



























![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)
















































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)







































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)









































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



































































































![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)





























































































































Document Versioning in OpenSearch: Database as the Source of Truth. Part 2
Best Approach: Database as the Source of Truth & OpenSearch as a Search Layer Introduction A key consideration in this strategy is document versioning. OpenSearch is not designed to maintain a history of document versions, and its handling of updates introduces important trade-offs. By leveraging a database for version control and OpenSearch for fast retrieval, applications can ensure both accuracy and performance. Why Separate the Search Layer from the Database? A database and OpenSearch serve different purposes, and using them correctly results in a more efficient system: Data integrity and versioning: A relational or NoSQL database ensures strict data consistency, transaction safety, and historical tracking. This is essential for applications where version control is required. Search performance: OpenSearch optimizes full-text search and fast lookups but lacks strong consistency mechanisms and built-in version tracking. Scalability: Keeping OpenSearch lightweight by only storing relevant indexed data makes scaling search clusters more manageable. Backups and restoration: Since OpenSearch is not the source of truth, it can be entirely recreated from the database without requiring complex backup strategies. How to Store and Organize Data Effectively Versioning and OpenSearch’s Update Model OpenSearch does not truly update documents in place. Instead, each update: Creates a new document version. Updates the index reference. Deletes the older version asynchronously. This means: The latest version is always accessible through indexing mechanisms. A slight delay in search availability is introduced, dependent on refresh_interval, cluster performance, and index size. Storing multiple versions inside OpenSearch leads to unnecessary storage overhead and increased indexing complexity. Best Practices for Versioning and Indexing Store only the latest version of a document in OpenSearch. Keep a full version history in the database to ensure traceability and compliance. For real-time accuracy, use backend logic to verify OpenSearch results against the database before presenting data to the user. Example: Using DynamoDB and a Lambda Indexer A common approach for handling versioning and indexing efficiently is using Amazon DynamoDB as the primary database and an AWS Lambda function to update OpenSearch asynchronously. DynamoDB as the Source of Truth: Stores all document versions, maintaining full historical records. Uses DynamoDB Streams to capture item modifications in real time. 2. Lambda Indexer for OpenSearch: A Lambda function is triggered by DynamoDB Streams whenever an item is modified. The function extracts the latest version and updates OpenSearch via the OpenSearch API. Ensures OpenSearch only contains the most recent document, preventing unnecessary versioning overhead. 3. Handling Deletes and Expired Versions: The Lambda function removes outdated versions from OpenSearch while retaining historical versions in DynamoDB. Ensures efficient query performance without cluttering OpenSearch with redundant versions. Example Code for a Lambda Indexer import json import boto3 from opensearchpy import OpenSearch, RequestsHttpConnection from requests_aws4auth import AWS4Auth # Configuration: update these with your details. region = 'your-region' # e.g., 'us-east-1' host = 'your-opensearch-domain' # e.g., 'search-mydomain.us-east-1.es.amazonaws.com' index_name = 'your-index-name' # Set up AWS authentication for SigV4 signing. credentials = boto3.Session().get_credentials() awsauth = AWS4Auth( credentials.access_key, credentials.secret_key, region, 'es', session_token=credentials.token ) # Initialize the OpenSearch client. client = OpenSearch( hosts=[{'host': host, 'port': 443}], http_auth=awsauth, use_ssl=True, verify_certs=True, connection_class=RequestsHttpConnection ) def lambda_handler(event, context): for record in event["Records"]: if record["eventName"] in ["INSERT", "MODIFY"]: document = record["dynamodb"]["NewImage"] doc_id = document["id"]["S"] data = { "id": doc_id, "title": document["title"]["S"], "content": document["content"]["S"], "timestamp": document["timestamp"]["S"] } response = client.index(index=index_name, id=doc_id, body=data) print("Updated document:", response) elif record["eventName"] == "REMOVE": doc_id = record["dynamodb"]["Keys"]["id"]["S"] response = client.delete(index=index_name, id=doc_id) print("Deleted document:", response) Handling Real-Time Accuracy OpenSearch’s eventual consistency model means changes are not immediately available for search. If exact real-time accuracy is required, consider implementing
Best Approach: Database as the Source of Truth & OpenSearch as a Search Layer
Introduction
A key consideration in this strategy is document versioning. OpenSearch is not designed to maintain a history of document versions, and its handling of updates introduces important trade-offs. By leveraging a database for version control and OpenSearch for fast retrieval, applications can ensure both accuracy and performance.
Why Separate the Search Layer from the Database?
A database and OpenSearch serve different purposes, and using them correctly results in a more efficient system:
- Data integrity and versioning: A relational or NoSQL database ensures strict data consistency, transaction safety, and historical tracking. This is essential for applications where version control is required.
- Search performance: OpenSearch optimizes full-text search and fast lookups but lacks strong consistency mechanisms and built-in version tracking.
- Scalability: Keeping OpenSearch lightweight by only storing relevant indexed data makes scaling search clusters more manageable.
- Backups and restoration: Since OpenSearch is not the source of truth, it can be entirely recreated from the database without requiring complex backup strategies.
How to Store and Organize Data Effectively
Versioning and OpenSearch’s Update Model
OpenSearch does not truly update documents in place. Instead, each update:
- Creates a new document version.
- Updates the index reference.
- Deletes the older version asynchronously.
This means:
- The latest version is always accessible through indexing mechanisms.
- A slight delay in search availability is introduced, dependent on
refresh_interval, cluster performance, and index size. - Storing multiple versions inside OpenSearch leads to unnecessary storage overhead and increased indexing complexity.
Best Practices for Versioning and Indexing
- Store only the latest version of a document in OpenSearch.
- Keep a full version history in the database to ensure traceability and compliance.
- For real-time accuracy, use backend logic to verify OpenSearch results against the database before presenting data to the user.
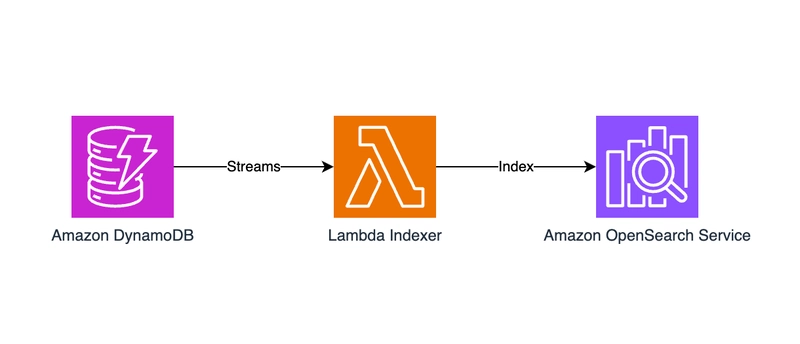
Example: Using DynamoDB and a Lambda Indexer
A common approach for handling versioning and indexing efficiently is using Amazon DynamoDB as the primary database and an AWS Lambda function to update OpenSearch asynchronously.
- DynamoDB as the Source of Truth:
- Stores all document versions, maintaining full historical records.
- Uses DynamoDB Streams to capture item modifications in real time.
2. Lambda Indexer for OpenSearch:
- A Lambda function is triggered by DynamoDB Streams whenever an item is modified.
- The function extracts the latest version and updates OpenSearch via the OpenSearch API.
- Ensures OpenSearch only contains the most recent document, preventing unnecessary versioning overhead.
3. Handling Deletes and Expired Versions:
- The Lambda function removes outdated versions from OpenSearch while retaining historical versions in DynamoDB.
- Ensures efficient query performance without cluttering OpenSearch with redundant versions.
Example Code for a Lambda Indexer
import json
import boto3
from opensearchpy import OpenSearch, RequestsHttpConnection
from requests_aws4auth import AWS4Auth
# Configuration: update these with your details.
region = 'your-region' # e.g., 'us-east-1'
host = 'your-opensearch-domain' # e.g., 'search-mydomain.us-east-1.es.amazonaws.com'
index_name = 'your-index-name'
# Set up AWS authentication for SigV4 signing.
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(
credentials.access_key,
credentials.secret_key,
region,
'es',
session_token=credentials.token
)
# Initialize the OpenSearch client.
client = OpenSearch(
