![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)





















































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)










































































































![M4 MacBook Air Drops to Just $849 - Act Fast! [Lowest Price Ever]](https://www.iclarified.com/images/news/97140/97140/97140-640.jpg)












_roibu_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




 CISO’s Core Focus.webp?#)







































































































![Apple Smart Glasses Not Close to Being Ready as Meta Targets 2025 [Gurman]](https://www.iclarified.com/images/news/97139/97139/97139-640.jpg)
![iPadOS 19 May Introduce Menu Bar, iOS 19 to Support External Displays [Rumor]](https://www.iclarified.com/images/news/97137/97137/97137-640.jpg)
































































































Databases: Concurrency Control. Part 1
Introduction Imagine you're working in a busy office with multiple people trying to update the same spreadsheet at the same time. One person is adding new information, while another is making changes to existing data. At the same time, others are just looking at the document, but they need to see the latest, accurate version of the data. In this situation, how can we ensure that: People making changes don’t accidentally overwrite each other’s work ? People who are just reading the document always see the most up-to-date version, without waiting for someone else to finish their work ? The document doesn't end up in a jumbled state ? Now, imagine this happening in a database, where multiple users or applications are trying to read from and write to the same tables at the same time. The challenge is even bigger in this case because databases are designed to store huge amounts of data, and many transactions need to happen simultaneously. Why Is Concurrency Hard in Databases ? When multiple users or processes are interacting with the database at once, several things can go wrong: Data consistency issues - One user might see outdated information because another user is changing it. Locking problems - If one transaction locks a row, other transactions might have to wait, leading to delays and frustration. Concurrency anomalies - Without the right mechanisms in place, transactions could lead to inconsistent results, such as one user overwriting another’s work. Databases need to figure out how to let users work simultaneously without blocking each other, and also make sure the data stays consistent and correct no matter how many people are using it. What is MVCC ? The solution lies in using techniques that allow each transaction to see a consistent snapshot of the data, without interfering with other transactions. One of the most powerful and widely used techniques in modern databases - is called Multiversion Concurrency Control. It is a method that enables multiple transactions to access the database simultaneously without blocking each other. This is accomplished by creating multiple versions of a piece of data, instead of having just one active version at any time. In an MVCC-based system, when data is updated or inserted, a new version of the row is created. However, if a transaction only reads the data without modifying it, it accesses the original version of the data. This ensures that read operations are not blocked by write operations, and write operations do not block reads. As a result, the new version of the data becomes visible only after a modification or insertion occurs, allowing concurrent transactions to work with different versions of the same data without causing interference. This approach enables databases to maintain data consistency and high concurrency while minimizing the need for locking resources. Example of MVCC in Action Let's say three transactions, T1, T2, and T3, are operating on the same row in the database: Transaction T1 reads a row and decides to update it. This creates version 2 of the row. Transaction T2 also reads the same row (before T1 has committed) and performs a different update, creating version 3 of the row. Transaction T3 reads the row as well and decides to insert a new value, creating version 4. At this point, there are three versions of the same row, each with different updates from different transactions. The database now has to manage and ensure that the operations from these transactions do not interfere with each other. In the next parts of this article, we will explore how the database resolves conflicts when multiple transactions try to modify the same data. This conflict resolution ensures that data consistency is maintained and that transactions are isolated properly The Hidden Cost of MVCC: Bloat While Multiversion Concurrency Control offers many benefits, such as high concurrency and reduced locking, it comes with its own set of challenges. One of the most significant drawbacks of MVCC is bloat. In this section, we’ll explore what bloat is, how it occurs in MVCC systems, and its impact on database performance. Bloat refers to the buildup of unused, outdated, or "dead" data versions in the database, resulting from the creation of multiple row versions due to MVCC. As time passes, these obsolete versions accumulate and consume storage space, leading to inefficient resource usage. As bloat increases, it introduces several negative effects on both storage and performance. The presence of outdated data versions creates inefficiencies that can worsen over time. If left unmanaged, these inefficiencies can significantly degrade the overall health and performance of the database. Let’s explore how bloat can impact the database’s functionality in more detail: Increased Storage Usage
