![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






















































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)



























































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



























































































![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)
































































































































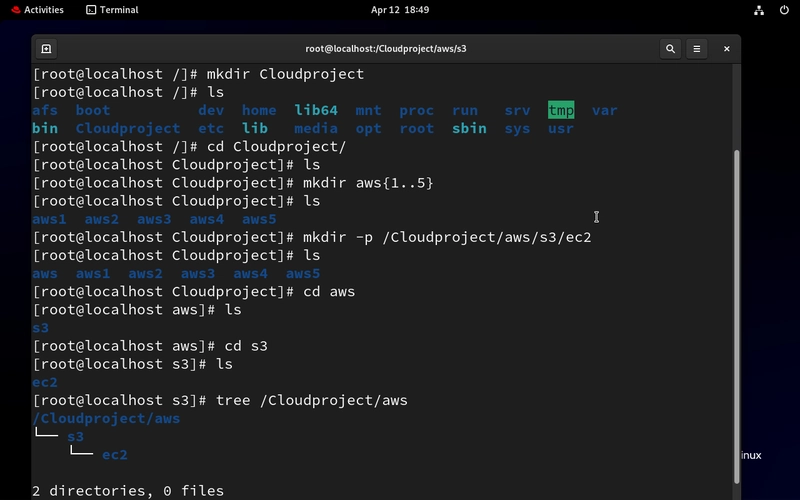
C4D VMs on Google Cloud: Breaking Records Again with EPYC Turin
Over the past year, Google Cloud has been rolling out its fourth-gen compute VMs. First came the Intel-powered c4, which did much better than past Intel instances in my 2024 Cloud Comparison, but ultimately wasn't a significant leap compared to Google's own excellent c3d. The Google Axion-powered c4a ARM instances were released next, showing excellent multi-threaded performance and value. Last week, during Google Next, the 5th Gen AMD EPYC (Zen 5) c4d instances were announced. You can follow the announcement link to apply for a preview, or wait a bit longer until general availability. I've been testing them in preview for SpareRoom and they seem to be one of the most impressive releases in recent memory. Table of contents: The Comparison Performance per 2x vCPU DKbench Suite FFmpeg Video Compression Linux Kernel Compilation OpenSSL (AVX 512) Performance of Full Size Instances DKbench 7zip Compression Compilation OpenSSL Conclusion Addendum: Test methodology Benchmark::DKbench OpenBenchmarking.org (phoronix test suite) FFmpeg compression test The Comparison The new c4d comes in 3 variants, standard with 3.5GB RAM/vCPU, highcpu with 1.5GB/vCPU and highmem with 7.5GB/vCPU. vCPUs are SMT threads (2 threads per physical core), and you can specify from 2 vCPUs to a massive 384, which is 2 processors of 96 SMT cores (192 threads) each. As usual, it's a custom Zen 5 chip (EPYC 9B45) with a core clock of 4.1GHz. I've set up a comparison picking the most relevant GCP VM types: Type CPU vCPUs RAM / vCPU c4d AMD EPYC Turin 2-384 1.5-7.5GB c3d AMD EPYC Genoa 4-360 2-8GB t2d AMD EPYC Milan 1-60 4GB c4 Intel Emerald Rapids 2-192 2-7.5GB c3 Intel Sapphire Rapids 4-176 2-8GB n2 Intel Ice Lake 2-128 1-8GB c4a Google Axion 1-72 2-8GB Performance per 2x vCPU For an apples-to-apples comparison, I will use 2x vCPU instances. For c3/c3d Google's "visible cores" limiter is necessary, as 4x vCPU is the minimum. For most instances 2x vCPU means 1 core / 2 hyper-threads, except t2d and c4a which have no SMT/HyperThreading. That gives an advantage to those two types for multi-threaded loads, as they have twice the physical cores, but you don't pay more as the per vCPU price is not very different. Note that I swapped the t2d with the n2d for EPYC Milan for this, as the latter can go up to 112 cores (224 threads) vs just 60 for t2d. DKbench Suite The DKbench CPU test suite is used to measure performance of the type of generic compute workloads we run on our servers. The test methodology is available as an addendum at the end of this post. The way to read the chart is that you are looking at green for max performance (single-thread load), and orange for value (multi-thread load on a 2x vCPU instance): If you've seen my multi-cloud comparisons, you'll recognise that this is by far the fastest single core