







































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






































































































































































































![Blue Archive tier list [April 2025]](https://media.pocketgamer.com/artwork/na-33404-1636469504/blue-archive-screenshot-2.jpg?#)
































.png?#)









-Baldur’s-Gate-3-The-Final-Patch---An-Animated-Short-00-03-43.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)












![Apple to Split Enterprise and Western Europe Roles as VP Exits [Report]](https://www.iclarified.com/images/news/97032/97032/97032-640.jpg)























































































































![Nanoleaf Announces New Pegboard Desk Dock With Dual-Sided Lighting [Video]](https://www.iclarified.com/images/news/97030/97030/97030-640.jpg)

![Apple's Foldable iPhone May Cost Between $2100 and $2300 [Rumor]](https://www.iclarified.com/images/news/97028/97028/97028-640.jpg)


























































































































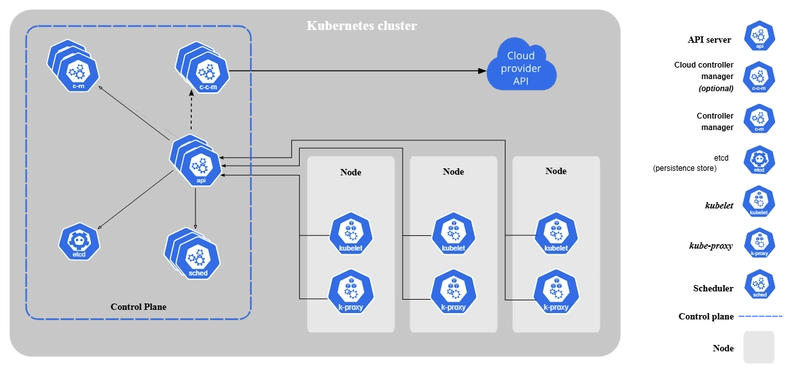
From Idea to Infra: Building Scalable Systems with Kubernetes, Terraform & Cloud (Detailed)
1. Introduction: The Imperative of Early Scalability The MVP Dilemma Most of our Startups clients often prioritize rapid development to launch a Minimum Viable Product (MVP). While this approach accelerates time-to-market, it can inadvertently introduce: Technical Debt: Quick fixes may evolve into systemic bottlenecks. For instance, a monolithic database might suffice initially but could become a performance chokepoint as user load increases. Reactive Scaling: Addressing scalability post-facto is typically 3-5 times more costly than integrating scalability from the outset. Operational Fragility: Manual deployment processes are prone to errors and can falter under unexpected traffic surges. Objectives of This Guide This comprehensive guide aims to equip you with: A structured six-phase roadmap transitioning from MVP to enterprise-scale systems. Practical Terraform and Kubernetes configurations rooted in real-world scenarios. Strategies for achieving resilience through multi-cloud deployments. 2. Phase 1: From Concept to Architectural Blueprint Selecting the Appropriate Architecture Choosing between monolithic and microservices architectures is pivotal: Aspect Monolith Microservices Codebase Unified Decentralized Data Management Single database (SQL/NoSQL) Diverse databases tailored to each service Communication Internal method calls Inter-service communication via APIs (e.g., gRPC) Decision Criteria: Monolith: Ideal for early-stage applications with small teams (
1. Introduction: The Imperative of Early Scalability
The MVP Dilemma
Most of our Startups clients often prioritize rapid development to launch a Minimum Viable Product (MVP). While this approach accelerates time-to-market, it can inadvertently introduce:
Technical Debt: Quick fixes may evolve into systemic bottlenecks. For instance, a monolithic database might suffice initially but could become a performance chokepoint as user load increases.
Reactive Scaling: Addressing scalability post-facto is typically 3-5 times more costly than integrating scalability from the outset.
Operational Fragility: Manual deployment processes are prone to errors and can falter under unexpected traffic surges.
Objectives of This Guide
This comprehensive guide aims to equip you with:
- A structured six-phase roadmap transitioning from MVP to enterprise-scale systems.
Practical Terraform and Kubernetes configurations rooted in real-world scenarios.
Strategies for achieving resilience through multi-cloud deployments.
2. Phase 1: From Concept to Architectural Blueprint
Selecting the Appropriate Architecture
Choosing between monolithic and microservices architectures is pivotal:
| Aspect | Monolith | Microservices |
|---|---|---|
| Codebase | Unified | Decentralized |
