










































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)



















































































































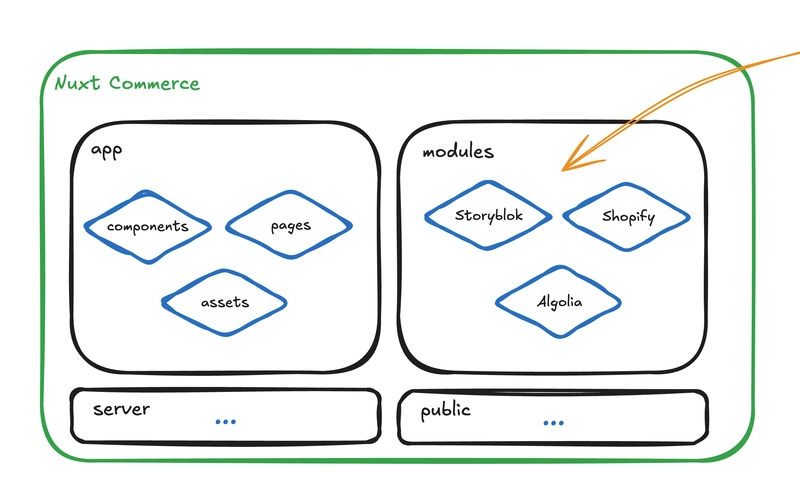














![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.png?#)

































_Christophe_Coat_Alamy.jpg?#)



.webp?#)






































































































![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)
![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)

























































































































Computación Eficiente · Nº1
¡Bienvenidos al mundo de la computación eficiente! ¿Por qué nace esta newsletter? La inteligencia artificial nos maravilla: modelos que escriben, predicen y hasta razonan. Pero hay un lado oculto: entrenar uno de estos gigantes puede emitir más carbono que un vuelo transatlántico. Y no es solo cosa de IA: desde una Raspberry Pi hasta un clúster de GPUs, cada watt cuenta. Esta newsletter te trae lo último en herramientas, ideas y técnicas para optimizar al máximo. Hablaremos mucho de AWS, pero también exploraremos investigaciones y trucos que nos inspiran, sin importar de dónde vengan. Nuestra misión: que hagas más con menos, sin sacrificar potencia. Destacado: chips que piensan como el cerebro From Bug to Brain: el “error” que puede revolucionar los chips En los chips actuales, el punch-through (una fuga de corriente en transistores) suele ser un dolor de cabeza: desperdicia energía y causa fallos. Pero un estudio reciente ha dado un giro inesperado: controlando esa "fuga", lograron que dos transistores imiten una neurona, disparando spikes como en nuestro cerebro. Resultado: chips de IA más simples y eficientes, sin materiales exóticos. ¿El futuro de la computación? Nature – Leer artículo AWS al día: potencia sin derroche Aerospike + Graviton4: rapidez que ahorra Aerospike es una base de datos en tiempo real usada en publicidad programática, detección de fraude, etc. En este tipo de entornos, los milisegundos cuentan. Usando instancias Graviton4, Aerospike logró: 6 veces más rendimiento sostenido Hasta 99% menos latencia en operaciones pico Esto no solo reduce costes: gastas menos energía por transacción, haces más con el mismo hardware y además reduces emisiones. Leer benchmark Pruébalo tú mismo Serverless ligero = bolsillos felices A medida que los payloads crecen (en e-commerce, analítica o IA), chocas con límites: Lambda (6MB), SQS (256KB)… ¿La solución? ¡Comprimir los datos antes de enviarlos! Con un simple gzip + Base64, puedes reducir el tamaño de los datos en un 80%, ahorrar en tráfico de red, evitar NAT Gateways (¿quién no ha oído a Corey Quinn quejarse?) y acelerar tus funciones Lambda. Sí, comprimir consume algo de CPU, pero si usas Lambda sobre Graviton con memoria optimizada, el balance es claramente positivo. AWS estima un ahorro de hasta $300 por cada 10 millones de invocaciones. Optimiza tu stack aquí Bottlerocket + NVIDIA MIG: una GPU, mil tareas Ahora puedes dividir una GPU en varias particiones independientes gracias a MIG (Multi-Instance GPU) y usar cada una para tareas distintas: inferencia, entrenamiento, simulaciones… Con Bottlerocket (el sistema operativo minimalista de AWS para contenedores), esto se vuelve mucho más fácil de gestionar y más seguro. Cómo habilitarlo Bottlerocket ahora más simple: bootstrap sin dolor Bottlerocket, acaba de simplificar todavía más la vida de quienes despliegan clústeres. Ahora incluye una imagen de bootstrap por defecto, lo que significa que ya no necesitas crear y mantener tus propias imágenes de arranque para hacer configuraciones previas al inicio. ¿Qué hace esta imagen? Antes de que arranquen tus contenedores de aplicación, se encarga de: Crear directorios necesarios Configurar variables de entorno Aplicar ajustes específicos al nodo Antes: tú mantenías una imagen personalizada para esto en cada región. Ahora: basta con un script en user data y Bottlerocket se encarga de todo. Beneficios Menos mantenimiento de imágenes Más seguridad (AWS mantiene las actualizaciones) Configuración más sencilla y portable Documentación oficial Repositorio en GitHub LLMs sin GPU: sí, es real ¿Y si pudieras correr modelos como Qwen 2.5B sin GPU? Con Graviton en SageMaker puedes lanzar endpoints con modelos pequeños (SLMs) usando solo CPU ARM, con buen rendimiento y mucho menor coste operativo. Además, puedes escalar automáticamente, integrar métricas y no preocuparte de la infraestructura. Guía paso a paso Graviton4 y SVE2: optimiza en tiempo real Cada nueva generación de procesadores AWS Graviton trae mejoras. En el caso de Graviton4, una de las más potentes es SVE2. ¿Qué es SVE2? SVE2 (Scalable Vector Extension v2) es una tecnología que permite al procesador realizar operaciones vectoriales, es decir, procesar muchos datos a la vez en paralelo. Esto es especialmente útil en cargas de trabajo como Machine Learning, análisis de datos, video y señal digital, o simulaciones científicas Con getauxval(AT_HWCAP2) puedes detectar capacidades del procesador en tiempo de ejecución, y adaptar tu código automáticamente. Así escribes una sola versión que escala según la máquina donde se ejecuta. Leer guía técnica Continuous Profiling: eficiencia con datos reales ¿Sabes por qué tu app usa tanta CPU en producción? Grafana Cloud ahora permite con

