








































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)










































































































































































































![GrandChase tier list of the best characters available [April 2025]](https://media.pocketgamer.com/artwork/na-33057-1637756796/grandchase-ios-android-3rd-anniversary.jpg?#)







































.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)



























.webp?#)




























































































![Quick Share redesign looks more like a normal app with prep for ‘Receive’ and ‘Send’ tabs [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/12/quick-share-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)











![New Beats USB-C Charging Cables Now Available on Amazon [Video]](https://www.iclarified.com/images/news/97060/97060/97060-640.jpg)

![Apple M4 13-inch iPad Pro On Sale for $200 Off [Deal]](https://www.iclarified.com/images/news/97056/97056/97056-640.jpg)
![Apple Shares New 'Mac Does That' Ads for MacBook Pro [Video]](https://www.iclarified.com/images/news/97055/97055/97055-640.jpg)





















































































































InsightFlow Part 1: Building an Integrated Retail & Economic Data Pipeline - Project Introduction
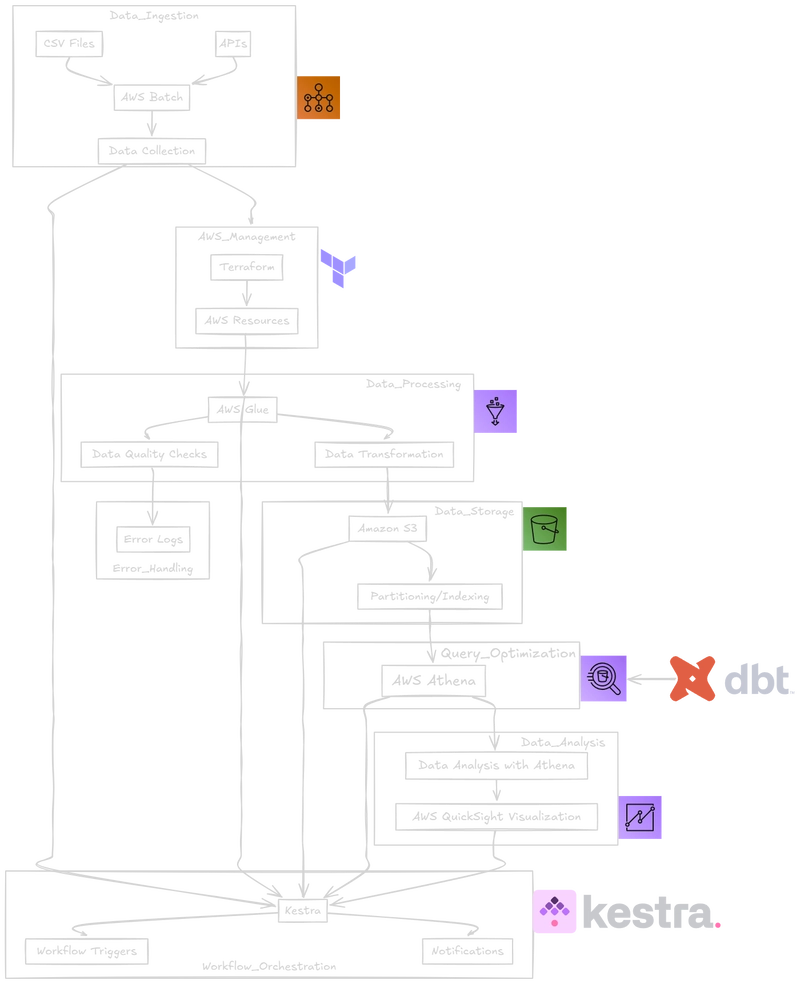
Introduction I'm thrilled to begin documenting my journey building "InsightFlow" - an end-to-end data engineering project that I've designed to showcase real-world data engineering skills while providing genuinely useful insights. Over the coming weeks, I'll be publishing a series of blog posts detailing every aspect of this project, from initial setup to final visualizations, sharing both my successes and challenges along the way. As someone preparing for mid-level Data Engineer positions, I wanted to create a portfolio project that demonstrates proficiency with modern data engineering technologies while solving an authentic business problem. By following the "Learning in Public" approach, I hope to not only document my own learning process but also provide value to others on similar journeys. Project Motivation: Connecting Retail Performance & Economic Indicators The inspiration for InsightFlow came from a simple observation: businesses often struggle to connect their performance metrics with broader economic indicators. For retailers in particular, understanding how external economic factors like fuel prices might influence consumer spending patterns can provide valuable strategic insights. Malaysia's open data portal, data.gov.my, offers a treasure trove of public datasets that can help answer questions like: How do retail sales trends correlate with fluctuations in fuel prices? Which retail sectors are most sensitive to economic indicators? Can we identify seasonal patterns in retail performance when controlling for economic factors? By integrating and analyzing these public datasets, InsightFlow aims to demonstrate how a well-designed data pipeline can transform raw data into actionable business intelligence. Project Scope & Datasets For this project, I've selected three complementary datasets from Malaysia's open data