performance on a cloud server. It is over 40% higher than the fastest third gen (c3d). It's also almost 20% faster than the c4, a gap that widens in multi-threaded loads (as usual, Intel's HT is not as efficient). The value of non-HT types is also evident, an Axion c4a core is 40% slower, however you pay per vCPU and you get a full core per each, which gives you more performance if your workload can fully utilize them. The aging t2d Milan is similar - much slower per core, but can still compete in value, which is why we use it for several applications to this day. Moving on to some less generic benchmarks that use both vCPUs: FFmpeg Video Compression In the FFmpeg/lib264 compression test, c4d does at least as good with over 40% gains over c3d. Thanks to better SMT it even manages a 35% speed advantage over c4 in the multi-threaded comparison. Linux Kernel Compilation The Linux Kernel Compilation benchmark is not CPU only, the rest of the system, including the disk, is involved, but still we see close to 20% and 40% gains over c4 and c3d respectively. OpenSSL (AVX 512) The OpenSSL RSA4096 encryption test is AVX-512 heavy. Here is an idea of how c4d performs on such workloads: We see 25% gains over c3d and 17% over c4. Not as impressive as the other benchmarks, but still significant. While I consider the 2x vCPU tests the most telling, as they make it easy for me to extrapolate price & performance of our commonly used 4x-32x vCPU instances, there will be applications where a full-size instance will be used. So let’s see what a whole Turin processor (or two) can do. Performance of Full Size Instances As mentioned above, the c4d maxes out at 192 cores / 384 threads - a modest bump over the previous maximum of 180 cores / 360 threads on the c3d. However, paired with faster cores, I expected standout performance - and the c4d didn’t disappoint. DKbench The full-size c4d delivers over 30% more processing power compared to the already-impressive 360-thread c3d. Even more remarkable, a single 96-core (
Over the past year, Google Cloud has been rolling out its fourth-gen compute VMs. First came the Intel-powered c4, which did much better than past Intel instances in my 2024 Cloud Comparison, but ultimately wasn't a significant leap compared to Google's own excellent c3d. The Google Axion-powered c4a ARM instances were released next, showing excellent multi-threaded performance and value.
Last week, during Google Next, the 5th Gen AMD EPYC (Zen 5) c4d instances were announced. You can follow the announcement link to apply for a preview, or wait a bit longer until general availability.
I've been testing them in preview for SpareRoom and they seem to be one of the most impressive releases in recent memory.
Table of contents:
- The Comparison
-
Performance per 2x vCPU
- DKbench Suite
- FFmpeg Video Compression
- Linux Kernel Compilation
- OpenSSL (AVX 512)
-
Performance of Full Size Instances
- DKbench
- 7zip Compression
- Compilation
- OpenSSL
- Conclusion
-
Addendum: Test methodology
- Benchmark::DKbench
- OpenBenchmarking.org (phoronix test suite)
- FFmpeg compression test
The Comparison
The new c4d comes in 3 variants, standard with 3.5GB RAM/vCPU, highcpu with 1.5GB/vCPU and highmem with 7.5GB/vCPU. vCPUs are SMT threads (2 threads per physical core), and you can specify from 2 vCPUs to a massive 384, which is 2 processors of 96 SMT cores (192 threads) each. As usual, it's a custom Zen 5 chip (EPYC 9B45) with a core clock of 4.1GHz.