¡Bienvenidos al mundo de la computación eficiente!
¿Por qué nace esta newsletter?
La inteligencia artificial nos maravilla: modelos que escriben, predicen y hasta razonan. Pero hay un lado oculto: entrenar uno de estos gigantes puede emitir más carbono que un vuelo transatlántico. Y no es solo cosa de IA: desde una Raspberry Pi hasta un clúster de GPUs, cada watt cuenta.
Esta newsletter te trae lo último en herramientas, ideas y técnicas para optimizar al máximo. Hablaremos mucho de AWS, pero también exploraremos investigaciones y trucos que nos inspiran, sin importar de dónde vengan. Nuestra misión: que hagas más con menos, sin sacrificar potencia.
Destacado: chips que piensan como el cerebro
From Bug to Brain: el “error” que puede revolucionar los chips
En los chips actuales, el punch-through (una fuga de corriente en transistores) suele ser un dolor de cabeza: desperdicia energía y causa fallos. Pero un estudio reciente ha dado un giro inesperado: controlando esa "fuga", lograron que dos transistores imiten una neurona, disparando spikes como en nuestro cerebro.
Resultado: chips de IA más simples y eficientes, sin materiales exóticos. ¿El futuro de la computación?
AWS al día: potencia sin derroche
Aerospike + Graviton4: rapidez que ahorra
Aerospike es una base de datos en tiempo real usada en publicidad programática, detección de fraude, etc. En este tipo de entornos, los milisegundos cuentan.
Usando instancias Graviton4, Aerospike logró:
- 6 veces más rendimiento sostenido
- Hasta 99% menos latencia en operaciones pico
Esto no solo reduce costes: gastas menos energía por transacción, haces más con el mismo hardware y además reduces emisiones.
Leer benchmark
Pruébalo tú mismo
