



























![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)
















































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)





































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)









































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

























































































![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)
































































































































How HyDE Evaluation Makes Document Search Faster and More Accurate
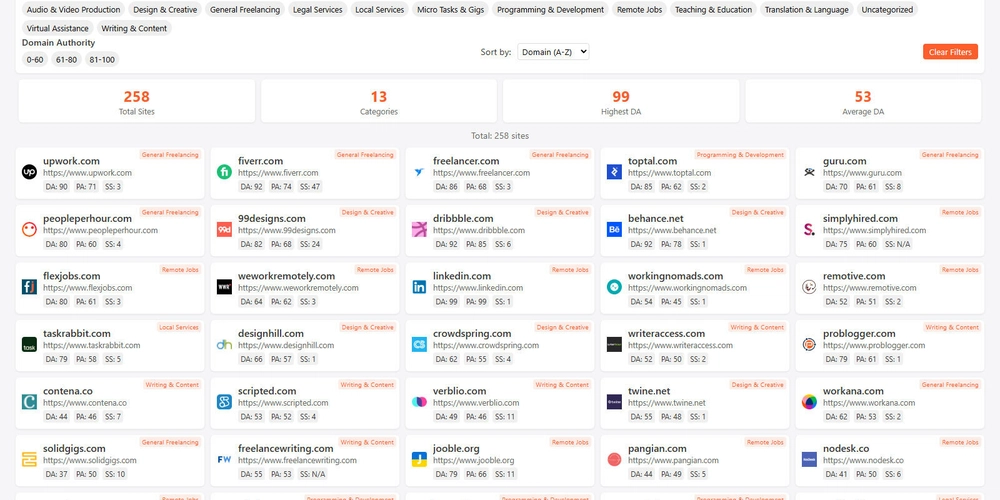
Finding the correct document rapidly and precisely is crucial in the fast-paced society of today. Time and accuracy are crucial whether you are a student searching for vital information or a professional sorting through large data sets. But as data grows, traditional search methods can slow down and miss the mark. That’s where HyDE Evaluation steps in—a game-changing approach that makes document searches faster and more accurate. In this blog, we’ll explore what HyDE is, how it works, and why it’s a big deal, complete with a simple code example and real-world benefits. What Is HyDE Evaluation? HyDE, short for Hyper-Document Evaluation, is a smart technique designed to turbocharge document retrieval. It breaks large documents into smaller, bite-sized pieces called “chunks” and uses clever algorithms to process them. Instead of searching an entire document, HyDE focuses only on the most relevant chunks, saving time and boosting accuracy. By evaluating these chunks in real-time, it ensures you get exactly what you need—fast. How Does HyDE Work? HyDE, or Hypothetical Document Embeddings, is like a genius assistant who imagines the perfect answer to your question before searching for it. Unlike traditional search methods that struggle with single-vector limitations or need massive labeled datasets, HyDE combines large language models (LLMs) and embeddings to deliver fast, accurate results. It solves the challenge of capturing query intent without extensive training data. Here’s the step-by-step breakdown: Understand the Question: You input a query, like “How long does it take to remove a wisdom tooth?” HyDE passes this to an LLM, such as GPT, with instructions to create a hypothetical answer. Generate a Hypothetical Document: The LLM crafts a pretend document answering your query. It’s not always fact-perfect but captures the core idea of what you’re after—like a sketch of the ideal response. Turn It into Embeddings: This hypot hetical document is converted into a vector (a digital fingerprint) using a contrastive encoder. To illustrate, contrastive encoders learn to pull similar items closer and push dissimilar ones apart, as shown below: Figure 1 - Illustration of Triplet Loss in Cosine Similarity. This shows how a contrastive encoder learns to position an anchor (query) closer to a positive (relevant document) and farther from a negative (irrelevant document) after training. Search for Matches: HyDE uses the vector to search a database of pre-encoded real documents, finding the ones most similar to the hypothetical answer. The process is streamlined, bypassing the need for labor-intensive labeled data. The architecture is visualized here: Figure 2 - Illustration of the HyDE Model. The query goes through an LLM to generate a hypothetical document, which is encoded and matched against real documents for retrieval. Deliver Results: The most relevant real documents are returned as your search results, saving time and hitting the mark with precision. HyDE’s approach is a game-changer because it captures the meaning behind your query better than keyword-based searches. By generating a hypothetical answer first, it bridges the gap between what you ask and what’s out there, making searches quicker and more accurate. Why Is HyDE Faster? Traditional search tools scan entire documents, which can drag on as data piles up. HyDE flips the script with these speed-boosting tricks: Optimized Chunking: By working with smaller pieces, HyDE skips irrelevant sections and zeroes in on what’s useful. Parallel Processing: It can handle multiple chunks at once, cutting down wait times even more. -** Smarter Algorithms:** HyDE’s algorithms prioritize the best chunks, so you’re not wading through junk. The