modalities and languages, enabling natively multimodal capabilities. Post-training techniques like DPO refine response accuracy, reducing hallucinations and improving alignment with user intent, as detailed in the Hugging Face model card. Llama 4 Comparison with Proprietary Models Here’s a glance at Llama 4 comparison with proprietary models like: Gemini 2.5 Pro: Strengths: Leads in reasoning (GPQA: 84.0) and coding (LiveCodeBench: 70.4), with a 1M token context and multimodal versatility. Gemini 2.5 vs. Llama 4: Outperforms Scout and Maverick in raw scores but lacks their 10M token context; Behemoth may close the gap. Claude 3.7 Sonnet: Strengths: Excels in coding (SWE-Bench: 70.3) and safety, with hybrid reasoning modes; strong in science (GPQA: 84.8). Claude 3.7 Sonnet vs. Llama 4: Competitive with Maverick in coding, but smaller context (200K) limits long-form tasks; Behemoth may surpass it. ChatGPT (GPT-4.5): Strengths: Builds on GPT-4o’s multimodal prowess (HumanEval: 90.2) and conversational fluency, with top-tier scores (~89 MMLU). GPT-4.5 vs. Llama 4: Outshines Scout and Maverick in general performance; Behemoth’s scale and open-source edge could challenge it. Llama 4 Benchmark Performance Meta’s extensive benchmarking, published in the model card, provides a clear picture of Llama 4’s capabilities. Below are the results for pre-trained and instruction-tuned variants, followed by detailed comparison sections. Larger pre-trained Llama 3.1 models generally outperform smaller versions and show competitive results with Llama 4 in reasoning and knowledge benchmarks. Llama 4 Maverick leads in code generation. Multilingual performance is similar across Llama models. In image tasks, only Llama 4 models were assessed, demonstrating strong capabilities in both chart and document understanding. Here’s what things look like when comparing the Llama 4 class with Gemini, Claude and GPT: Instruction-tuned models show
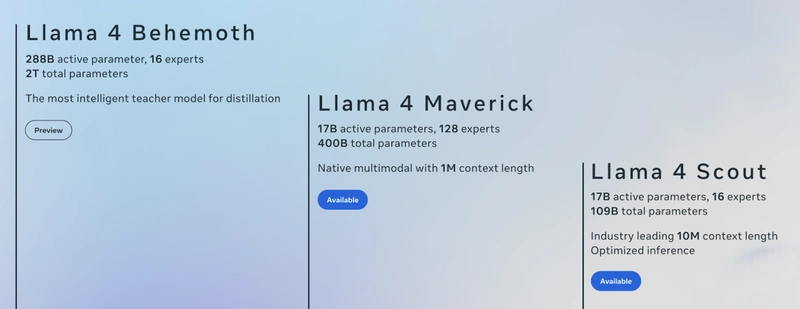
Meta has recently released the Llama 4 Herd. This announcement includes three models: Llama 4 Scout (lightweight), Llama 4 Maverick, and Llama 4 Behemoth (most powerful). Each model is designed for specific uses and aims to compete with GPT-4o, GPT-4.5, Claude 3.7 Sonnet, and Gemini 2.0/2.5 Pro. You can immediately download Llama 4 Scout and Maverick from llama.com and Hugging Face. However, Behemoth, which has an impressive 288 billion active parameters and almost 2 trillion total parameters, is still in training. Meta expects it to set new standards in STEM fields once it is complete. You might be curious about how Llama 4 compares to other models based on these numbers.
Let's answer that question in this article. We discuss the Llama 4 Herd release and compare it with other advanced models, including Claude 3.7 Sonnet, Gemini 2.5/2.0, and GPT-4.5/4-o. We also share our thoughts on how well the new models might perform for coding tasks.
Llama 4 Model Details and Specifications
The Llama 4 Herd comprises three models. Each model uses a Mixture-of-Experts (MoE) architecture. This design activates only a subset of parameters per token, optimizing computational efficiency without sacrificing performance. Here’s a detailed breakdown of the specifications and use cases of each:
Llama 4 Scout
Parameters: 17 billion active, 109 billion total
Experts: 16
Context Window: 10 million tokens
Hardware: Fits on a single NVIDIA H100 GPU (80GB)
Training Data: Pre-trained on 30 trillion tokens, including text, images, videos, and over 200 languages
Post-Training: Lightweight Supervised Fine-Tuning (SFT), online Reinforcement Learning (RL), and Direct Preference Optimization (DPO)
Purpose: Designed for efficiency and accessibility, Scout excels in tasks requiring long-context processing, such as summarizing entire books, analyzing massive codebases, or handling multimodal inputs like diagrams and text.