I've set up a comparison picking the most relevant GCP VM types:
| Type | CPU | vCPUs | RAM / vCPU |
|---|---|---|---|
| c4d | AMD EPYC Turin | 2-384 | 1.5-7.5GB |
| c3d | AMD EPYC Genoa | 4-360 | 2-8GB |
| t2d | AMD EPYC Milan | 1-60 | 4GB |
| c4 | Intel Emerald Rapids | 2-192 | 2-7.5GB |
| c3 | Intel Sapphire Rapids | 4-176 | 2-8GB |
| n2 | Intel Ice Lake | 2-128 | 1-8GB |
| c4a | Google Axion | 1-72 | 2-8GB |
Performance per 2x vCPU
For an apples-to-apples comparison, I will use 2x vCPU instances. For c3/c3d Google's "visible cores" limiter is necessary, as 4x vCPU is the minimum. For most instances 2x vCPU means 1 core / 2 hyper-threads, except t2d and c4a which have no SMT/HyperThreading. That gives an advantage to those two types for multi-threaded loads, as they have twice the physical cores, but you don't pay more as the per vCPU price is not very different.
Note that I swapped the t2d with the n2d for EPYC Milan for this, as the latter can go up to 112 cores (224 threads) vs just 60 for t2d.
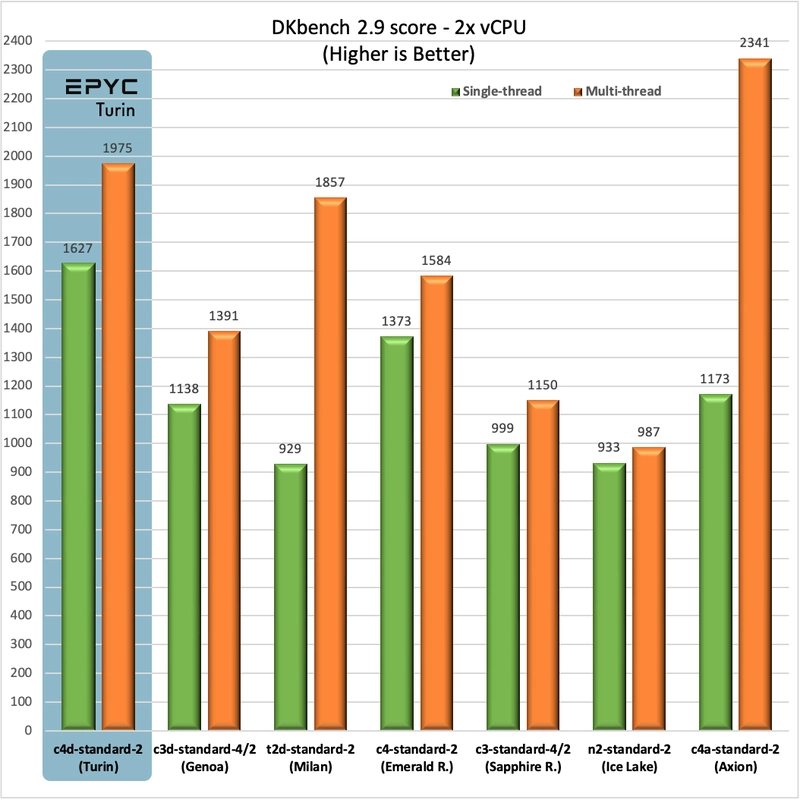
DKbench Suite
The DKbench CPU test suite is used to measure performance of the type of generic compute workloads we run on our servers. The test methodology is available as an addendum at the end of this post. The way to read the chart is that you are looking at green for max performance (single-thread load), and orange for value (multi-thread load on a 2x vCPU instance):
If you've seen my multi-cloud comparisons, you'll recognise that this is by far the fastest single core performance on a cloud server. It is over 40% higher than the fastest third gen (c3d). It's also almost 20% faster than the c4, a gap that widens in multi-threaded loads (as usual, Intel's HT is not as efficient).
The value of non-HT types is also evident, an Axion c4a core is 40% slower, however you pay per vCPU and you get a full core per each, which gives you more performance if your workload can fully utilize them. The aging t2d Milan is similar - much slower per core, but can still compete in value, which is why we use it for several applications to this day.
