![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)






























































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.png?#)

































_Christophe_Coat_Alamy.jpg?#)
 (1).webp?#)






































































































![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)
![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)





























































































































Demystifying AI model selection
AI model selection can be a daunting task. With so many models, so many versions of the same model, and so many benchmarks, how do you decide what to pick? And what are these obnoxiously long names like Qwen2.5-VL-32B-Instruct-bnb-4bit? HuggingFace is the best place to explore various models that are available for fine-tuning and further study. It can be a daunting site before you understand what these model specifics mean. Fortunately, there’s (usually) a method to the madness. Below, we outline how to think about AI model selection for any given use case. This article is part of a series on fine-tuning tips and best practices. See the most recent article in the series where we discussed AI dataset construction here. 1. Eval vibe checks The first step to selecting an AI model is performing a vibe check on the state of the art (SOTA). Checking the latest model releases from reputable AI players is usually a safe start. Evals aren’t everything, but they are worth looking at as a starting point. Often, companies will share their evals as big charts, usually quite favorably to themselves, leaving out competitor models that outperform them and evaluations that they underperform on. You’ll need to dig and build your comparisons as you pit models against one another. Here’s a neutral eval that showcases the capabilities across the entire Qwen2.5 Coder line - from the smallest parameter version 0.5B to 32B. There are many evals out there, but many are quite common. Here are a few of the most common code evals briefly explained: HumanEval: Small Python-based coding eval by OpenAI MBPP: Basic Python code but larger than HumanEval by Google EvalPlus: Larger Python eval meant to catch models that are overfitted to HumanEval and MBPP by OpenCompass MultiPL-E: HumanEval translated to a bunch of coding languages by HuggingFace and BigCode McEval: Multiple choice (Mc) eval to test reasoning, tests a model’s ability to pick the best code, not generation by OpenCompass LiveCodeBench: Multi-language code eval with lots of cases by Tsinghua University CodeArena: Crowd-sourced human evaluation is where humans rank the outputs of two models and pick the best solution. The primary goal of looking at evals is finding a few model families you’d like to experiment with and then, within those families, seeing the performance gaps between models of various sizes within the same model family. It’s good to understand the basics of evals to understand which ones ensure a model isn’t overfitted to the most popular benchmarks like HumanEval. 2. Model size It’s generally the case that the fewer parameters a model has, the smaller its size, and thus, the lower its memory footprint and higher its speed. If your problem is easily solved with a 7B model, then it’d make no sense to run a 32B model; that’d be a waste of money and would slow down responses. Many of the advantages of fine-tuning come from achieving the speed, cost, and memory footprint of a much larger model out of a smaller model. General advice is to start small and work your way up to larger models as needed. It does seem that the ability to solve complex problems starts to emerge around ~10B parameters, but increasingly, models are being released that are smaller and smaller with more capabilities. Play around with various model sizes and see where you land for your use case. Often, model size is a much more relevant consideration than model family, especially for models released at similar times. 3. Base vs Instruct vs Chat vs Code First, some definitions: Pre-training is the main step that model providers take for training. It is done on huge data corpora, usually takes a long time, and requires huge amounts of compute. Fine-tuning: task-specific training that model providers can do or, more commonly, by developers downstream Models come in a few different forms - some are just the Base model as it was initially pre-trained, and others are fine-tuned versions from the model provider or from companies and hobbyists with specific use cases. These are the most common suffixes in a model ID related to how a model was trained. Base: This is the pre-trained model, usually without fine-tuning, trained on large data corpora like literature, code repos, social media, etc. Instruct: This is a base model that has been fine-tuned for instruction following, e.g. assistants Chat: self-explanatory, base model fine-tuned for chat applications (multi-turn chats) Code: self-explanatory, base model fine-tuned to focus on coding VL: vision language, meaning the model is multi-modal It often makes sense for fine-tuning applications to start with Instruct models, especially when your dataset (we talked about constructing AI training datasets here) is smaller and you want to improve the instructions to work for your use case. 4. Model purpose & training data Model providers often focus on specific use cases to build models that
AI model selection can be a daunting task. With so many models, so many versions of the same model, and so many benchmarks, how do you decide what to pick? And what are these obnoxiously long names like Qwen2.5-VL-32B-Instruct-bnb-4bit?
HuggingFace is the best place to explore various models that are available for fine-tuning and further study. It can be a daunting site before you understand what these model specifics mean.
Fortunately, there’s (usually) a method to the madness. Below, we outline how to think about AI model selection for any given use case.
This article is part of a series on fine-tuning tips and best practices. See the most recent article in the series where we discussed AI dataset construction here.
1. Eval vibe checks
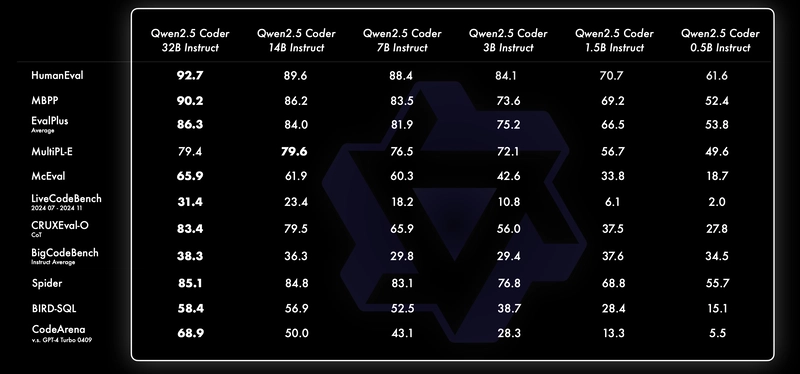
The first step to selecting an AI model is performing a vibe check on the state of the art (SOTA). Checking the latest model releases from reputable AI players is usually a safe start. Evals aren’t everything, but they are worth looking at as a starting point. Often, companies will share their evals as big charts, usually quite favorably to themselves, leaving out competitor models that outperform them and evaluations that they underperform on. You’ll need to dig and build your comparisons as you pit models against one another.