Serverless ligero = bolsillos felices
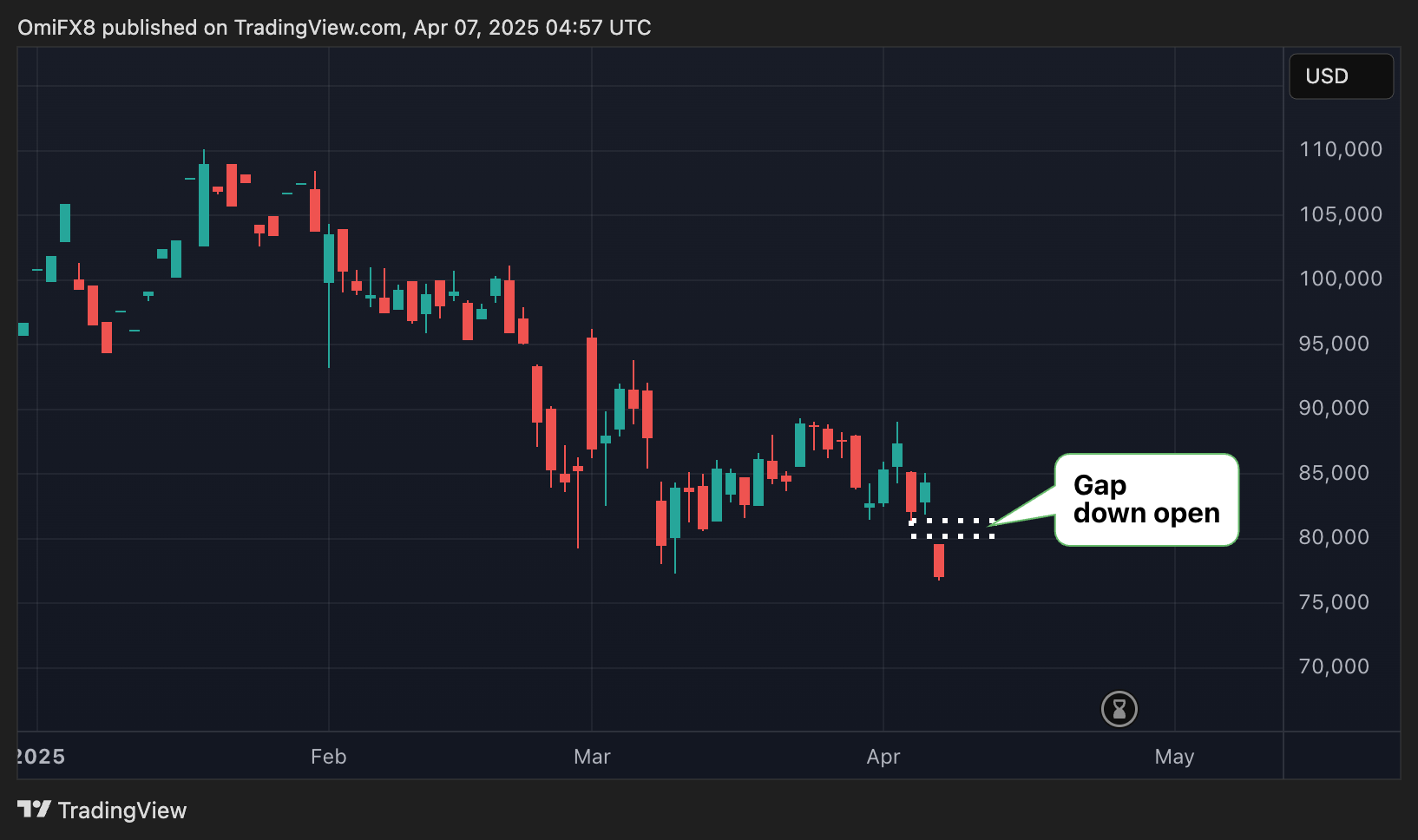
A medida que los payloads crecen (en e-commerce, analítica o IA), chocas con límites: Lambda (6MB), SQS (256KB)…
¿La solución? ¡Comprimir los datos antes de enviarlos!
Con un simple gzip + Base64, puedes reducir el tamaño de los datos en un 80%, ahorrar en tráfico de red, evitar NAT Gateways (¿quién no ha oído a Corey Quinn quejarse?) y acelerar tus funciones Lambda.
Sí, comprimir consume algo de CPU, pero si usas Lambda sobre Graviton con memoria optimizada, el balance es claramente positivo.
AWS estima un ahorro de hasta $300 por cada 10 millones de invocaciones.
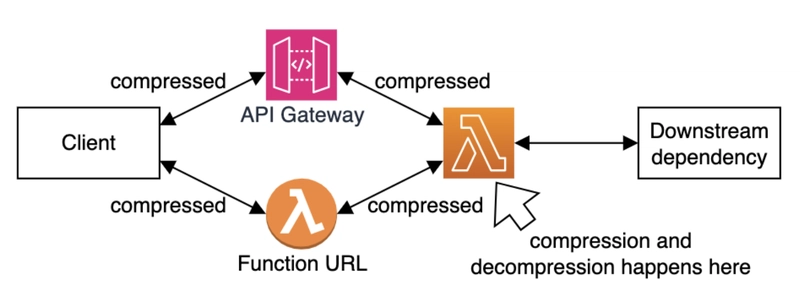
Bottlerocket + NVIDIA MIG: una GPU, mil tareas
Ahora puedes dividir una GPU en varias particiones independientes gracias a MIG (Multi-Instance GPU) y usar cada una para tareas distintas: inferencia, entrenamiento, simulaciones…
Con Bottlerocket (el sistema operativo minimalista de AWS para contenedores), esto se vuelve mucho más fácil de gestionar y más seguro.
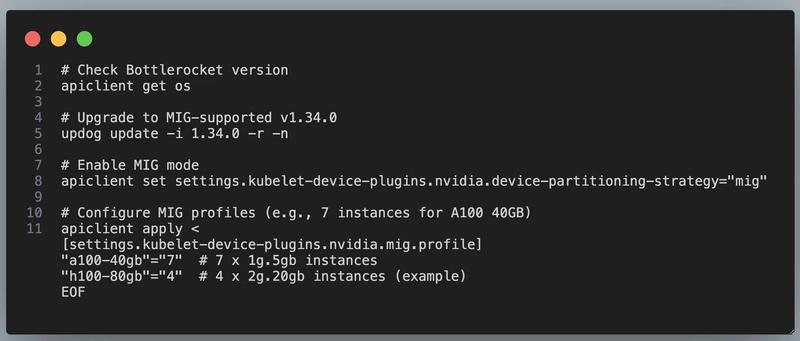
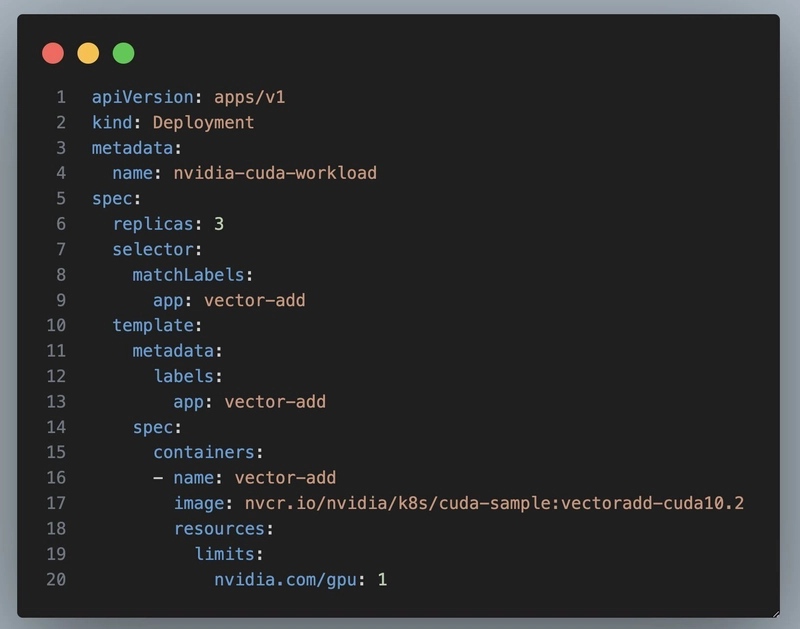
Bottlerocket ahora más simple: bootstrap sin dolor
Bottlerocket, acaba de simplificar todavía más la vida de quienes despliegan clústeres.
Ahora incluye una imagen de bootstrap por defecto, lo que significa que ya no necesitas crear y mantener tus propias imágenes de arranque para hacer configuraciones previas al inicio.
¿Qué hace esta imagen?
Antes de que arranquen tus contenedores de aplicación, se encarga de:
- Crear directorios necesarios
- Configurar variables de entorno
- Aplicar ajustes específicos al nodo
Antes: tú mantenías una imagen personalizada para esto en cada región.