portal: Headline Wholesale & Retail Trade: This dataset provides high-level sales trends across Malaysia's retail sector, giving us a macro view of overall market performance. Wholesale & Retail Trade by Group (3-digit): This more granular dataset breaks down sales figures by specific industry categories, allowing for comparative analysis across different retail segments. Price of Petroleum & Diesel: This dataset tracks weekly fuel price updates, providing an important economic indicator that potentially influences consumer spending patterns. By integrating these datasets, we can explore relationships between retail sector performance and fuel price fluctuations—a connection that might yield valuable insights for business planning and forecasting. Architecture Overview: Modern Cloud-Based Data Pipeline InsightFlow is designed as a comprehensive batch data pipeline leveraging AWS cloud services and modern data engineering tools. Here's an overview of the architecture: The architecture consists of four main components: 1. Data Ingestion Layer The data ingestion layer periodically collects data from the three selected datasets using: AWS Batch for scheduled data collection jobs Python scripts for API interactions and file processing Amazon S3 for storing raw data in a data lake structure Terraform for infrastructure provisioning and management This approach ensures reliable, scalable data collection while maintaining the reproducibility of the infrastructure through code. 2. Data Processing Layer The processing layer transforms raw data into analysis-ready formats using: AWS Glue for ETL processing dbt for data transformation Data quality checks to ensure consistency and reliability Partitioning strategies for optimized storage and query performance This layer handles the crucial tasks of cleaning, normalizing, and enriching the raw data while creating the necessary joins between retail performance and fuel price data. 3. Data Warehouse & Analytics Layer The analytics layer enables interactive querying and insight generation using: Amazon S3 as the storage backbone for processed data AWS Glue Data Catalog for metadata management Amazon Athena for SQL-based querying capabilities AWS QuickSight for visualization and dashboard creation This layer transforms processed data into actionable insights through interactive queries and visual analytics. 4. Orchestration Layer Tying everything together, the orchestration layer ensures reliable end-to-end pipeline execution using: Kestra for workflow orchestration and scheduling Monitoring and alerting mechanisms for reliability Logging and error handling for troubleshooting and audit trails This layer ensures the entire pipeline runs smoothly, with appropriate error handling and recovery mechanisms. Skills & Technologies Demonstrated Through this project, I'll be demonstrating proficiency in several key areas sought by employers hiring mid-level Data Engineers: Cloud Platform Engineering: Expertis
Introduction
I'm thrilled to begin documenting my journey building "InsightFlow" - an end-to-end data engineering project that I've designed to showcase real-world data engineering skills while providing genuinely useful insights. Over the coming weeks, I'll be publishing a series of blog posts detailing every aspect of this project, from initial setup to final visualizations, sharing both my successes and challenges along the way.