Moving on to some less generic benchmarks that use both vCPUs:
FFmpeg Video Compression
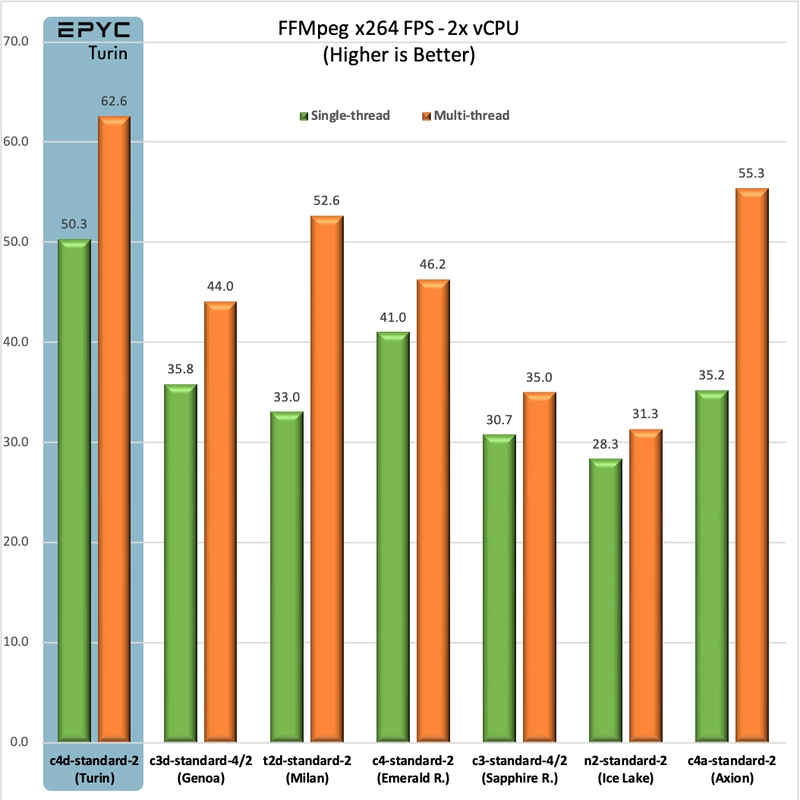
In the FFmpeg/lib264 compression test, c4d does at least as good with over 40% gains over c3d. Thanks to better SMT it even manages a 35% speed advantage over c4 in the multi-threaded comparison.
Linux Kernel Compilation
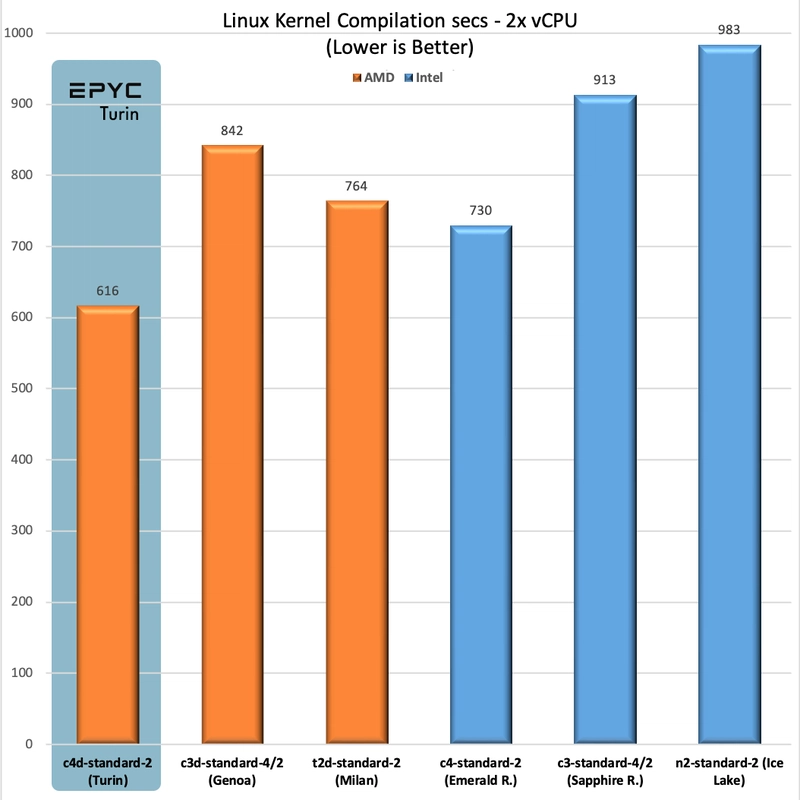
The Linux Kernel Compilation benchmark is not CPU only, the rest of the system, including the disk, is involved, but still we see close to 20% and 40% gains over c4 and c3d respectively.