Llama 4 Maverick
Parameters: 17 billion active, 400 billion total
Experts: 128
Context Window: 10 million tokens
Hardware: Requires multiple GPUs (e.g., 2-4 H100s depending on workload)
Training Data: Same 30 trillion token corpus as Scout, with a heavier emphasis on multimodal data
Post-Training: Enhanced SFT, RL, and DPO for superior general-purpose performance
Purpose: The workhorse of the herd, Maverick shines in general-use scenarios, including advanced image and text understanding, making it ideal for complex reasoning and creative tasks.
Llama 4 Behemoth (In Training)
Parameters: 288 billion active, nearly 2 trillion total
Experts: Undisclosed (likely hundreds)
Context Window: Expected to exceed 10 million tokens
Hardware: Requires a large-scale cluster (specifics TBD)
Training Data: Likely exceeds 50 trillion tokens, with a focus on STEM-specific datasets
Projected Performance: Meta claims Behemoth will outperform GPT-4.5 and Claude 3.7 Sonnet on STEM benchmarks, though details remain speculative until release.
The training corpus—double that of Llama 3’s 15 trillion tokens—incorporates diverse modalities and languages, enabling natively multimodal capabilities. Post-training techniques like DPO refine response accuracy, reducing hallucinations and improving alignment with user intent, as detailed in the Hugging Face model card.
Llama 4 Comparison with Proprietary Models
Here’s a glance at Llama 4 comparison with proprietary models like:
Gemini 2.5 Pro:
Strengths: Leads in reasoning (GPQA: 84.0) and coding (LiveCodeBench: 70.4), with a 1M token context and multimodal versatility.
Gemini 2.5 vs. Llama 4: Outperforms Scout and Maverick in raw scores but lacks their 10M token context; Behemoth may close the gap.
Claude 3.7 Sonnet:
Strengths: Excels in coding (SWE-Bench: 70.3) and safety, with hybrid reasoning modes; strong in science (GPQA: 84.8).
Claude 3.7 Sonnet vs. Llama 4: Competitive with Maverick in coding, but smaller context (200K) limits long-form tasks; Behemoth may surpass it.
ChatGPT (GPT-4.5):
Strengths: Builds on GPT-4o’s multimodal prowess (HumanEval: 90.2) and conversational fluency, with top-tier scores (~89 MMLU).
GPT-4.5 vs. Llama 4: Outshines Scout and Maverick in general performance; Behemoth’s scale and open-source edge could challenge it.
Llama 4 Benchmark Performance
Meta’s extensive benchmarking, published in the model card, provides a clear picture of Llama 4’s capabilities. Below are the results for pre-trained and instruction-tuned variants, followed by detailed comparison sections.