As someone preparing for mid-level Data Engineer positions, I wanted to create a portfolio project that demonstrates proficiency with modern data engineering technologies while solving an authentic business problem. By following the "Learning in Public" approach, I hope to not only document my own learning process but also provide value to others on similar journeys.
Project Motivation: Connecting Retail Performance & Economic Indicators
The inspiration for InsightFlow came from a simple observation: businesses often struggle to connect their performance metrics with broader economic indicators. For retailers in particular, understanding how external economic factors like fuel prices might influence consumer spending patterns can provide valuable strategic insights.
Malaysia's open data portal, data.gov.my, offers a treasure trove of public datasets that can help answer questions like:
- How do retail sales trends correlate with fluctuations in fuel prices?
- Which retail sectors are most sensitive to economic indicators?
- Can we identify seasonal patterns in retail performance when controlling for economic factors?
By integrating and analyzing these public datasets, InsightFlow aims to demonstrate how a well-designed data pipeline can transform raw data into actionable business intelligence.
Project Scope & Datasets
For this project, I've selected three complementary datasets from Malaysia's open data portal:
- Headline Wholesale & Retail Trade: This dataset provides high-level sales trends across Malaysia's retail sector, giving us a macro view of overall market performance.
- Wholesale & Retail Trade by Group (3-digit): This more granular dataset breaks down sales figures by specific industry categories, allowing for comparative analysis across different retail segments.
- Price of Petroleum & Diesel: This dataset tracks weekly fuel price updates, providing an important economic indicator that potentially influences consumer spending patterns.
By integrating these datasets, we can explore relationships between retail sector performance and fuel price fluctuations—a connection that might yield valuable insights for business planning and forecasting.
Architecture Overview: Modern Cloud-Based Data Pipeline
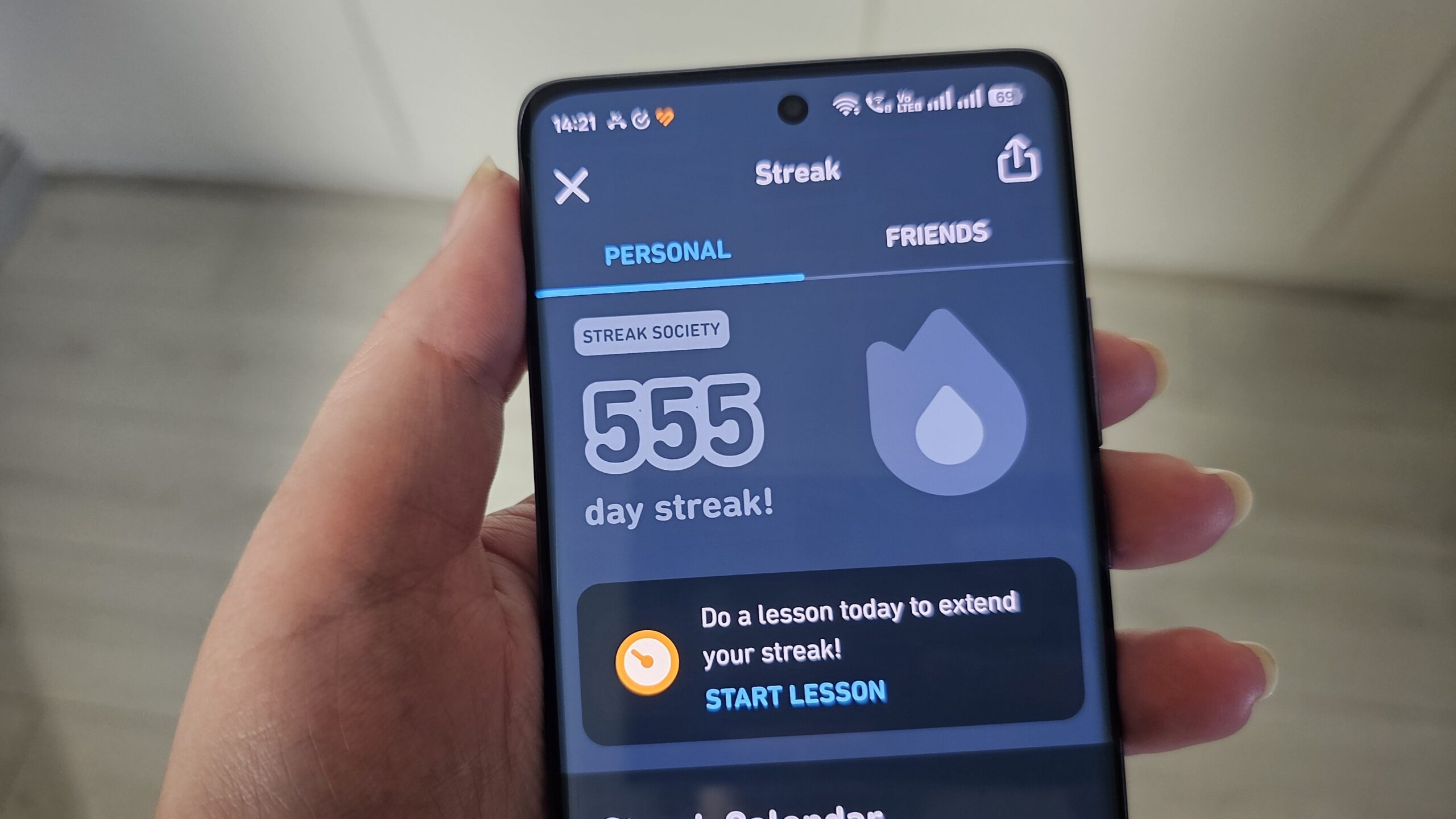
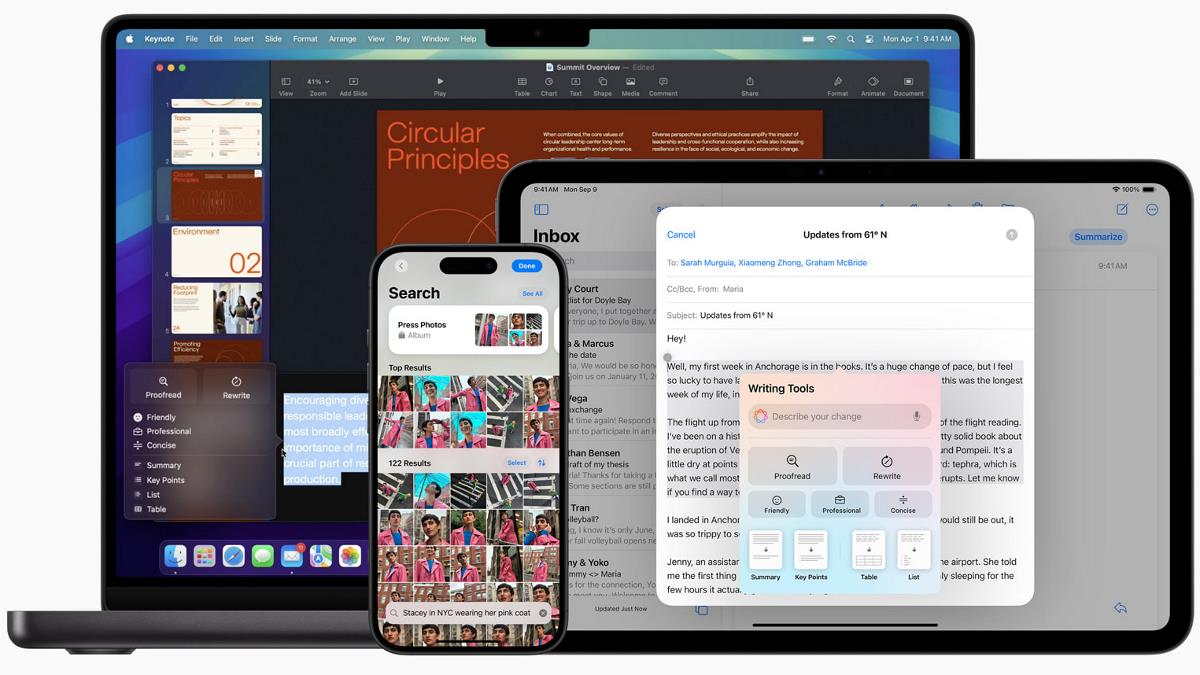
InsightFlow is designed as a comprehensive batch data pipeline leveraging AWS cloud services and modern data engineering tools. Here's an overview of the architecture:
The architecture consists of four main components:
1. Data Ingestion Layer
The data ingestion layer periodically collects data from the three selected datasets using:
- AWS Batch for scheduled data collection jobs
- Python scripts for API interactions and file processing
- Amazon S3 for storing raw data in a data lake structure
- Terraform for infrastructure provisioning and management
This approach ensures reliable, scalable data collection while maintaining the reproducibility of the infrastructure through code.