OpenSSL (AVX 512)
The OpenSSL RSA4096 encryption test is AVX-512 heavy. Here is an idea of how c4d performs on such workloads:
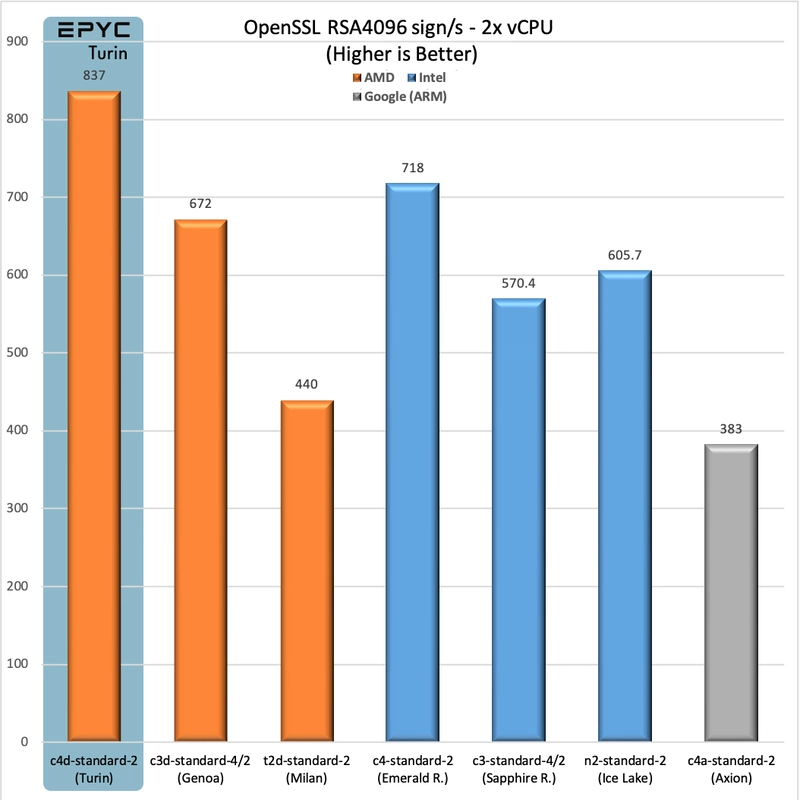
We see 25% gains over c3d and 17% over c4. Not as impressive as the other benchmarks, but still significant.
While I consider the 2x vCPU tests the most telling, as they make it easy for me to extrapolate price & performance of our commonly used 4x-32x vCPU instances, there will be applications where a full-size instance will be used. So let’s see what a whole Turin processor (or two) can do.
Performance of Full Size Instances
As mentioned above, the c4d maxes out at 192 cores / 384 threads - a modest bump over the previous maximum of 180 cores / 360 threads on the c3d. However, paired with faster cores, I expected standout performance - and the c4d didn’t disappoint.
DKbench
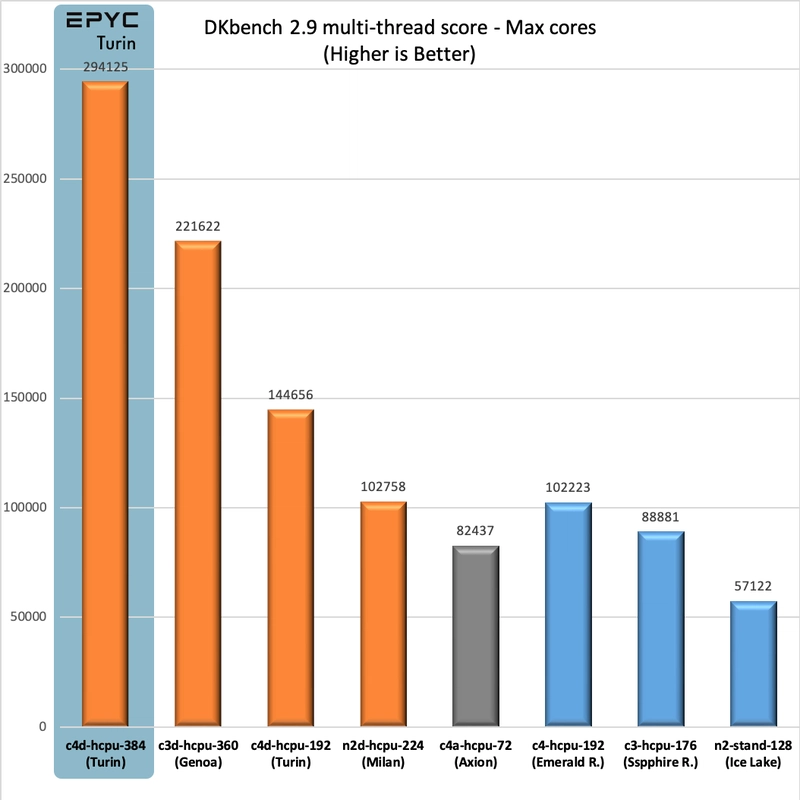
The full-size c4d delivers over 30% more processing power compared to the already-impressive 360-thread c3d. Even more remarkable, a single 96-core (192-thread) EPYC Turin processor in c4d outperforms the Intel-powered c4's full 192-thread configuration by over 40%.
