![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)













































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)








































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)








































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


























































































![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)





























































































































How TOAST and Tombstones Work in PostgreSQL
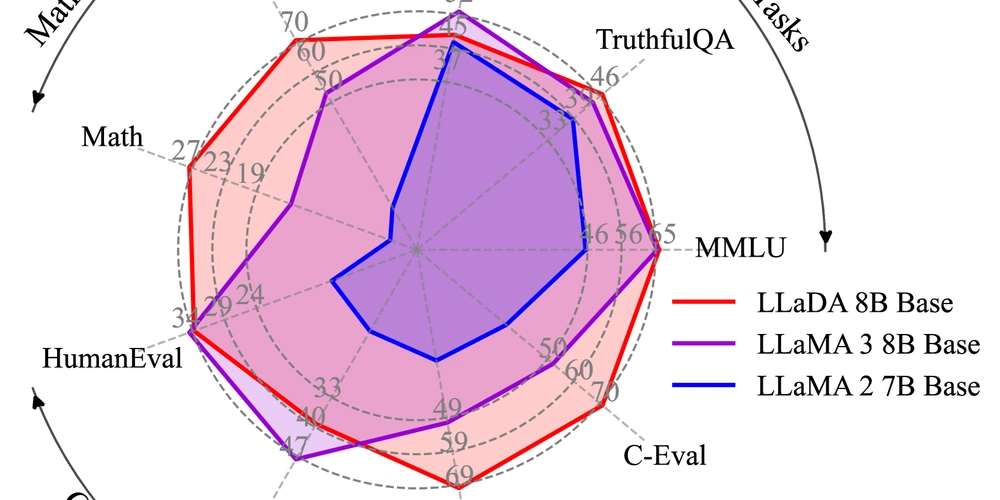
In relational databases like PostgreSQL, seemingly simple operations — such as updating JSON field — can hide significant complexity. Behind the scenes, mechanisms like TOAST and tombstones come into play, impacting performance, disk usage and even query efficiency. Depending on how data is structured, even a tiny modification can trigger disk rewrites, compression processes or silent fragmentation. In this article we'll explore: What TOAST is, when it activates, and why it matters for large data types The role of tombstones and how they affect read/write operations A practical benchmark, exposing how tiny updates can cause surprising overhead If you work with types like text[], jsonb, or dynamically growing data, understading these concepts is key to avoiding decisions that might compromise your database's scalability. What TOAST is TOAST (The Oversized-Attribute Storage Technique) is PostgreSQL's clever solution for handling large data values that exceed the database's default page size (commonly 8 kB). When a column's data — like a lengthy text field, a hefty jsonb object or an array — would otherwise bloat a table row and degrade performance, TOAST steps in. It automatically compresses, slices, or even moves the data out-of-line into a secondary storage area, leaving behind only a compact reference in the main table. This optimization keeps frequent operations (like full-table scans) efficient, but it's not free: updates to TOASTed data can introduce overhead, as PostgreSQL may need to rewrite or recompress chunks behind the scenes. TOAST targets variable-length or potentially large data types, including: JSON/JSONB: Especially when storing deeply nested or verbose documents. Text data: text, varchar (if values exceed ~2KB, even with varchar(n)’s length limit). Binary data: bytea (e.g., images, files). Geometric types: PostgreSQL’s built-in path, polygon, or spatial types like PostGIS geometry/geography. Toast example -- Step 1: Create a table with a JSONB column (toastable) CREATE TABLE toast_demo ( id SERIAL PRIMARY KEY, small_data TEXT, -- Will NOT be toasted large_data JSONB -- Will be toasted ); -- Step 2: Insert a small record (no TOAST) INSERT INTO toast_demo (small_data, large_data) VALUES ('short text', '{"key": "small_value"}'); -- Step 3: Insert a large JSONB payload (triggers TOAST) INSERT INTO toast_demo (small_data, large_data) VALUES ('short text', jsonb_build_object( 'key', 'value', 'nested', (SELECT array_agg(g) FROM generate_series(1, 10000) AS g ))); -- This query should return the TOAST table SELECT reltoastrelid::regclass FROM pg_class WHERE relname = 'toast_demo'; -- Step 4: Verify TOAST usage SELECT pg_size_pretty(pg_relation_size('toast_demo')) AS main_table_size, pg_size_pretty(pg_relation_size('pg_toast.pg_toast_32803')) AS toast_size FROM pg_class WHERE relname = 'toast_demo'; -- Step 5: Observe UPDATE overhead EXPLAIN ANALYZE UPDATE toast_demo SET large_data = large_data || '{"new_key": "value"}' WHERE id = 2; Key observations: For a single-row update, the execution time of 26.5ms is slightly slower than typical non-TOASTed updates (which usually take 1-5ms). This overhead occurs because PostgreSQL must: Fetch and decompress the TOASTed large_data value. Modify it (appending {"new_key": "value"}). Recompress and potentially relocate the data in the TOAST table. When this becomes a problem ? The 26.5ms latency is acceptable if: Updates are infrequent (e.g., background jobs rather than user-facing operations). The JSONB payload is very large (>10KB) and requires compression. Investigate further if you see: Updates exceeding >100ms (indicates severe TOAST fragmentation or bloat). Concurrent updates causing lock contention (check for blocked queries in pg_stat_activity). Autovacuum falling behind on TOAST table maintenance (monitor with pg_stat_user_tables). The role of Tombstones and their impact on Read/Write Operations In PostgreSQL, tombstones (often called "dead tuples") are remnants of rows that have been deleted or updated but not yet physically removed from disk. They play crucial role in PostgreSQL's MVCC (Multi-Version Concurrency Control) system, but if left unchecked, they can degrade performance and bloat storage. Tombstones are created on: delete - When a row is deleted, it's not immediately erased — instead, it's marked as a "dead" (a tombstone). update - PostgreSQL treats updates as a delete + insert, leaving the old row version as a tombstone. vacuum - PostgreSQL's autovacuum daemon (or manual vacuum) eventually cleans up these tombstones, reclaiming space. How tombstones affect performance On the read side, they contribute to table bloat by forcing the database to scan through dead rows that remain in heap pages, while index scans must still check MVCC visibility for these obsolete

