










































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)

























































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)


























































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



























































































![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)












![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)






























































































































Intelligent Support Ticket Routing with Natural Language Processing (NLP)
Intro to Large Language Model Data This project explores the process of preparing real-world language data for use with large language models (LLMs). While the broader field of natural language processing (NLP) has existed for decades, modern LLMs bring new complexity and opportunity to tasks like classification, generation, and automated decision-making. In this context, support ticket routing is an ideal real-world case to apply LLM-aligned data preparation techniques. We'll focus on a specific use case: building an NLP pipeline that processes, cleans, embeds, and classifies enterprise support tickets. The result is a system that can accurately route tickets across a range of multilingual categories using advanced sentence embeddings and machine learning. 1. Problem Statement and Goal Support teams often deal with thousands of incoming tickets that need to be routed to the correct department. Manually categorizing these tickets is slow and error-prone. Our goal is to automatically classify support tickets based on their textual content using NLP techniques, enabling faster triage and resolution. 2. Prerequisites GitHub Reference material: https://github.com/Fortune-Ndlovu/Intelligent-Support-Ticket-Routing-with-NLP-and-XGBoost/tree/main This notebook assumes you have the latest Python and the following libraries installed. First things first, Set Up Your Environment (Anaconda) by creating a new conda environment you can achieve this by opening up your terminal (or Anaconda Prompt): conda create -n ticket-nlp python=3.10 -y conda activate ticket-nlp You will probably want to install the required packages therefore use conda and pip as needed: # Core packages conda install pandas scikit-learn -y conda install -c conda-forge matplotlib seaborn # Install pip packages (for embedding + transformers) pip install sentence-transformers pip install tqdm pip install nltk pip install deep-translator tqdm pip install xgboost At this point your environment is ready. Let us proceed to loading and exploring the dataset! 3. Load and Explore Dataset You can download the Dataset by navigating to Multilingual Customer Support Tickets – Kaggle and save it as tickets.csv in your project folder At this point, you now have the raw data and can begin exploring by loading the dataset and checking available columns. import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import re import nltk from nltk.corpus import stopwords from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report, confusion_matrix from sentence_transformers import SentenceTransformer nltk.download('stopwords') df = pd.read_csv("tickets.csv") print(df.columns) C:\Users\ndlov\anaconda3\envs\ticket-nlp\lib\site-packages\tqdm\auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm Index(['subject', 'body', 'answer', 'type', 'queue', 'priority', 'language', 'business_type', 'tag_1', 'tag_2', 'tag_3', 'tag_4', 'tag_5', 'tag_6', 'tag_7', 'tag_8', 'tag_9'], dtype='object') [nltk_data] Downloading package stopwords to [nltk_data] C:\Users\ndlov\AppData\Roaming\nltk_data... [nltk_data] Package stopwords is already up-to-date! # Quick preview df.head() .dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; } subject body answer type queue priority language business_type tag_1 tag_2 tag_3 tag_4 tag_5 tag_6 tag_7 tag_8 tag_9 0 Problema crítico del servidor requiere atenció... Es necesaria una investigación inmediata sobre... Estamos investigando urgentemente el problema ... Incident Technical Support high es IT Services Urgent Issue Service Disruption Incident Report Service Recovery System Maintenance NaN NaN NaN NaN 1 Anfrage zur Verfügbarkeit des Dell XPS 13 9310 Sehr geehrter Kundenservice,\n\nich hoffe, die... Sehr geehrter ,\n\nvielen Dank, dass Sie... Request Customer Service low de Tech Online Store Sales Inquiry Product Support Customer Service Order Issue Returns and Exchanges NaN NaN NaN NaN 2 Erro na Autocompletação de Código do IntelliJ ... Prezado Suporte ao Cliente ,\n\nEstou es... Prezado ,\n\nObrigado por entrar em cont... Incident Technical Support
Intro to Large Language Model Data
This project explores the process of preparing real-world language data for use with large language models (LLMs). While the broader field of natural language processing (NLP) has existed for decades, modern LLMs bring new complexity and opportunity to tasks like classification, generation, and automated decision-making. In this context, support ticket routing is an ideal real-world case to apply LLM-aligned data preparation techniques.