Here’s a neutral eval that showcases the capabilities across the entire Qwen2.5 Coder line - from the smallest parameter version 0.5B to 32B.
There are many evals out there, but many are quite common. Here are a few of the most common code evals briefly explained:
HumanEval: Small Python-based coding eval by OpenAI
MBPP: Basic Python code but larger than HumanEval by Google
EvalPlus: Larger Python eval meant to catch models that are overfitted to HumanEval and MBPP by OpenCompass
MultiPL-E: HumanEval translated to a bunch of coding languages by HuggingFace and BigCode
McEval: Multiple choice (Mc) eval to test reasoning, tests a model’s ability to pick the best code, not generation by OpenCompass
LiveCodeBench: Multi-language code eval with lots of cases by Tsinghua University
CodeArena: Crowd-sourced human evaluation is where humans rank the outputs of two models and pick the best solution.
The primary goal of looking at evals is finding a few model families you’d like to experiment with and then, within those families, seeing the performance gaps between models of various sizes within the same model family. It’s good to understand the basics of evals to understand which ones ensure a model isn’t overfitted to the most popular benchmarks like HumanEval.
2. Model size
It’s generally the case that the fewer parameters a model has, the smaller its size, and thus, the lower its memory footprint and higher its speed. If your problem is easily solved with a 7B model, then it’d make no sense to run a 32B model; that’d be a waste of money and would slow down responses.
Many of the advantages of fine-tuning come from achieving the speed, cost, and memory footprint of a much larger model out of a smaller model. General advice is to start small and work your way up to larger models as needed.
It does seem that the ability to solve complex problems starts to emerge around ~10B parameters, but increasingly, models are being released that are smaller and smaller with more capabilities. Play around with various model sizes and see where you land for your use case. Often, model size is a much more relevant consideration than model family, especially for models released at similar times.
3. Base vs Instruct vs Chat vs Code
First, some definitions:
Pre-training is the main step that model providers take for training. It is done on huge data corpora, usually takes a long time, and requires huge amounts of compute.
Fine-tuning: task-specific training that model providers can do or, more commonly, by developers downstream
Models come in a few different forms - some are just the Base model as it was initially pre-trained, and others are fine-tuned versions from the model provider or from companies and hobbyists with specific use cases.
These are the most common suffixes in a model ID related to how a model was trained.
Base: This is the pre-trained model, usually without fine-tuning, trained on large data corpora like literature, code repos, social media, etc.
Instruct: This is a base model that has been fine-tuned for instruction following, e.g. assistants
Chat: self-explanatory, base model fine-tuned for chat applications (multi-turn chats)
Code: self-explanatory, base model fine-tuned to focus on coding
VL: vision language, meaning the model is multi-modal
It often makes sense for fine-tuning applications to start with Instruct models, especially when your dataset (we talked about constructing AI training datasets here) is smaller and you want to improve the instructions to work for your use case.
4. Model purpose & training data
Model providers often focus on specific use cases to build models that are especially capable of certain tasks. For example, Claude is well known to outperform GPT-4o in most coding tasks, but OpenAI has plenty of writing scenarios where it’s deemed superior. The same can be seen in open source models; some examples:
Alibaba’s QwenCoder: as the name suggests, this model excels at code tasks
Google Gemma: advanced multi-modal capabilities
Microsoft Phi-4: for code, the training data is heavily biased toward Python
Many of the most popular benchmarks are focused on Python, so it’s not surprising that the model providers are especially attentive to performing well with Python.
5. Quantization
Quantization is an option if we need to reduce our model footprint. Doing so can significantly reduce the model size, with a minor negative impact on model performance but a large positive impact on speed.
Float16 is a very standard high-bit data format. You can expect to use float16 as a standard for commercial applications. But sometimes, you might not have the hardware available to host at float16, so you can quantize down to smaller formats as necessary (while being okay with the minor performance hit). These quantized models will run significantly faster and require much less space. Some standard formats to quantize into include int8 and 4-bit. If you see a model name with a suffix like 4bit at the end, it’s a quantized version of the model to 4-bit.
6. Licenses
Author of this post is not a lawyer. Take license opinions with a grain of salt. Consult with your own counsel.
Licenses are an important consideration depending on your use case. They can span everywhere from fully permissive to completely non-permissive. Below are some examples to showcase why licenses might impact the model you choose among the current SOTA.
MIT (open source, fully permissive): Some of ****Microsoft’s Phi models
Apache 2.0 (open source, very permissive): (Most of) Alibaba’s Qwen models, Mistral
Custom licenses (sometimes very permissive, other times not): Google’s Gemma, Meta’s Llama
Fully proprietary: Vast majority of OpenAI and Anthropic’s models
Depending on your use case, whether you’re a hobbyist or a company, and many other considerations, you’ll want to find the license that best fits your use case.
Not your weights, not your model.
Conclusion
Hopefully, you’re walking away with some ideas on how to improve your model selection. Ideally, you’ve walked away from this article understanding how to read a model ID like Qwen2.5-VL-32B-Instruct-bnb-4bit. Here’s the reminder for Qwen2.5-VL-32B-Instruct-bnb-4bit:
Qwen2.5: model family and version
VL: model purpose (pre-trained for vision-language)
32B: number of parameters (32 billion trainable neural network weights)
Instruct: fine-tuned for instruction following
bnb-4bit: BitsAndBytes 4-bit quantization
Interested in learning more? This article is part of a series on AI fine-tuning. You can read the most recent article on dataset construction here.