7zip Compression
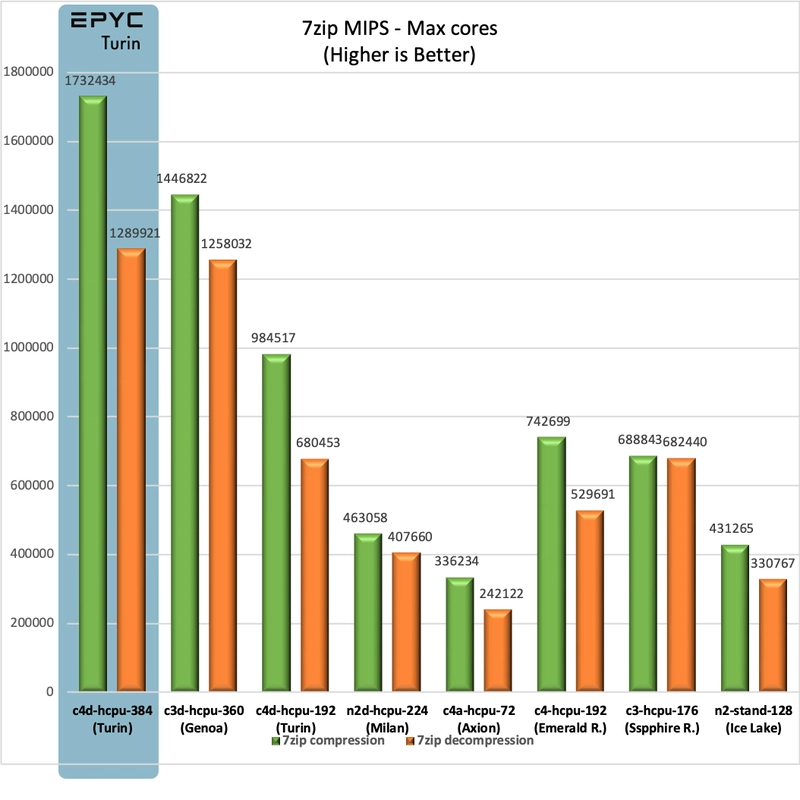
At a compression speed of 1,732,434 MIPS it breaks the current openbenchmarking.org record of 1,658,291 which is held by a 2x EPYC 6845 system (320 cores / 640 threads!).
Compilation
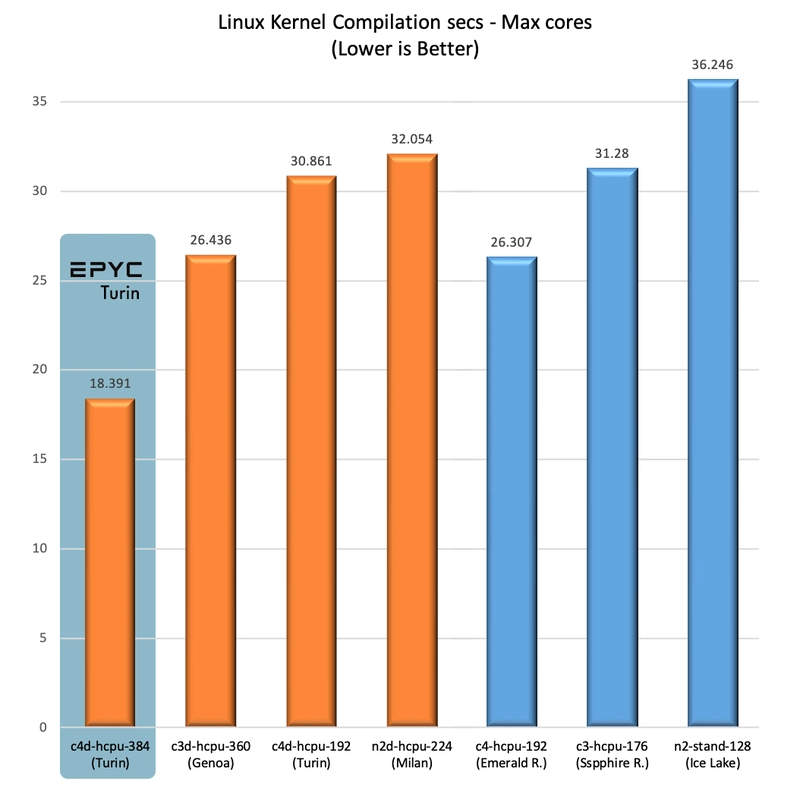
At 18.3s it matches the current best times on openbenchmarking.org which come from other 2-processor AMD Zen 5 systems.