We'll focus on a specific use case: building an NLP pipeline that processes, cleans, embeds, and classifies enterprise support tickets. The result is a system that can accurately route tickets across a range of multilingual categories using advanced sentence embeddings and machine learning.
1. Problem Statement and Goal
Support teams often deal with thousands of incoming tickets that need to be routed to the correct department. Manually categorizing these tickets is slow and error-prone. Our goal is to automatically classify support tickets based on their textual content using NLP techniques, enabling faster triage and resolution.
2. Prerequisites
GitHub Reference material: https://github.com/Fortune-Ndlovu/Intelligent-Support-Ticket-Routing-with-NLP-and-XGBoost/tree/main
This notebook assumes you have the latest Python and the following libraries installed.
First things first, Set Up Your Environment (Anaconda) by creating a new conda environment you can achieve this by opening up your terminal (or Anaconda Prompt):
conda create -n ticket-nlp python=3.10 -y
conda activate ticket-nlp
You will probably want to install the required packages therefore use conda and pip as needed:
# Core packages
conda install pandas scikit-learn -y
conda install -c conda-forge matplotlib seaborn
# Install pip packages (for embedding + transformers)
pip install sentence-transformers
pip install tqdm
pip install nltk
pip install deep-translator tqdm
pip install xgboost
At this point your environment is ready. Let us proceed to loading and exploring the dataset!
3. Load and Explore Dataset
You can download the Dataset by navigating to Multilingual Customer Support Tickets – Kaggle and save it as tickets.csv in your project folder
At this point, you now have the raw data and can begin exploring by loading the dataset and checking available columns.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import re
import nltk
from nltk.corpus import stopwords
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix
from sentence_transformers import SentenceTransformer
nltk.download('stopwords')
df = pd.read_csv("tickets.csv")
print(df.columns)
C:\Users\ndlov\anaconda3\envs\ticket-nlp\lib\site-packages\tqdm\auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Index(['subject', 'body', 'answer', 'type', 'queue', 'priority', 'language',
'business_type', 'tag_1', 'tag_2', 'tag_3', 'tag_4', 'tag_5', 'tag_6',
'tag_7', 'tag_8', 'tag_9'],
dtype='object')
[nltk_data] Downloading package stopwords to
[nltk_data] C:\Users\ndlov\AppData\Roaming\nltk_data...
[nltk_data] Package stopwords is already up-to-date!