2. Data Processing Layer
The processing layer transforms raw data into analysis-ready formats using:
- AWS Glue for ETL processing
- dbt for data transformation
- Data quality checks to ensure consistency and reliability
- Partitioning strategies for optimized storage and query performance
This layer handles the crucial tasks of cleaning, normalizing, and enriching the raw data while creating the necessary joins between retail performance and fuel price data.
3. Data Warehouse & Analytics Layer
The analytics layer enables interactive querying and insight generation using:
- Amazon S3 as the storage backbone for processed data
- AWS Glue Data Catalog for metadata management
- Amazon Athena for SQL-based querying capabilities
- AWS QuickSight for visualization and dashboard creation
This layer transforms processed data into actionable insights through interactive queries and visual analytics.
4. Orchestration Layer
Tying everything together, the orchestration layer ensures reliable end-to-end pipeline execution using:
- Kestra for workflow orchestration and scheduling
- Monitoring and alerting mechanisms for reliability
- Logging and error handling for troubleshooting and audit trails
This layer ensures the entire pipeline runs smoothly, with appropriate error handling and recovery mechanisms.
Skills & Technologies Demonstrated
Through this project, I'll be demonstrating proficiency in several key areas sought by employers hiring mid-level Data Engineers:
- Cloud Platform Engineering: Expertise in AWS services including S3, Glue, Athena, and Batch
- Infrastructure as Code: Ability to provision and manage infrastructure using Terraform
- Data Pipeline Development: Experience designing and implementing reliable data pipelines
- ETL/ELT Process Implementation: Skills in data extraction, transformation using dbt, and loading to data warehouse.
- Data Warehousing: Knowledge of data warehouse design principles and implementation. We also use AWS S3 as data lake.
- SQL & Python Programming: Proficiency in the core languages of data engineering
- Workflow Orchestration: Experience with pipeline scheduling and management using Kestra
- Data Analysis & Visualization: Ability to generate actionable insights from processed data via QuickSight
Getting Started
To kickstart this project, I've already:
- Explored the three datasets to understand their structure, update frequency, and potential value
- Designed the high-level architecture shown above
- Created a GitHub repository to track all code and configurations
- Set up a development environment with necessary AWS permissions
In the next post, I'll dive into setting up the cloud infrastructure using Terraform, demonstrating how infrastructure-as-code practices enable reproducible and scalable environments.
Conclusion
InsightFlow represents not just a portfolio project, but a genuine exploration into how data engineering can provide valuable business insights by connecting seemingly disparate datasets. By bringing together retail performance metrics and economic indicators like fuel prices, we can potentially uncover relationships that might inform business strategy and planning.
Through this blog series, I invite you to join me on this learning journey. Whether you're a fellow aspiring data engineer, a business analyst interested in retail trends, or simply curious about data integration, I hope these posts will provide valuable insights into both the technical implementation and the analytical possibilities of modern data pipelines.
Stay tuned for the next post, where we'll dive into setting up our cloud infrastructure using Terraform.
This is the first in a series of blog posts documenting my InsightFlow project, created as part of my portfolio for mid-level Data Engineer positions. The project follows requirements inspired by DataTalks.Club Data Engineering Zoomcamp.