hosts=[{'host': host, 'port': 443}],
http_auth=awsauth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection
)
def lambda_handler(event, context):
for record in event["Records"]:
if record["eventName"] in ["INSERT", "MODIFY"]:
document = record["dynamodb"]["NewImage"]
doc_id = document["id"]["S"]
data = {
"id": doc_id,
"title": document["title"]["S"],
"content": document["content"]["S"],
"timestamp": document["timestamp"]["S"]
}
response = client.index(index=index_name, id=doc_id, body=data)
print("Updated document:", response)
elif record["eventName"] == "REMOVE":
doc_id = record["dynamodb"]["Keys"]["id"]["S"]
response = client.delete(index=index_name, id=doc_id)
print("Deleted document:", response)
Handling Real-Time Accuracy
- OpenSearch’s eventual consistency model means changes are not immediately available for search.
- If exact real-time accuracy is required, consider implementing backend logic that cross-checks OpenSearch results against the database.
- The trade-off is complexity versus performance: OpenSearch provides ultra-fast queries, but perfect real-time accuracy requires extra processing steps.
Example Scenarios for Reducing Update Frequency
Reducing the number of updates to OpenSearch can significantly improve performance. Here are some real-world strategies:
Shop Inventory Search: Instead of storing the exact number of available products in OpenSearch, categorize availability into broader ranges like:
- “Out of Stock”
- “Limited Stock”
- “Moderate Stock”
- “Plentiful”
This reduces the frequency of updates and indexing workload.
Dynamic Pricing Optimization: Instead of storing the exact price of each item, group prices into predefined buckets that allow efficient filtering:
-
50→ Represents prices between0-5 -
100→ Represents prices between50-100 -
200→ Represents prices between100-200 -
500→ Represents prices between200-500
This method significantly reduces indexing load while maintaining the ability to perform efficient range-based searches in OpenSearch. Filtering documents based on these predefined price groups is computationally inexpensive and does not require constant reindexing when prices fluctuate.
Example: OpenSearch Index Mapping and Data Storage
Index Mapping:
{
"mappings": {
"properties": {
"id": { "type": "keyword" },
"title": { "type": "text" },
"content": { "type": "text" },
"timestamp": { "type": "date" },
"stock_level": { "type": "keyword" },
"price_range": { "type": "integer" }
}
}
}
Storing a Document:
{
"id": "12345",
"title": "High-Performance Laptop",
"content": "A powerful laptop with 16GB RAM and 512GB SSD.",
"timestamp": "2024-03-17T12:00:00Z",
"stock_level": "Moderate Stock",
"price_range": 200
}
Benefits of This Approach
- Minimizes Indexing Overhead: Price changes do not require frequent document updates.
- Efficient Filtering: OpenSearch can efficiently retrieve documents based on predefined price ranges without additional computation.
- Scalability: Suitable for large datasets with frequently changing prices and inventory levels.
Structuring Data for Performance and Scalability
OpenSearch benefits from a flat, denormalized structure:
- Avoid deeply nested objects that require complex queries.
- Eliminate the need for multiple joins across indices by storing relevant information in a single index document.
- Keeping data denormalized reduces indexing complexity and improves search performance.
Backup and Restoration Strategies
A key advantage of this approach is that OpenSearch can be entirely recreated from the database:
- If an OpenSearch cluster is lost, documents can be reindexed from the database without risk of data loss.
- This minimizes the need for frequent OpenSearch snapshots, simplifying disaster recovery and reducing operational costs.
Key Benefits of This Approach
- Improved Data Consistency: The database remains the single source of truth.
- Optimized Performance: OpenSearch is leaner, avoiding unnecessary writes and updates.
- Scalability: OpenSearch clusters remain manageable as they only store relevant indexed data.
- Simplified Maintenance: Easier disaster recovery since OpenSearch can be rebuilt from the database.
- Better Version Control: The database maintains a full history of document versions, while OpenSearch serves only the latest, reducing storage bloat and complexity.
This method is strongly recommended for applications that demand precise version control and rapid search functionality.
The subsequent sections explore alternative strategies where OpenSearch itself must manage document versioning.