Ahora: basta con un script en user data y Bottlerocket se encarga de todo.
Beneficios
- Menos mantenimiento de imágenes
- Más seguridad (AWS mantiene las actualizaciones)
- Configuración más sencilla y portable
Documentación oficial
Repositorio en GitHub
LLMs sin GPU: sí, es real
¿Y si pudieras correr modelos como Qwen 2.5B sin GPU?
Con Graviton en SageMaker puedes lanzar endpoints con modelos pequeños (SLMs) usando solo CPU ARM, con buen rendimiento y mucho menor coste operativo.
Además, puedes escalar automáticamente, integrar métricas y no preocuparte de la infraestructura.
Graviton4 y SVE2: optimiza en tiempo real
Cada nueva generación de procesadores AWS Graviton trae mejoras. En el caso de Graviton4, una de las más potentes es SVE2.
¿Qué es SVE2?
SVE2 (Scalable Vector Extension v2) es una tecnología que permite al procesador realizar operaciones vectoriales, es decir, procesar muchos datos a la vez en paralelo.
Esto es especialmente útil en cargas de trabajo como Machine Learning, análisis de datos, video y señal digital, o simulaciones científicas
Con getauxval(AT_HWCAP2) puedes detectar capacidades del procesador en tiempo de ejecución, y adaptar tu código automáticamente.
Así escribes una sola versión que escala según la máquina donde se ejecuta.
Continuous Profiling: eficiencia con datos reales
¿Sabes por qué tu app usa tanta CPU en producción?
Grafana Cloud ahora permite conectar k6 (testing de carga) con Pyroscope (profiling).
Esto te permite:
- Ver qué funciones consumen más CPU/memoria bajo carga
- Detectar fugas o regresiones antes de que lleguen a producción
- Comparar ejecuciones en CI/CD
Si usas AWS:
- Despliega Pyroscope en EC2 (Graviton)
- Usa Lambda ARM + SDK Pyroscope