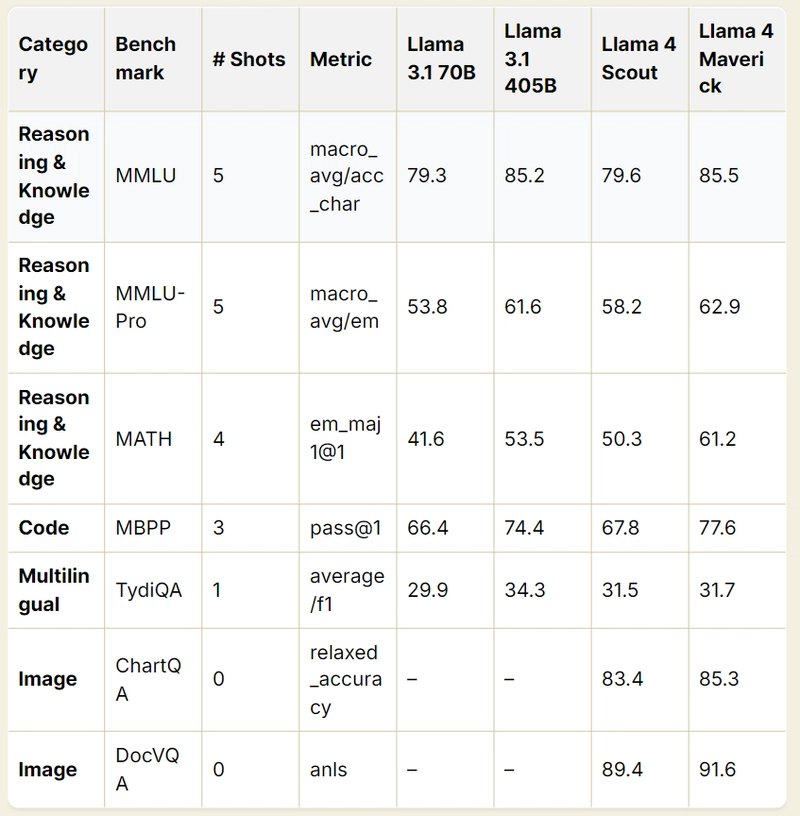
Larger pre-trained Llama 3.1 models generally outperform smaller versions and show competitive results with Llama 4 in reasoning and knowledge benchmarks. Llama 4 Maverick leads in code generation. Multilingual performance is similar across Llama models. In image tasks, only Llama 4 models were assessed, demonstrating strong capabilities in both chart and document understanding.
Here’s what things look like when comparing the Llama 4 class with Gemini, Claude and GPT:
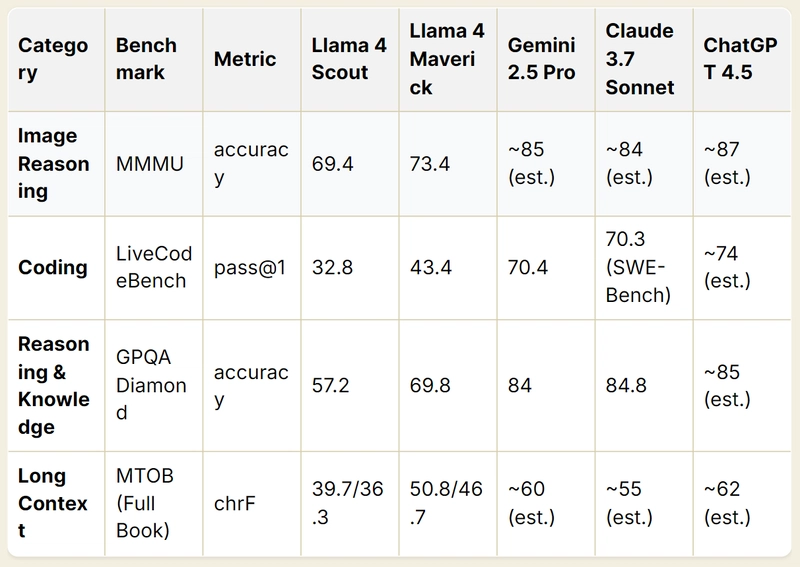
Instruction-tuned models show varying strengths. While Llama 4 models perform competitively in early image reasoning benchmarks, Gemini 2.5 Pro, Claude 3.7 Sonnet, and ChatGPT 4.5 are projected to excel. In coding, Gemini and Claude currently lead Llama 4, with ChatGPT 4.5 expected to be even stronger. Gemini and Claude also significantly outperform Llama 4 in reasoning and knowledge tasks. For long context understanding, Llama 4 Maverick improves upon Scout, but the other models are anticipated to achieve much higher scores.
Llama 4 Scout Comparison with Llama 3 Models
Llama 4 Scout vs. Llama 3.1 70B
- MMLU: Scout (79.6) slightly edges out Llama 3.1 70B (79.3), despite fewer active parameters, showcasing efficiency gains.
- MATH: Scout (50.3) significantly outperforms Llama 3.1 70B (41.6), reflecting improved mathematical reasoning.
- MBPP: Scout (67.8) beats Llama 3.1 70B (66.4), indicating better code generation.
