

































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)















































































































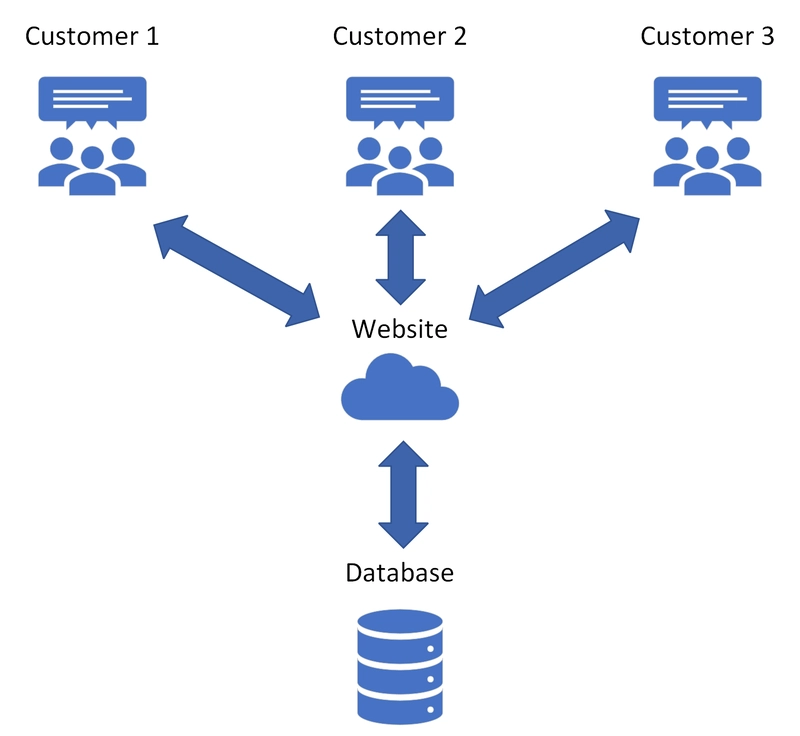



































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)























































































































_roibu_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




 CISO’s Core Focus.webp?#)









































































































![Apple Smart Glasses Not Close to Being Ready as Meta Targets 2025 [Gurman]](https://www.iclarified.com/images/news/97139/97139/97139-640.jpg)
![iPadOS 19 May Introduce Menu Bar, iOS 19 to Support External Displays [Rumor]](https://www.iclarified.com/images/news/97137/97137/97137-640.jpg)

![Apple Drops New Immersive Adventure Episode for Vision Pro: 'Hill Climb' [Video]](https://www.iclarified.com/images/news/97133/97133/97133-640.jpg)






























































































INTRODUCTION TO DATA ENGINEERING
Data engineering entails the designing,building and maintaining of scalable data infrastructure which enables efficient :- data processing data storage data retrival KEY CONCEPTS OF DATA ENGINEERING DATA PIPELINES -automates the flow of data from source(s) to destination(s), often passing through multiple stages like cleaning, transformation, and enrichment. Core Components of a Data Pipeline Source(s): Where the data comes from Databases (e.g., MySQL, PostgreSQL) APIs (e.g., Twitter API) Files (e.g., CSV, JSON, Parquet) Streaming services (e.g., Kafka) 2.Ingestion: Collecting the data Tools: Apache NiFi, Apache Flume, or custom scripts 3.Processing/Transformation: Cleaning and preparing data Batch processing: Apache Spark, Pandas Stream processing: Apache Kafka, Apache Flink 4.Storage: Where the processed data is stored Data Lakes (e.g., S3, HDFS) Data Warehouses (e.g., Snowflake, BigQuery, Redshift) 5.Orchestration: Managing dependencies and scheduling Tools: Apache Airflow, Prefect, Luigi 6.Monitoring & Logging: Making sure everything works as expected Logging tools (e.g., ELK Stack, Datadog) Alerting systems ETL - ETL stands for Extract, Transform, Load — it's a core concept in data engineering used to move and process data from source systems into a destination system like a data warehouse. ETL Example Let’s say you're analyzing sales data: Extract: Pull sales data from a MySQL database and product info from a CSV. Transform: Join sales with product names Format dates Remove duplicates or missing values Load: Save the clean, combined data to a Snowflake table for analytics. DATABASES AND DATA WAREHOUSES What is a Database? A database is designed to store current, real-time data for everyday operations of applications. ✅ Used For: CRUD operations (Create, Read, Update, Delete) Running websites, apps, or transactional systems Real-time access

Data engineering entails the designing,building and maintaining of scalable data infrastructure which enables efficient :-
- data processing
- data storage
- data retrival
KEY CONCEPTS OF DATA ENGINEERING
DATA PIPELINES -automates the flow of data from source(s) to destination(s), often passing through multiple stages like cleaning, transformation, and enrichment.
Core Components of a Data Pipeline
- Source(s): Where the data comes from
Databases (e.g., MySQL, PostgreSQL)
APIs (e.g., Twitter API)
Files (e.g., CSV, JSON, Parquet)
Streaming services (e.g., Kafka)
2.Ingestion: Collecting the data
Tools: Apache NiFi, Apache Flume, or custom scripts
3.Processing/Transformation: Cleaning and preparing data
Batch processing: Apache Spark, Pandas
Stream processing: Apache Kafka, Apache Flink
4.Storage: Where the processed data is stored
Data Lakes (e.g., S3, HDFS)
Data Warehouses (e.g., Snowflake, BigQuery, Redshift)
5.Orchestration: Managing dependencies and scheduling
Tools: Apache Airflow, Prefect, Luigi
6.Monitoring & Logging: Making sure everything works as expected
Logging tools (e.g., ELK Stack, Datadog)
Alerting systems
ETL - ETL stands for Extract, Transform, Load — it's a core concept in data engineering used to move and process data from source systems into a destination system like a data warehouse.
ETL Example
Let’s say you're analyzing sales data:
Extract: Pull sales data from a MySQL database and product info from a CSV.
Transform:
Join sales with product names
Format dates
Remove duplicates or missing values
Load: Save the clean, combined data to a Snowflake table for analytics.
DATABASES AND DATA WAREHOUSES
What is a Database?
A database is designed to store current, real-time data for everyday operations of applications.
✅ Used For:
- CRUD operations (Create, Read, Update, Delete)
- Running websites, apps, or transactional systems
- Real-time access