In relational databases like PostgreSQL, seemingly simple operations — such as updating JSON field — can hide significant complexity. Behind the scenes, mechanisms like TOAST and tombstones come into play, impacting performance, disk usage and even query efficiency.
Depending on how data is structured, even a tiny modification can trigger disk rewrites, compression processes or silent fragmentation. In this article we'll explore:
- What TOAST is, when it activates, and why it matters for large data types
- The role of tombstones and how they affect read/write operations
- A practical benchmark, exposing how tiny updates can cause surprising overhead
If you work with types like text[], jsonb, or dynamically growing data, understading these concepts is key to avoiding decisions that might compromise your database's scalability.
What TOAST is
TOAST (The Oversized-Attribute Storage Technique) is PostgreSQL's clever solution for handling large data values that exceed the database's default page size (commonly 8 kB). When a column's data — like a lengthy text field, a hefty jsonb object or an array — would otherwise bloat a table row and degrade performance, TOAST steps in. It automatically compresses, slices, or even moves the data out-of-line into a secondary storage area, leaving behind only a compact reference in the main table. This optimization keeps frequent operations (like full-table scans) efficient, but it's not free: updates to TOASTed data can introduce overhead, as PostgreSQL may need to rewrite or recompress chunks behind the scenes.
TOAST targets variable-length or potentially large data types, including:
- JSON/JSONB: Especially when storing deeply nested or verbose documents.
- Text data: text, varchar (if values exceed ~2KB, even with varchar(n)’s length limit).
- Binary data: bytea (e.g., images, files).
- Geometric types: PostgreSQL’s built-in path, polygon, or spatial types like PostGIS geometry/geography.
Toast example
-- Step 1: Create a table with a JSONB column (toastable)
CREATE TABLE toast_demo (
id SERIAL PRIMARY KEY,
small_data TEXT, -- Will NOT be toasted
large_data JSONB -- Will be toasted
);
-- Step 2: Insert a small record (no TOAST)
INSERT INTO toast_demo (small_data, large_data)
VALUES ('short text', '{"key": "small_value"}');
-- Step 3: Insert a large JSONB payload (triggers TOAST)
INSERT INTO toast_demo (small_data, large_data)
VALUES ('short text',
jsonb_build_object(
'key', 'value',
'nested', (SELECT array_agg(g) FROM generate_series(1, 10000) AS g
)));
-- This query should return the TOAST table
SELECT reltoastrelid::regclass
FROM pg_class
WHERE relname = 'toast_demo';
-- Step 4: Verify TOAST usage
SELECT
pg_size_pretty(pg_relation_size('toast_demo')) AS main_table_size,
pg_size_pretty(pg_relation_size('pg_toast.pg_toast_32803')) AS toast_size
FROM pg_class
WHERE relname = 'toast_demo';
-- Step 5: Observe UPDATE overhead
EXPLAIN ANALYZE UPDATE toast_demo SET large_data = large_data || '{"new_key": "value"}' WHERE id = 2;
Key observations: For a single-row update, the execution time of 26.5ms is slightly slower than typical non-TOASTed updates (which usually take 1-5ms). This overhead occurs because PostgreSQL must:
- Fetch and decompress the TOASTed large_data value.
- Modify it (appending {"new_key": "value"}).
- Recompress and potentially relocate the data in the TOAST table.
When this becomes a problem ?
The 26.5ms latency is acceptable if:
- Updates are infrequent (e.g., background jobs rather than user-facing operations).
- The JSONB payload is very large (>10KB) and requires compression.
Investigate further if you see:
- Updates exceeding >100ms (indicates severe TOAST fragmentation or bloat).
- Concurrent updates causing lock contention (check for blocked queries in pg_stat_activity).
- Autovacuum falling behind on TOAST table maintenance (monitor with pg_stat_user_tables).
The role of Tombstones and their impact on Read/Write Operations
In PostgreSQL, tombstones (often called "dead tuples") are remnants of rows that have been deleted or updated but not yet physically removed from disk. They play crucial role in PostgreSQL's MVCC (Multi-Version Concurrency Control) system, but if left unchecked, they can degrade performance and bloat storage.