result? Lightning-fast searches, even with huge datasets. How Does HyDE Boost Accuracy? Speed’s great, but accuracy seals the deal. HyDE delivers pinpoint results like this: Context Matters: It understands the meaning behind each chunk, not just the words, so you get relevant hits every time. Relevance Scoring: Each chunk gets a score based on how well it matches your query—top scores rise to the top. Learning Over Time: HyDE gets sharper with use, fine-tuning its accuracy as it learns from past searches. No more scrolling through useless results—HyDE nails it. HyDE in Action: A Simple Code Example Let’s see HyDE at work with a basic Python example. This program ranks, queries, and divides a document into pieces. It’s beginner-friendly and shows HyDE’s core idea. # Import necessary libraries import re from collections import Counter # Function to split the document into chunks def split_into_chunks(doc, chunk_size=100): return [doc[i:i+chunk_size] for i in range(0, len(doc), chunk_size)] # Function to evaluate chunk relevance def evaluate_chunks(query, chunks): query_terms = Counter(re.findall(r'\w+', query.lower())) chu
Finding the correct document rapidly and precisely is crucial in the fast-paced society of today. Time and accuracy are crucial whether you are a student searching for vital information or a professional sorting through large data sets. But as data grows, traditional search methods can slow down and miss the mark. That’s where HyDE Evaluation steps in—a game-changing approach that makes document searches faster and more accurate. In this blog, we’ll explore what HyDE is, how it works, and why it’s a big deal, complete with a simple code example and real-world benefits.
What Is HyDE Evaluation?
HyDE, short for Hyper-Document Evaluation, is a smart technique designed to turbocharge document retrieval. It breaks large documents into smaller, bite-sized pieces called “chunks” and uses clever algorithms to process them.
Instead of searching an entire document, HyDE focuses only on the most relevant chunks, saving time and boosting accuracy. By evaluating these chunks in real-time, it ensures you get exactly what you need—fast.
How Does HyDE Work?
HyDE, or Hypothetical Document Embeddings, is like a genius assistant who imagines the perfect answer to your question before searching for it. Unlike traditional search methods that struggle with single-vector limitations or need massive labeled datasets, HyDE combines large language models (LLMs) and embeddings to deliver fast, accurate results. It solves the challenge of capturing query intent without extensive training data. Here’s the step-by-step breakdown:
- Understand the Question: You input a query, like “How long does it take to remove a wisdom tooth?” HyDE passes this to an LLM, such as GPT, with instructions to create a hypothetical answer.
- Generate a Hypothetical Document: The LLM crafts a pretend document answering your query. It’s not always fact-perfect but captures the core idea of what you’re after—like a sketch of the ideal response.
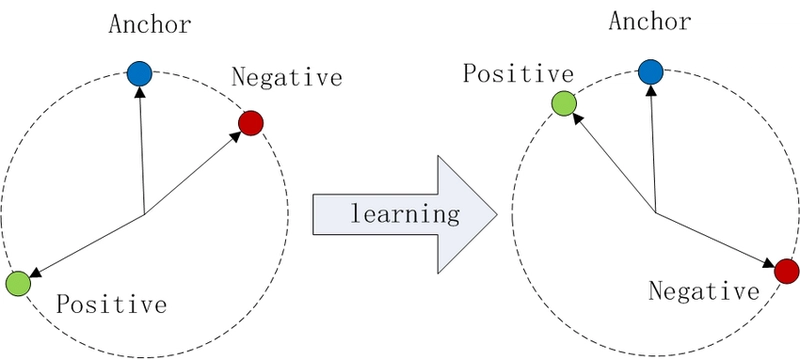
- Turn It into Embeddings: This hypot hetical document is converted into a vector (a digital fingerprint) using a contrastive encoder. To illustrate, contrastive encoders learn to pull similar items closer and push dissimilar ones apart, as shown below:
Figure 1 - Illustration of Triplet Loss in Cosine Similarity. This shows how a contrastive encoder learns to position an anchor (query) closer to a positive (relevant document) and farther from a negative (irrelevant document) after training.
- Search for Matches: HyDE uses the vector to search a database of pre-encoded real documents, finding the ones most similar to the hypothetical answer. The process is streamlined, bypassing the need for labor-intensive labeled data. The architecture is visualized here:
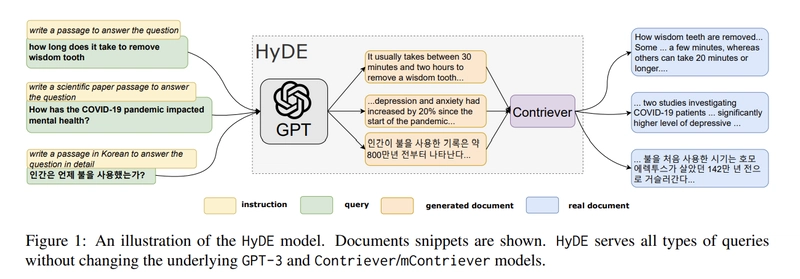
Figure 2 - Illustration of the HyDE Model. The query goes through an LLM to generate a hypothetical document, which is encoded and matched against real documents for retrieval.
- Deliver Results: The most relevant real documents are returned as your search results, saving time and hitting the mark with precision.
HyDE’s approach is a game-changer because it captures the meaning behind your query better than keyword-based searches. By generating a hypothetical answer first, it bridges the gap between what you ask and what’s out there, making searches quicker and more accurate.
Why Is HyDE Faster?