Introduction
Imagine you're working in a busy office with multiple people trying to update the same spreadsheet at the same time. One person is adding new information, while another is making changes to existing data. At the same time, others are just looking at the document, but they need to see the latest, accurate version of the data. In this situation, how can we ensure that:
- People making changes don’t accidentally overwrite each other’s work ?
- People who are just reading the document always see the most up-to-date version, without waiting for someone else to finish their work ?
- The document doesn't end up in a jumbled state ?
Now, imagine this happening in a database, where multiple users or applications are trying to read from and write to the same tables at the same time. The challenge is even bigger in this case because databases are designed to store huge amounts of data, and many transactions need to happen simultaneously.
Why Is Concurrency Hard in Databases ?
When multiple users or processes are interacting with the database at once, several things can go wrong:
- Data consistency issues - One user might see outdated information because another user is changing it.
- Locking problems - If one transaction locks a row, other transactions might have to wait, leading to delays and frustration.
- Concurrency anomalies - Without the right mechanisms in place, transactions could lead to inconsistent results, such as one user overwriting another’s work.
Databases need to figure out how to let users work simultaneously without blocking each other, and also make sure the data stays consistent and correct no matter how many people are using it.
What is MVCC ?
The solution lies in using techniques that allow each transaction to see a consistent snapshot of the data, without interfering with other transactions. One of the most powerful and widely used techniques in modern databases - is called Multiversion Concurrency Control. It is a method that enables multiple transactions to access the database simultaneously without blocking each other. This is accomplished by creating multiple versions of a piece of data, instead of having just one active version at any time.
In an MVCC-based system, when data is updated or inserted, a new version of the row is created. However, if a transaction only reads the data without modifying it, it accesses the original version of the data. This ensures that read operations are not blocked by write operations, and write operations do not block reads. As a result, the new version of the data becomes visible only after a modification or insertion occurs, allowing concurrent transactions to work with different versions of the same data without causing interference. This approach enables databases to maintain data consistency and high concurrency while minimizing the need for locking resources.
Example of MVCC in Action
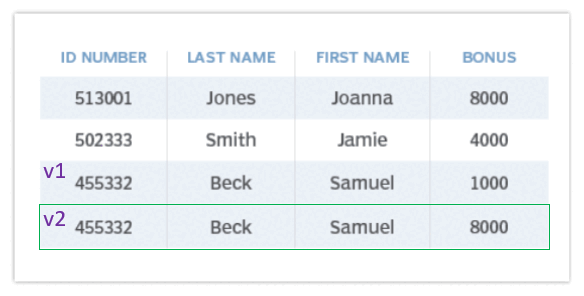
Let's say three transactions, T1, T2, and T3, are operating on the same row in the database:
- Transaction T1 reads a row and decides to update it. This creates version 2 of the row.
- Transaction T2 also reads the same row (before T1 has committed) and performs a different update, creating version 3 of the row.
- Transaction T3 reads the row as well and decides to insert a new value, creating version 4.
At this point, there are three versions of the same row, each with different updates from different transactions. The database now has to manage and ensure that the operations from these transactions do not interfere with each other. In the next parts of this article, we will explore how the database resolves conflicts when multiple transactions try to modify the same data. This conflict resolution ensures that data consistency is maintained and that transactions are isolated properly
The Hidden Cost of MVCC: Bloat
While Multiversion Concurrency Control offers many benefits, such as high concurrency and reduced locking, it comes with its own set of challenges. One of the most significant drawbacks of MVCC is bloat. In this section, we’ll explore what bloat is, how it occurs in MVCC systems, and its impact on database performance.
Bloat refers to the buildup of unused, outdated, or "dead" data versions in the database, resulting from the creation of multiple row versions due to MVCC. As time passes, these obsolete versions accumulate and consume storage space, leading to inefficient resource usage. As bloat increases, it introduces several negative effects on both storage and performance. The presence of outdated data versions creates inefficiencies that can worsen over time. If left unmanaged, these inefficiencies can significantly degrade the overall health and performance of the database. Let’s explore how bloat can impact the database’s functionality in more detail:
Increased Storage Usage