













































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)






























































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)












































































































.png?#)

































_Christophe_Coat_Alamy.jpg?#)
 (1).webp?#)





































































































![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)






























































































































Designing Data-Intensive Applications: A Summary of Reliability, Scalability, and Maintainability
Welcome to the first article in my series summarizing one of the greatest books on software engineering: Designing Data-Intensive Applications by Martin Kleppmann. This series aims to distill key concepts from the book, providing a quick refresher for those familiar with the material and a fast-paced introduction for those who prefer concise insights over reading entire books. In this article, we’ll explore three fundamental concerns in software engineering: reliability, scalability, and maintainability. These are often referred to as non-functional requirements or quality attributes. They describe how a system should behave rather than what it should do, guiding its design, development, and operation. Modern data systems often combine multiple tools to handle massive workloads. For example: Message queues like RabbitMQ, Kafka, and IBM MQ ensure reliable communication between services. In-memory databases like Redis provide low-latency access to frequently accessed data. APIs abstract away implementation details, presenting a clean interface to clients. When designing a data system or service, several questions arise: How do you ensure data remains correct and complete, even in the face of failures? How do you handle edge cases, such as network partitions or hardware failures? How do you provide good performance to clients while optimizing costs? These questions highlight the importance of reliability, scalability, and maintainability in system design. Over the next few articles, we’ll explore each of these concepts in detail, starting with reliability. Reliability Reliability means the system continues to function correctly, even in the face of faults. A reliable system ensures that data is accurate, complete, and available when needed. Reliability depends on many factors: Design Quality: Poor design or lack of proper planning can lead to frequent failures. For example, a system without fault tolerance may crash under unexpected conditions. Hardware Quality: Low-quality components or wear and tear can cause breakdowns. Redundancy (e.g., using multiple servers) can mitigate this risk. Software Bugs: Errors in the software code can lead to crashes or malfunctions. Rigorous testing and code reviews are essential to minimize bugs. Maintenance: Lack of regular updates, fixes, or testing can reduce reliability. Proactive maintenance ensures the system stays robust over time. Workload: Overloading a system beyond its capacity can cause failures. Proper capacity planning and load testing are critical. External Conditions: Environmental factors like temperature, power surges, or network issues can affect performance. Designing for resilience (e.g., backup power supplies) helps mitigate these risks. Redundancy: A lack of backup systems or fail-safes can make a system less reliable. Redundancy ensures that failures in one component don’t bring down the entire system. How to Improve Reliability Routine Maintenance: Keep systems up-to-date and modernized through regular updates and patches. Redundancy: Implement backup systems to prevent component failures from halting processes. Quality Control: Test system changes thoroughly before deploying them to production. Monitoring and Analysis: Use comprehensive data collection and analysis to understand system reliability and performance. Incident Communication: Improve communication during incidents to reduce response and recovery time. Scalability Scalability is the capacity of a system to support growth or manage an increasing volume of work. A scalable system can handle more users, data, and traffic without sacrificing speed or reliability. Why Scalability Matters Managing Growth: Scalable systems can grow with your business, accommodating more users and data without performance degradation. Improving Performance: By distributing the load across multiple servers or resources, scalable systems achieve faster processing speeds and better response times. Ensuring Availability: Scalability ensures systems remain operational even during traffic spikes or component failures. Cost-Effectiveness: Scalable systems adjust resources dynamically, avoiding over-provisioning and reducing costs. Encouraging Innovation: Scalability lowers infrastructure barriers, enabling the development of new features and services. Measuring Scalability Scalability is not a one-dimensional metric—it depends on the specific load parameters relevant to the system. These parameters vary depending on the system’s purpose. For example: Web Server: Requests per second. Database: Ratio of reads to writes, number of simultaneous active users, or cache hit rate. Chat System: Number of messages sent per second or number of concurrent connections. To describe scalability, you need to define the load parameters and their distribution. For example: A system might handle 10,000 requests per second, but if 90% of those request
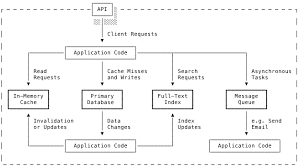
Welcome to the first article in my series summarizing one of the greatest books on software engineering: Designing Data-Intensive Applications by Martin Kleppmann. This series aims to distill key concepts from the book, providing a quick refresher for those familiar with the material and a fast-paced introduction for those who prefer concise insights over reading entire books.
In this article, we’ll explore three fundamental concerns in software engineering: reliability, scalability, and maintainability. These are often referred to as non-functional requirements or quality attributes. They describe how a system should behave rather than what it should do, guiding its design, development, and operation.
Modern data systems often combine multiple tools to handle massive workloads. For example:
Message queues like RabbitMQ, Kafka, and IBM MQ ensure reliable communication between services.
In-memory databases like Redis provide low-latency access to frequently accessed data.
APIs abstract away implementation details, presenting a clean interface to clients.
When designing a data system or service, several questions arise:
How do you ensure data remains correct and complete, even in the face of failures?