- Integra todo en tus pipelines
Truco rápido: una línea que cambia todo
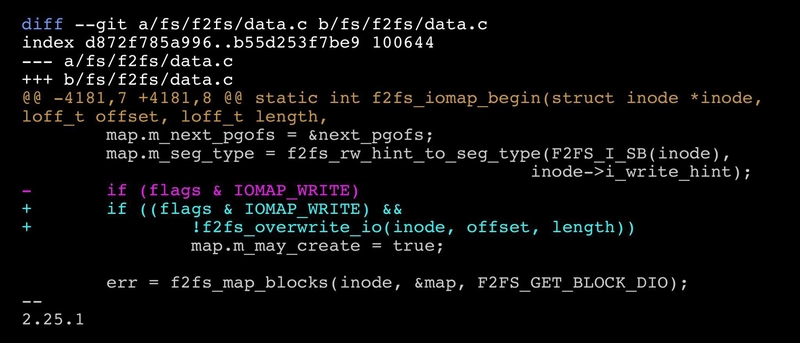
¿Se puede mejorar el rendimiento de un sistema de archivos con solo una línea de código?
Un ingeniero de SK Telecom optimizó F2FS (un sistema de archivos para SSD) con una sola línea de código. ¿Cómo? Eliminó un paso innecesario al escribir datos. Resultado: escrituras más rápidas en bases de datos y apps intensivas. A veces, la magia está en lo simple.
Inspiración más allá de AWS
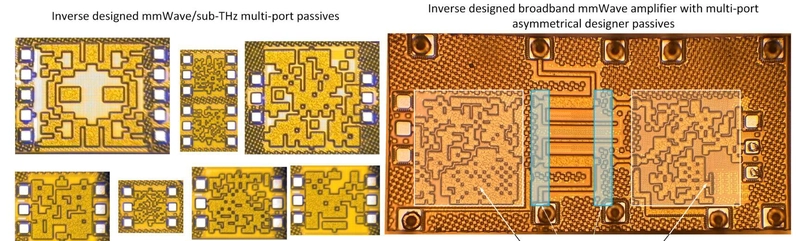
Inverse Design: chips optimizados por IA
Investigadores de Princeton han creado un sistema de IA que diseña circuitos de alta frecuencia en minutos (antes tomaba semanas).
Esto puede revolucionar el diseño de componentes para 5G, radar, chips cloud, etc.
Exo 2: el lenguaje que optimiza kernels
El MIT ha lanzado Exo 2, un lenguaje donde tú decides cómo se optimiza cada operación.
Es como decirle al compilador: "así quiero que lo hagas".
Con solo 2,000 líneas, Exo 2 ha igualado o superado a librerías como MKL y OpenBLAS en más de 80 kernels de alto rendimiento.
Raspberry Pi más eficientes y seguras
Con la nueva herramienta rpi-image-gen, puedes crear imágenes personalizadas para tus Raspberry Pi:
- Control total sobre paquetes, particiones, configuraciones
- Genera archivos SBOM para auditorías de seguridad
- Ideal para entornos industriales o IoT

¿Y tú, qué opinas?
La eficiencia no es solo tecnología: es un mindset. Nos ahorra dinero, tiempo y emisiones...y mejora la resiliencia de tu arquitectura.
Esperamos que os haya parecido interesante. ¿Tienes un truco, una idea o una historia? ¡Cuéntanos!
Nos vemos en el próximo número,
El equipo de Computación Eficiente