# Quick preview
df.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| subject | body | answer | type | queue | priority | language | business_type | tag_1 | tag_2 | tag_3 | tag_4 | tag_5 | tag_6 | tag_7 | tag_8 | tag_9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Problema crítico del servidor requiere atenció... | Es necesaria una investigación inmediata sobre... | Estamos investigando urgentemente el problema ... | Incident | Technical Support | high | es | IT Services | Urgent Issue | Service Disruption | Incident Report | Service Recovery | System Maintenance | NaN | NaN | NaN | NaN |
| 1 | Anfrage zur Verfügbarkeit des Dell XPS 13 9310 | Sehr geehrter Kundenservice,\n\nich hoffe, die... | Sehr geehrter |
Request | Customer Service | low | de | Tech Online Store | Sales Inquiry | Product Support | Customer Service | Order Issue | Returns and Exchanges | NaN | NaN | NaN | NaN |
| 2 | Erro na Autocompletação de Código do IntelliJ ... | Prezado Suporte ao Cliente |
Prezado |
Incident | Technical Support | high | pt | IT Services | Technical Support | Software Bug | Problem Resolution | Urgent Issue | IT Support | NaN | NaN | NaN | NaN |
| 3 | Urgent Assistance Required: AWS Service | Dear IT Services Support Team, \n\nI am reachi... | Dear |
Request | IT Support | high | en | IT Services | IT Support | Urgent Issue | Service Notification | Cloud Services | Problem Resolution | Technical Guidance | Performance Tuning | NaN | NaN |
| 4 | Problème d'affichage de MacBook Air | Cher équipe de support du magasin en ligne Tec... | Cher |
Incident | Product Support | low | fr | Tech Online Store | Technical Support | Product Support | Hardware Failure | Service Recovery | Routine Request | NaN | NaN | NaN | NaN |
Before diving into preprocessing, it's important to understand the structure and richness of our dataset. Each row represents a unique support ticket submitted by a user. These tickets span multiple languages and departments, simulating a real-world enterprise support system. We begin by loading the CSV file using pandas and displaying a quick preview:
This gives us insight into the following key columns:
| Column | Description |
|---|---|
subject |
Short summary or title of the ticket (usually user-written) |
body |
Full description of the issue or request |
answer |
Optional response or continuation in the thread |
type |
Ticket type such as "Incident" or "Request"
|
queue |
Ground-truth label for which department handled the ticket |
priority |
Priority level (e.g., "high", "low") |
language |
Detected language of the ticket |
business_type |
Type of customer/business segment |
tag_1–tag_9
|
Multi-label tags capturing relevant categories, issue types, or subtopics |
This diverse set of features allows us to build a model that not only understands natural language but also considers context, issue categorization, and business structure, making it ideal for intelligent routing tasks.
4. Text Cleaning
Text cleaning is the process of transforming raw, messy, human-written text into a structured, consistent format that machine learning models can understand. In the context of support tickets, this involves removing unnecessary characters (like punctuation), normalizing casing and accents, eliminating common filler words (like "the" or "please"), and combining fragmented text fields into a single input. This step is critical in natural language processing (NLP) because clean, standardized text helps models learn patterns more effectively, especially when dealing with multiple languages, noisy inputs, and user-generated content. LLMs and ML models benefit from clean, normalized text. We'll lowercase, remove punctuation, stopwords, and extra whitespace.
import re
import unicodedata
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
# 1. Combine fields robustly
df['text'] = df[['subject', 'body', 'answer']].fillna('').agg(' '.join, axis=1)
# 2. Use sklearn's stopword list
stop_words = ENGLISH_STOP_WORDS
# 3. Compile regex once for performance
_whitespace_re = re.compile(r"\s+")
_non_alphanum_re = re.compile(r"[^a-z0-9\s]")
# 4. Define pro cleaner with accent normalization
def clean_text(text):
text = str(text).lower().strip()
text = unicodedata.normalize('NFKD', text).encode('ascii', 'ignore').decode('utf-8')
text = _non_alphanum_re.sub("", text)
text = _whitespace_re.sub(" ", text)
tokens = [word for word in text.split() if word not in stop_words]
return " ".join(tokens)
# 5. Apply cleaning function
df['clean_text'] = df['text'].apply(clean_text)
# 6. Preview result
df[['subject', 'clean_text']].head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| subject | clean_text | |
|---|---|---|
| 0 | Problema crítico del servidor requiere atenció... | problema critico del servidor requiere atencio... |
| 1 | Anfrage zur Verfügbarkeit des Dell XPS 13 9310 | anfrage zur verfugbarkeit des dell xps 13 9310... |
| 2 | Erro na Autocompletação de Código do IntelliJ ... | erro na autocompletacao codigo intellij idea p... |
| 3 | Urgent Assistance Required: AWS Service | urgent assistance required aws service dear se... |
| 4 | Problème d'affichage de MacBook Air | probleme daffichage macbook air cher equipe su... |
Before we can train a machine learning model on language data, we need to clean it up. This is a super important step in NLP. Why? Because raw text is messy, especially when it comes from real users.