How do you handle edge cases, such as network partitions or hardware failures?
How do you provide good performance to clients while optimizing costs?
These questions highlight the importance of reliability, scalability, and maintainability in system design. Over the next few articles, we’ll explore each of these concepts in detail, starting with reliability.
Reliability
Reliability means the system continues to function correctly, even in the face of faults. A reliable system ensures that data is accurate, complete, and available when needed. Reliability depends on many factors:
Design Quality: Poor design or lack of proper planning can lead to frequent failures. For example, a system without fault tolerance may crash under unexpected conditions.
Hardware Quality: Low-quality components or wear and tear can cause breakdowns. Redundancy (e.g., using multiple servers) can mitigate this risk.
Software Bugs: Errors in the software code can lead to crashes or malfunctions. Rigorous testing and code reviews are essential to minimize bugs.
Maintenance: Lack of regular updates, fixes, or testing can reduce reliability. Proactive maintenance ensures the system stays robust over time.
Workload: Overloading a system beyond its capacity can cause failures. Proper capacity planning and load testing are critical.
External Conditions: Environmental factors like temperature, power surges, or network issues can affect performance. Designing for resilience (e.g., backup power supplies) helps mitigate these risks.
Redundancy: A lack of backup systems or fail-safes can make a system less reliable. Redundancy ensures that failures in one component don’t bring down the entire system.
How to Improve Reliability
Routine Maintenance: Keep systems up-to-date and modernized through regular updates and patches.
Redundancy: Implement backup systems to prevent component failures from halting processes.
Quality Control: Test system changes thoroughly before deploying them to production.
Monitoring and Analysis: Use comprehensive data collection and analysis to understand system reliability and performance.
Incident Communication: Improve communication during incidents to reduce response and recovery time.
Scalability
Scalability is the capacity of a system to support growth or manage an increasing volume of work. A scalable system can handle more users, data, and traffic without sacrificing speed or reliability.
Why Scalability Matters
Managing Growth: Scalable systems can grow with your business, accommodating more users and data without performance degradation.
Improving Performance: By distributing the load across multiple servers or resources, scalable systems achieve faster processing speeds and better response times.
Ensuring Availability: Scalability ensures systems remain operational even during traffic spikes or component failures.
Cost-Effectiveness: Scalable systems adjust resources dynamically, avoiding over-provisioning and reducing costs.
Encouraging Innovation: Scalability lowers infrastructure barriers, enabling the development of new features and services.
Measuring Scalability
Scalability is not a one-dimensional metric—it depends on the specific load parameters relevant to the system. These parameters vary depending on the system’s purpose. For example:
Web Server: Requests per second.
Database: Ratio of reads to writes, number of simultaneous active users, or cache hit rate.
Chat System: Number of messages sent per second or number of concurrent connections.
To describe scalability, you need to define the load parameters and their distribution. For example:
- A system might handle 10,000 requests per second, but if 90% of those requests are for the same piece of data (e.g., a popular video or post), the load distribution is skewed, and the system must be designed to handle such cases.
How to Scale
Before scaling, you need to understand your system’s load parameters and performance goals. Then, choose a scaling strategy:
Vertical Scaling (Scaling Up): Add more resources (e.g., CPU, memory, disk) to a single machine. This is simple but limited by the machine’s maximum capacity.
Horizontal Scaling (Scaling Out): Add more machines to distribute the load. This is more complex but offers greater scalability and fault tolerance.
Other techniques include:
Partitioning (Sharding): Split data across multiple machines to distribute the load.
Replication: Store copies of data on multiple machines for fault tolerance and read scalability.
Caching: Store frequently accessed data in fast storage (e.g., Redis) to reduce latency.
Asynchronous Processing: Use message queues (e.g., Kafka) to decouple tasks and handle them in the background.
Autoscaling: Automatically add or remove resources based on load.
Maintainability
Maintainability is the ability of a system to undergo repairs and modifications while remaining operational. A maintainable system is easy to understand, modify, and operate over time.
Principles of Maintainability
- Operability: Make it easy for operations teams to keep the system running smoothly. This includes:
Providing good monitoring and alerting tools.
Documenting runbooks for common operational tasks.
Designing for automation (e.g., automated backups and scaling).
- Simplicity: Keep the system as simple as possible, avoiding unnecessary complexity. This involves:
Using abstractions to hide implementation details.
Following the KISS principle (Keep It Simple, Stupid).
Refactoring regularly to remove technical debt.
- Evolvability: Make it easy to adapt the system to changing requirements. This requires:
Designing for modularity (e.g., microservices, well-defined interfaces).
-
Using backward-compatible changes (e.g., versioned APIs).
- Writing tests to ensure changes don’t break existing functionality.
How to Improve Maintainability
Good Documentation: Document the system’s architecture, APIs, and operational procedures.
Modular Design: Break the system into small, independent components with clear interfaces.
Automated Testing: Write unit, integration, and end-to-end tests to catch bugs early.
Monitoring and Observability: Use metrics, logs, and distributed tracing to detect and diagnose issues quickly.
Version Control and CI/CD: Use version control (e.g., Git) and CI/CD pipelines to manage changes efficiently.
Conclusion
In this article, we explored the three pillars of system design: reliability, scalability, and maintainability. These non-functional requirements are critical for building systems that are robust, efficient, and adaptable over time. By understanding and applying these principles, you can design systems that meet the demands of modern applications.
In the next article, we’ll dive deeper into data models and query languages, exploring how different models (e.g., relational, document, graph) shape the design of data-intensive systems. Thank you for reading, and if you have any feedback or suggestions, please let me know in the comments!