| Data Management | Single database (SQL/NoSQL) | Diverse databases tailored to each service |
| Communication | Internal method calls | Inter-service communication via APIs (e.g., gRPC) |
Decision Criteria:
Monolith: Ideal for early-stage applications with small teams (<10 developers) and minimal external integrations.
Microservices: Suited for complex domains requiring scalability, such as platforms handling real-time analytics alongside transactional operations.
Case Study: Architecting a B2B SaaS Platform
Consider a B2B SaaS offering data analytics:
Load Balancer: Manages incoming traffic, ensuring even distribution across services.
API Gateway: Handles authentication and routes requests to appropriate backend services.
Authentication Service: Validates user credentials and manages sessions.
Data Ingestion Service: Utilizes tools like Apache Kafka for real-time data streaming.
Processing Service: Employs Apache Flink for data transformation and analysis.
- Frontend Content Delivery Network (CDN): Delivers static assets, enhancing load times and user experience.
- Technologies: Frameworks like Next.js or React, hosted on platforms such as AWS S3 combined with CloudFront for global distribution.
Key Components:
Service Isolation: Each function operates as an independent service, facilitating scalability and maintainability.
Asynchronous Processing: Decouples data ingestion from processing, allowing each to scale based on demand.
Cloud-Native Storage: Leverages services like Amazon S3 for durable and scalable object storage.
3. Phase 2: Infrastructure as Code with Terraform
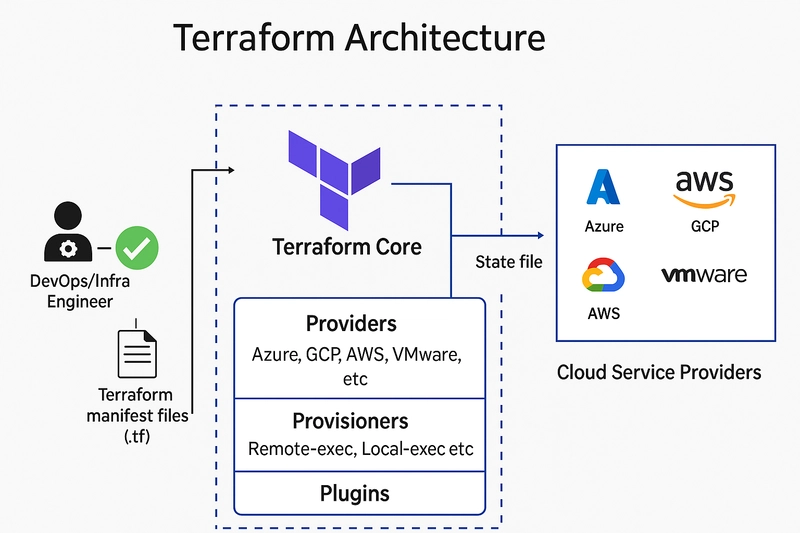
Modular Design
Organizing Terraform configurations into modules promotes reusability and clarity:
project-root/
├── modules/
│ ├── network/ # VPC, Subnets, Route Tables
│ ├── database/ # RDS instances, parameter groups
│ └── eks/ # EKS cluster, node groups
├── environments/
│ ├── dev/
│ └── prod/
└── main.tf
Example: Provisioning an EKS Cluster
Utilizing the terraform-aws-eks module simplifies EKS deployment:
module "eks" {
source = "terraform-aws-modules/eks/aws"
cluster_name = "my-cluster"
cluster_version = "1.28"
vpc_id = module.network.vpc_id
subnet_ids = module.network.private_subnets
eks_managed_node_groups = {
default = {
min_size = 3
max_size = 10
instance_type = "m6i.large"
}
}
}
This configuration establishes an EKS cluster with managed node groups, ensuring scalability and resilience.
Best Practices:
Environment Isolation: Employ Terraform workspaces to manage different environments (e.g., development, production).
State Management: Store Terraform state files remotely using Amazon S3, with DynamoDB for state locking to prevent concurrent modifications.
4. Phase 3: Deploying Applications with Kubernetes
Implementing Autoscaling
Kubernetes' Horizontal Pod Autoscaler (HPA) dynamically adjusts the number of pod replicas based on observed CPU utilization or other select metrics.
Deployment Configuration:
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-server
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
template:
spec:
containers:
- name: api-container
image: my-api-image:latest
resources:
requests:
cpu: "500m"
limits:
cpu: "1"
HPA Configuration:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: api-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: api-server
minReplicas: 3
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
Phase 3: Deploying Applications with Kubernetes, diving into more real-world configurations and then moving through CI/CD, multi-cloud, observability, and the case study.
GitOps with ArgoCD
ArgoCD provides declarative GitOps-style continuous delivery for Kubernetes.
Example Workflow:
- Code is pushed to GitHub.
- ArgoCD watches the Git repo for changes.
- Automatically syncs updated manifests to the cluster.
Key Benefits:
- Instant rollback with Git history.
- Better audit trail and environment parity.
- Integration with RBAC and SSO for governance.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-app
spec:
project: default
source:
repoURL: https://github.com/org/repo
path: k8s
targetRevision: HEAD
destination:
server: https://kubernetes.default.svc
namespace: default
syncPolicy:
automated:
prune: true
selfHeal: true
Helm Charts for Reusability
Helm allows packaging of Kubernetes resources as charts for reuse across environments and services.
Example Helm Chart Structure:
mychart/
├── templates/
│ ├── deployment.yaml
│ ├── service.yaml
├── values.yaml
You can deploy with:
helm upgrade --install my-app ./mychart --values values-prod.yaml
Secrets Management
Use SOPS + AWS KMS to encrypt secrets.yaml in Git:
sops -e --kms "arn:aws:kms:..." secrets.yaml > secrets.enc.yaml
This ensures you store encrypted secrets in version control securely.
5. Phase 4: CI/CD Pipeline for Infrastructure + Application
CI/CD with GitHub Actions
Infrastructure + App Deployment Pipeline
name: Deploy Infrastructure & App
on:
push:
branches: [main]
jobs:
terraform:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: hashicorp/setup-terraform@v2
- run: terraform init
- run: terraform plan -out=tfplan
- run: terraform apply tfplan
deploy-app:
needs: terraform
runs-on: ubuntu-latest
steps:
- name: Deploy to Kubernetes
uses: azure/k8s-deploy@v3
with:
namespace: production
manifests: |
k8s/deployment.yaml
k8s/service.yaml
Secrets in CI/CD:
- Store secrets in GitHub Actions Secrets.
- Use SOPS-encrypted files for application secrets, decrypted at deploy time.
6. Phase 5: Multi-Cloud & Disaster Recovery Patterns
Real-World Hybrid Cloud Pattern
Let’s assume a fintech application that needs:
- Compute workloads on GCP (GKE)
- Object storage on AWS (S3)
- Directory integration via Azure Active Directory
Setup:
+-----------------+ +-----------------+ +-------------------------+
| Google Cloud |------| Amazon Web |------| Microsoft Azure |
| Platform (GCP) | | Services (AWS) | | |
+-----------------+ +-----------------+ +-------------------------+
| | |
| | |
+-------v-------+ +-------v-------+ +-------v-------+
| GKE Clusters |------| S3 Buckets |------| Azure AD |
| (Backend APIs)| | (Document | | (Identity Provider)|
+---------------+ | Uploads) | +-----------------+
| +---------------+
| | Lambda |
| | (Post- |
| | processing) |
| +---------------+
|
+-------v-------+
| Cloud Storage |<-------------------+
| (Mirrored) | (gsutil rsync - nightly)
+---------------+
+-----------------------------------------------------------------------+
| Disaster Recovery Components |
+-----------------------------------------------------------------------+
| |
+-------v-------+ +-------v-------+
| Route 53 |<------------------------------>| Azure Traffic |
| (DNS Failover)| | Manager |
+---------------+ +---------------+
| |
| (Failover Routing) |
| |
+-------v-------+ +-------v-------+
| Pre-configured|------(Terraform)------------->| EKS Clusters |
| EKS Modules | | (DR Compute) |
+---------------+ +---------------+
|
| (Data Restore)
|
+-------v-------+
| S3 Snapshots |------(Aurora Global DB/------>| Aurora Global |
| (Cross-Region)| | BigQuery Exports) | Database / |
+---------------+ +-----------------------+ | BigQuery |
+---------------+
+-----------------------------------------------------------------------+
| Cross-Cloud Backup & Restore |
+-----------------------------------------------------------------------+
|
+-------v-------+
| Velero |------(Backup & Restore)------>| (GKE, Persistent|
| | | Volumes to/from|
| | | various storage)|
+---------------+
+-----------------------------------------------------------------------+
| Shared Critical Artifacts |
+-----------------------------------------------------------------------+
|
+-------v-------+
| Replicated |------(Critical Config, etc.)->| GCP & AWS Buckets|
| Storage | | |
+---------------+
-
Storage:
- AWS S3 for document uploads.
- Google Cloud Storage mirrored nightly with
gsutil rsync.
-
Compute:
- GCP’s GKE hosts containerized backend APIs.
- AWS Lambda for serverless post-processing (e.g., thumbnail generation).
-
Auth:
- Azure AD via OpenID Connect integrated into your API Gateway (Kong or Apigee).
Disaster Recovery Example:
Scenario: GKE goes down.
Solution:
- DNS failover using Route53 + Azure Traffic Manager.
- Spin up pre-configured EKS clusters using Terraform modules.