You may have already noticed that our support tickets are written in different languages (Spanish, Portuguese, French, etc.), contain accents, punctuation, extra spaces, and a lot of common words (like “the”, “and”, “please”) that don’t help the model make smarter predictions.
Did you notice our data is still not all English? This is because the original ticket dataset is intentionally multilingual. If we just filter stopwords using English rules or lowercase French/Spanish/Portuguese words, we’re still not doing the best we can.
That’s why in the next section, we will:
- Detect ticket language
- Automatically translate non-English tickets to English using Google Translate
- Then apply this same cleaning function
import pandas as pd
import re
import unicodedata
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
from deep_translator import GoogleTranslator
from functools import lru_cache
from tqdm import tqdm
# Enable tqdm for pandas apply
tqdm.pandas()
# --- 1. Combine subject + body + answer into single text column ---
df['text'] = df[['subject', 'body', 'answer']].fillna('').agg(' '.join, axis=1)
# --- 2. Caching Google Translate for performance ---
@lru_cache(maxsize=10000)
def cached_translate(text, lang):
if lang != 'en':
try:
return GoogleTranslator(source=lang, target='en').translate(text)
except Exception:
return text # fallback to original
return text
# --- 3. Translate non-English text with progress ---
df['text_en'] = df.progress_apply(lambda row: cached_translate(row['text'], row['language']), axis=1)
# --- 4. Use sklearn's English stopwords ---
stop_words = ENGLISH_STOP_WORDS
# --- 5. Compile regex patterns ---
_whitespace_re = re.compile(r"\s+")
_non_alphanum_re = re.compile(r"[^a-z0-9\s]")
# --- 6. Define professional text cleaner ---
def clean_text(text):
text = str(text).lower().strip()
text = unicodedata.normalize('NFKD', text).encode('ascii', 'ignore').decode('utf-8') # remove accents
text = _non_alphanum_re.sub("", text) # remove punctuation
text = _whitespace_re.sub(" ", text) # normalize whitespace
tokens = [word for word in text.split() if word not in stop_words]
return " ".join(tokens)
# --- 7. Apply the cleaning function with progress ---
df['clean_text'] = df['text_en'].progress_apply(clean_text)
# --- 8. Preview sample results ---
sample = df[['language', 'subject', 'text_en', 'clean_text']].sample(5, random_state=42)
for i, row in sample.iterrows():
print(f"Language: {row['language']}")
print(f"Subject: {row['subject']}")
print(f"Translated: {row['text_en'][:200]}...")
print(f"Cleaned: {row['clean_text'][:200]}...\n")
print("-" * 80)
100%|██████████| 4000/4000 [11:37<00:00, 5.74it/s]
100%|██████████| 4000/4000 [00:00<00:00, 4544.00it/s]
Language: pt
Subject: Assistência Necessária para Problemas Persistentes de Atolamento de Papel com Impressora Canon
Translated: Assistance required for persistent paper jam problems with canon printer with customer support,
I am writing to report persistent paper jam problems with my Canon Pixma MG3620 printer. The problem oc...
Cleaned: assistance required persistent paper jam problems canon printer customer support writing report persistent paper jam problems canon pixma mg3620 printer problem occurs light checkout documentation ass...
--------------------------------------------------------------------------------
Language: es
Subject: nan
Translated: Dear customer support equipment, I am writing to get your attention on the continuous problems we are experiencing with our AWS cloud implementation, which is managed through its AWS administration se...
Cleaned: dear customer support equipment writing attention continuous problems experiencing aws cloud implementation managed aws administration service interruptions happening growing frequency led significant...
--------------------------------------------------------------------------------
Language: en
Subject: Urgent: Jira Software 8.20 Malfunction Issue
Translated: Urgent: Jira Software 8.20 Malfunction Issue Dear Support Team,
I am writing to report a serious issue that we have been facing with Jira Software 8.20, specifically during our Scrum sprint managemen...
Cleaned: urgent jira software 820 malfunction issue dear support team writing report issue facing jira software 820 specifically scrum sprint management tasks team encountered persistent malfunctions significa...