Traditional search tools scan entire documents, which can drag on as data piles up. HyDE flips the script with these speed-boosting tricks:
- Optimized Chunking: By working with smaller pieces, HyDE skips irrelevant sections and zeroes in on what’s useful.
- Parallel Processing: It can handle multiple chunks at once, cutting down wait times even more. -** Smarter Algorithms:** HyDE’s algorithms prioritize the best chunks, so you’re not wading through junk. The result? Lightning-fast searches, even with huge datasets.
How Does HyDE Boost Accuracy?
Speed’s great, but accuracy seals the deal. HyDE delivers pinpoint results like this:
- Context Matters: It understands the meaning behind each chunk, not just the words, so you get relevant hits every time.
- Relevance Scoring: Each chunk gets a score based on how well it matches your query—top scores rise to the top.
- Learning Over Time: HyDE gets sharper with use, fine-tuning its accuracy as it learns from past searches.
No more scrolling through useless results—HyDE nails it.
HyDE in Action: A Simple Code Example
Let’s see HyDE at work with a basic Python example. This program ranks, queries, and divides a document into pieces. It’s beginner-friendly and shows HyDE’s core idea.
# Import necessary libraries
import re
from collections import Counter
# Function to split the document into chunks
def split_into_chunks(doc, chunk_size=100):
return [doc[i:i+chunk_size] for i in range(0, len(doc), chunk_size)]
# Function to evaluate chunk relevance
def evaluate_chunks(query, chunks):
query_terms = Counter(re.findall(r'\w+', query.lower()))
chunk_scores = []
for chunk in chunks:
chunk_terms = Counter(re.findall(r'\w+', chunk.lower()))
score = sum(chunk_terms[term] * query_terms[term] for term in query_terms)
chunk_scores.append((chunk, score))
return sorted(chunk_scores, key=lambda x: x[1], reverse=True)
# Sample document and query
doc = """HyDE Evaluation is an innovative technique for document retrieval. By optimizing the chunking process,
it allows faster and more accurate searches. The evaluation method ensures that only relevant chunks are retrieved."""
query = "faster document retrieval"
# Split and evaluate
chunks = split_into_chunks(doc, chunk_size=50)
evaluated_chunks = evaluate_chunks(query, chunks)
# Show top chunks
for chunk, score in evaluated_chunks[:3]:
print(f"Score: {score}\nChunk: {chunk}\n")
Output:
Score: 3
Chunk: it allows faster and more accurate searches. The eval
Score: 2
Chunk: HyDE Evaluation is an innovative technique for docume
Score: 1
Chunk: nt retrieval. By optimizing the chunking process, it
What’s Happening?
- The document splits into chunks (50 characters each here).
- Each chunk gets a score based on how many query words (“faster,” “document,” “retrieval”) it contains.
- The top chunk—“it allows faster and more accurate searches”—wins with a score of 3, proving HyDE’s knack for finding the best match fast.
HyDE vs. Traditional Search Methods
How does HyDE stack up against old-school search? Check this out:
- Speed: Traditional methods slog through whole documents; HyDE races through chunks.
- Accuracy: Keyword-only searches miss context; HyDE gets the full picture.
- Scalability: As data grows, traditional tools lag—HyDE scales effortlessly by adjusting chunk sizes.
HyDE leaves outdated methods in the dust, delivering quick, spot-on results every time.
Real-World Wins with HyDE
HyDE isn’t just theory—it’s a practical lifesaver:
- Professionals: Find critical reports in seconds, not hours.
- Students: Grab the perfect research snippet without endless scrolling.
- Developers: Build slick, efficient search tools with HyDE’s frame work. Less hassle, more productivity—who doesn’t want that?
Try HyDE Yourself
Ready to dive deeper? Explore this hands-on project: Optimizing Chunk Sizes for Efficient and Accurate Document Retrieval Using HyDE Evaluation. It’s a fun, beginner-friendly way to experiment with HyDE and tweak chunk sizes for better speed and accuracy. See the difference in action!
Conclusion
HyDE Evaluation is revolutionizing document search by making it faster, more accurate, and scalable. By chopping documents into smart chunks and evaluating them on the fly, it cuts through the noise to deliver what you need—when you need it. Whether you’re managing mountains of data or just hunting for one key file, HyDE’s got your back. Take your search game to the next level with this cutting-edge approach—fast, precise, and future-ready, HyDE is the way to go!