- Restore database from cross-region S3 snapshots (Aurora global database or BigQuery exports).
Tools Used:
- Velero for Kubernetes backup + restore across clouds.
- Replicated storage buckets for critical artifacts.
7. Phase 6: Observability and SLO Monitoring
Full Stack Observability Setup
Metrics:
- Prometheus collects cluster metrics.
- Thanos stores long-term metrics and provides global query view.
Logs:
- Loki ingests container logs.
- Dashboards via Grafana.
Traces:
- Tempo or Jaeger traces request lifecycles.
Example Grafana Alert:
alert: HighErrorRate
expr: sum(rate(http_requests_total{status=~"5.."}[5m])) / sum(rate(http_requests_total[5m])) > 0.05
for: 10m
labels:
severity: critical
annotations:
summary: "High error rate detected"
description: "More than 5% of requests are failing"
Example SLO:
- 99.95% availability of login service (measured over rolling 30 days).
- Alert if error budget is consumed at 10%/day.
8. Case Study: Scaling AdTech Platform from 0 to Millions of Events per Day
Example: Magnite – A Programmatic Advertising Platform
Problem Statement:
Magnite started as a platform to help mid-size publishers run targeted ad campaigns and real-time bidding for display ads. The MVP was built in 6 months, but within a year, it needed to handle:
- 50K+ QPS on bidding APIs
- Real-time analytics for advertisers
- Fraud detection at scale
- Low-latency ad rendering across continents
PART 1: MVP
- Stack: Django monolith + PostgreSQL (RDS)
-
Infra: Deployed on EC2 + ALB in
us-east-1 - CI/CD: Manual deployment via Fabric
- Monitoring: CloudWatch only
Problems Identified:
- API latency crossed 800ms during peak load
- Deployments took 30+ minutes with high failure rate
- Logs were inconsistent across app instances
- Ad latency in Asia exceeded 2s
PART 2: Lift & Shift with Terraform
Solution:
Reprovisioned infrastructure using Terraform.
module "network" {
source = "terraform-aws-modules/vpc/aws"
cidr = "10.0.0.0/16"
azs = ["us-east-1a", "us-east-1b", "us-east-1c"]
}
module "db" {
source = "terraform-aws-modules/rds/aws"
engine = "postgres"
instance_class = "db.r6g.large"
replicas = 2
}
Benefits:
- One-click environment creation
- DR strategy implemented with cross-region replicas
- Remote backend state with S3 + DynamoDB lock
PART 3: Microservices Architecture
Breakdown:
| Service | Stack | Function |
|---|---|---|
| Bidding Engine | Go + Redis | <10ms bidding latency |
| Campaign Manager | Node.js + MongoDB | Advertiser dashboard |
| Metrics Collector | Kafka + Flink | Stream processing |
| Fraud Detection | Python + TensorFlow | Model inference |
Tech Decisions:
- Kafka for decoupled event stream
- MongoDB sharded for campaign data
- Redis used for real-time bidding decision cache
// Bid Response Logic (simplified)
if campaign.BudgetLeft > bidPrice {
return Bid{AdID: "xyz", Price: bidPrice}
}
PART 4: Kubernetes & Autoscaling
Platform: AWS EKS + GitOps with ArgoCD
Components:
-
HorizontalPodAutoscalerfor Bidding Engine - Cluster-autoscaler using
k8s-on-spot.iofor cost saving - ArgoCD deployed with SSO login + sync hooks
Sample deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: bidding-engine
spec:
replicas: 5
strategy:
type: RollingUpdate
template:
spec:
containers:
- name: bidding
image: registry.io/bidding:latest
resources:
limits:
cpu: "2"
memory: "1Gi"
GitOps Hook:
syncPolicy:
automated:
prune: true
selfHeal: true
PART 5: Multi-Region + CDN
Issue: Ads were loading slowly in Asia and South America.
Fixes:
- CloudFront with multiple edge origins
- Global S3 buckets synced across regions
- Ad Engine deployed in
ap-southeast-1,us-west-1
DNS Strategy:
- AWS Route53 latency-based routing
- Failover to closest healthy region using health checks
PART 6: Observability at Scale
Stack:
- Metrics: Prometheus + Thanos
- Logs: Loki with structured JSON logs
- Traces: OpenTelemetry + Jaeger
Example Alert Rule (High Bidding Failures):
expr: rate(bidding_errors_total[5m]) > 50
for: 5m
labels:
severity: high
annotations:
summary: "Too many bidding failures"
Dashboards:
- Business KPIs (CTR, CPM, spend per region) via Grafana
- Infra KPIs (pod restarts, node latency, memory leaks)