--------------------------------------------------------------------------------
Language: es
Subject: Problema de creación de tickets en Jira Software 8.20
Translated: Ticket creation problem in jira software 8.20 estimated customer support,
I am experiencing problems with the process of creating tickets in Jira Software 8.20. Every time I try to send a new ticket,...
Cleaned: ticket creation problem jira software 820 estimated customer support experiencing problems process creating tickets jira software 820 time try send new ticket error message appears prevents completing...
--------------------------------------------------------------------------------
Language: fr
Subject: nan
Translated: Dear customer service,
I hope you find you healthy. I am writing to request an upgrading of our Google Workspace licenses for the sales team in order to improve their productivity and their collabora...
Cleaned: dear customer service hope healthy writing request upgrading google workspace licenses sales team order improve productivity collaboration capacities currently use standard business edition transition...
--------------------------------------------------------------------------------
Now that we’ve cleaned our English text what about all those non-English support tickets?
You may have noticed: our dataset contains tickets in Spanish, Portuguese, French, and German, and we want our model to treat them equally.
Instead of dropping them (which would waste data), we take the logical approach:
- Detect the ticket language
- Translate non-English text into English automatically
- Then apply the same cleaning logic as before
This ensures every ticket is processed in the same language, which makes our model smarter and fairer.
5. Text Embedding and Classification Model Training
After cleaning the text, we still can’t feed it directly into a machine learning model, computers don’t understand words the way humans do. This is where text embedding comes in. Embedding is the process of converting text into numerical vectors (lists of numbers) that capture the meaning and context of the words or sentences. Think of it as turning text into something the model can "see" and learn from.
Once the text is embedded, we use those vectors to train a classification model, a type of algorithm that learns to recognize patterns and assign labels. In our case, the model learns to predict the correct support queue (like “Technical Support” or “Product Support”) based on the ticket’s content. This combination of embedding + classification is the core of how we automate ticket routing using NLP.
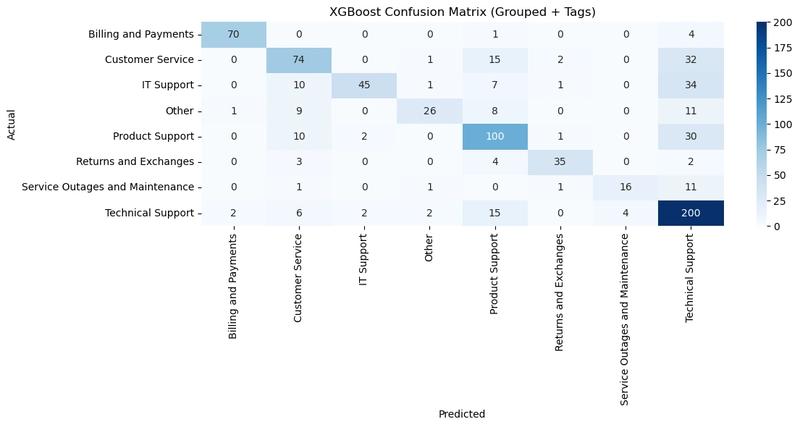
In this step, we train a machine learning classifier on the embedded support tickets. To do this, we first encode our category labels (queue_grouped) into numbers using a label encoder, then train an XGBoost model a high-performance, gradient-boosted decision tree classifier. After training, we evaluate the model's accuracy and visualize how well it performs across all support categories using a classification report and a confusion matrix.
from sklearn.preprocessing import LabelEncoder
# Encode y labels (queue_grouped)
le = LabelEncoder()
y_encoded = le.fit_transform(y)
# Train/test split
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, test_size=0.2, random_state=42)
# Train XGBoost
print("Training XGBoost...")
clf = XGBClassifier(
n_estimators=300,
max_depth=8,
learning_rate=0.1,
subsample=0.8,
colsample_bytree=0.8,
scale_pos_weight=1,
use_label_encoder=False,
eval_metric='mlogloss',
n_jobs=-1,
verbosity=1
)
clf.fit(X_train, y_train)
# Predict & decode
y_pred = clf.predict(X_test)
y_test_labels = le.inverse_transform(y_test)
y_pred_labels = le.inverse_transform(y_pred)
# Evaluate
print("\n 