Tombstones are created on:
- delete - When a row is deleted, it's not immediately erased — instead, it's marked as a "dead" (a tombstone).
- update - PostgreSQL treats updates as a delete + insert, leaving the old row version as a tombstone.
- vacuum - PostgreSQL's autovacuum daemon (or manual vacuum) eventually cleans up these tombstones, reclaiming space.
How tombstones affect performance
On the read side, they contribute to table bloat by forcing the database to scan through dead rows that remain in heap pages, while index scans must still check MVCC visibility for these obsolete entries, adding CPU overhead. The presence of excessive tombstones can also prevent PostgreSQL from using visibility map optimizations, slowing down sequential scans. For write operations, update-heavy workloads suffer from write amplification as each modification generates new tombstones, requiring addition I/O for the same logical changes. This accumulation poses serious risks, including transaction ID wraparound if VACUUM can't keep pace with tombstone generation, potentially leading to database shutdowns. Storage efficiency takes a hit as well, with dead tuples occupying disk space until vacuumed — sometimes doubling a table's footprint — while leaving behind fragmented pages that degrade storage utilization. These compounding effects make proper tombstone management crucial for maintaining database performance and stability.
Tombstone Example
-- Step 1: Create a table and disable autovacuum (for demo purposes)
CREATE TABLE tombstone_demo (
id SERIAL PRIMARY KEY,
data TEXT
);
ALTER TABLE tombstone_demo SET (autovacuum_enabled = false);
-- Step 2: Insert initial data
INSERT INTO tombstone_demo (data) VALUES ('original_value');
-- Step 3: Check dead tuples (should be 0)
SELECT n_dead_tup FROM pg_stat_user_tables WHERE relname = 'tombstone_demo';
-- Step 4: Run 1000 updates (each creates a dead tuple)
DO $$
BEGIN
FOR i IN 1..1000 LOOP
UPDATE tombstone_demo SET data = 'updated_' || i WHERE id = 1;
END LOOP;
END $$;
-- Step 5: Verify dead tuples accumulated
SELECT n_dead_tup FROM pg_stat_user_tables WHERE relname = 'tombstone_demo';
-- Step 6: Show table bloat
SELECT pg_size_pretty(pg_relation_size('tombstone_demo')) AS size_with_bloat;
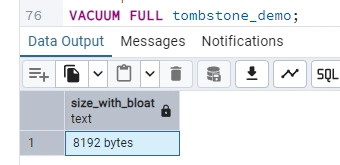
-- Step 7: Manual VACUUM to clean tombstones
VACUUM (VERBOSE) tombstone_demo;
-- Step 8: Confirm if dead tuples are gone
SELECT n_dead_tup FROM pg_stat_user_tables WHERE relname = 'tombstone_demo';
Even when repeatedly updating the same row, PostgreSQL doesn't overwrite the original data. Instead, it creates a new version of the row and marks the previous one as a dead tuple. This means that with every UPDATE, the table accumulates older versions of the data. By disabling autovacuum, we can observe how these dead tuples accumulate without automatic cleanup. The result? The table begins to bloat on disk, even though it logically contains just one row.
The VACUUM command removes these old versions and makes the space reusable, but doesn't physically reduce the table's size on disk.
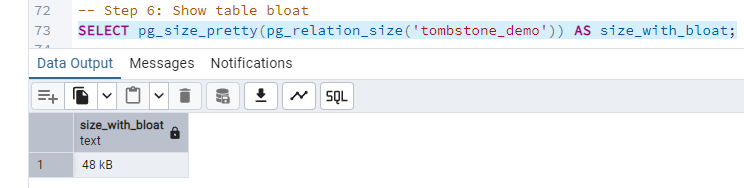
VACUUM FULL goes further: it creates a compacted copy of the table, eliminating all empty space and returning it to the operating system. However, this process is blocking (LOCK TABLE) and resource-intensive, as it must completely rewrite the table from scratch. For production systems where downtime isn't an option, the pg_repack extension is the superior alternative. It delivers all the benefits of VACUUM FULL (actual space recovery) without table locking, operating in parallel with normal database operations.
Final thoughts
While TOAST and tombstones are powerful mechanisms that support PostgreSQL’s flexibility and MVCC architecture, they also introduce performance trade-offs — especially in high-write or JSON-heavy applications.
Monitoring tools like pg_stat_user_tables, using VACUUM VERBOSE, and periodically checking bloat via pgstattuple or pg_repack can go a long way in keeping your database healthy and efficient.