- Context: Scout’s 10M token window dwarfs Llama 3.1’s 128K, enabling entirely new use cases like full-book analysis. Llama 4 Maverick vs. Llama 3.1 405B
- MMLU: Maverick (85.5) slightly surpasses Llama 3.1 405B (85.2), despite using fewer active parameters (17B vs. 405B).
- MATH: Maverick (61.2) outshines Llama 3.1 405B (53.5), a notable leap in problem-solving.
- MBPP: Maverick (77.6) exceeds Llama 3.1 405B (74.4), cementing its coding superiority.
- Multimodal: Maverick’s native image processing (e.g., ChartQA: 85.3) adds a dimension absent in Llama 3.1. Key Improvements
- Training Data: Doubled to 30T tokens from Llama 3’s 15T, enhancing knowledge breadth.
- MoE Efficiency: Fewer active parameters reduce compute costs while maintaining or exceeding performance.
- Context Window: 10M tokens vs. Llama 3’s 128K, unlocking long-context applications.
- Llama 4 Behemoth Comparison with Claude 3.7 Sonnet, GPT-4.5, and more
While Meta claims Llama 4 outperforms models like GPT-4o and Gemini 2.0, direct comparisons are limited by proprietary data scarcity. Here’s what we can infer:
- GPT-4o: OpenAI’s simple-evals GitHub reports a HumanEval score of 90.2, but MBPP scores are unavailable. Maverick’s MBPP (77.6) is strong, though likely below GPT-4o’s peak coding performance. On MMLU, GPT-4o’s rumored 87-88 range exceeds Maverick’s 85.5, but Scout and Maverick’s efficiency (single-GPU compatibility) offers a practical edge.
- Gemini 2.0: Google’s model lacks public benchmark details as of April 2025, but X posts suggest it competes with GPT-4.5. Maverick’s multimodal scores (e.g., DocVQA: 91.6) likely rival Gemini’s, given its focus on image-text integration.
- Claude 3.7 Sonnet: Anthropic’s model excels in reasoning, with rumored MATH scores around 60-65. Maverick’s 61.2 suggests parity or a slight edge, pending Behemoth’s release.
The open-source nature of Llama 4, combined with its competitive performance, challenges the proprietary dominance of these models, though exact comparisons await third-party validation.
Llama 4 Coding Comparison and Capabilities
Llama 4’s coding prowess is a standout feature, driven by its benchmark results and architectural innovations. Here’s a detailed exploration:
Benchmark Highlights
- MBPP: Maverick’s 77.6 pass@1 outperforms Llama 3.1 405B (74.4) and rivals top-tier models, indicating robust code generation.
- LiveCodeBench: Maverick’s 43.4 (vs. Llama 3.1 405B’s 27.7) reflects real-world coding strength, tested on problems from October 2024 to February 2025.
- Context Advantage: Scout’s 10M token window enables it to process entire codebases, debug sprawling projects, or generate context-aware solutions.
Multimodal Coding
Maverick’s ability to interpret visual inputs—like code diagrams or UML charts—enhances its utility. For instance, it can analyze a flowchart and generate corresponding Python code, a capability absent in text-only predecessors.
Developer Accessibility
Scout’s single-GPU compatibility (NVIDIA H100) democratizes access, allowing individual developers to run it locally. Maverick, while more resource-intensive, remains viable for small teams with multi-GPU setups, offering a balance of power and practicality.
Llama 4 Herd Test Prompts
Why rely on benchmarks when you can test Llama 4 Scout and Maverick yourself? Here are some prompts covering general-purpose, writing, and coding tasks that you can use to test their performance. You can compare them with other models like the Claude 3.7 Sonnet here.
Summarize the key events and themes of George Orwell’s 1984 in under 150 words.
Explain the concept of quantum entanglement in simple terms for a high school student.
Implement a simple algorithm in JavaScript that checks if a string is a palindrome.
Conclusion
The Llama 4 Herd represents a significant advancement in open-source AI, offering models that compete with proprietary options in performance and versatility. With Scout and Maverick now available for developers, and Behemoth on the way, Llama 4 aims to set new standards in STEM. Its strong coding capabilities, long context windows, and multimodal features make it ideal for software development and data analysis. However, further testing is needed to fully assess Behemoth's potential.
You can explore other models like Claude 3.7 Sonnet and DeepSeek R1 here.