OpenSSL
Let's look again at this AVX 512-capable benchmark:
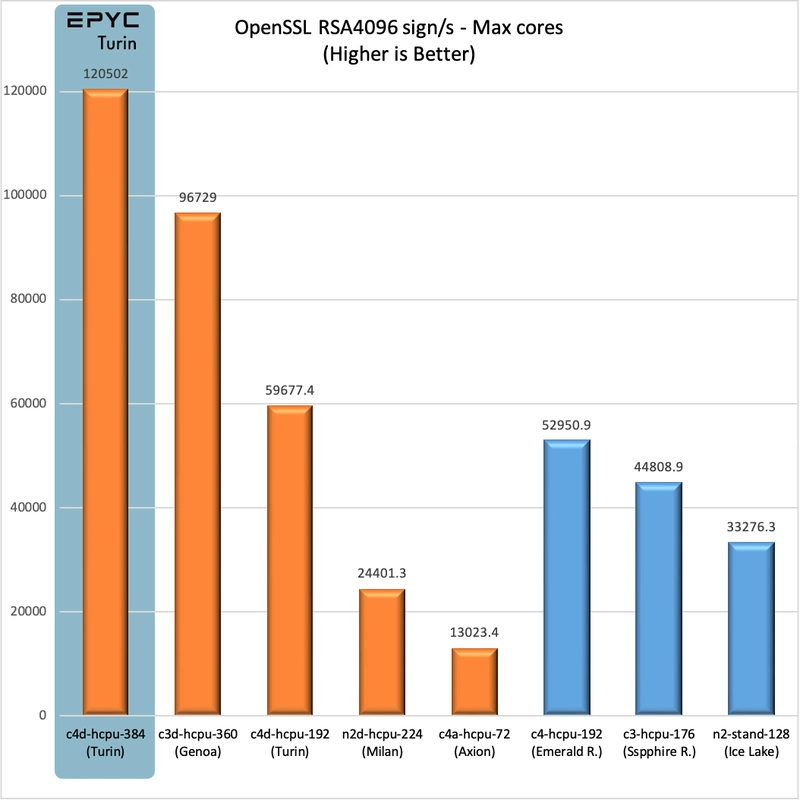
The c4d brings another 25% of performance over the c3d, similar to what we saw on the 2x vCPU test.
Conclusion
The c4d is the kind of new release we are always hoping for, essentially providing a one-click (or single-line code change) ~40% performance boost. Historically, moving to newer CPU generations on Google Cloud typically doesn’t come with increased cost, as maintaining older, less efficient hardware is generally more expensive for providers. Pricing isn’t confirmed yet, but traditionally GCP does not price AMD instances higher than Intel ones, so at significantly better performance than the c4, it should offer great value for most applications. Exceptions may include cases where you maintain a full load across all vCPUs and prioritize price-performance ratio - there, non-SMT instances like the Axion c4a (or even the older EPYC Milan t2d), could have the edge.
Addendum: Test methodology
You can find the full benchmark results listed here.
All instances were set up with a 10GB "Hyperdisk" or "SSD persistent disk" using Google's Debian 12 bookworm image in us-east-4.
Some system packages were installed to support the DKbench and phoronix test suites:
sudo su
apt-get update
apt install -y wget build-essential cpanminus libxml-simple-perl php-cli php-xml php-zip
Benchmark::DKbench
The DKbench suite recorded 5 iterations over 19 benchmarks. If you have followed my previous cloud performance comparisons, it is a suite based in perl and C/XS, which is meant to evaluate the performance of generic CPU workloads that the typical SpareRoom job or web server will run. It is very scalable, which is good for evaluating massive VMs.
To setup the benchmark with a standardized environment you would do:
cpanm -n BioPerl Benchmark::DKbench
setup_dkbench -f
To run (5 iterations):
dkbench -i 5
OpenBenchmarking.org (phoronix test suite)
To setup the phoronix test suite:
wget https://phoronix-test-suite.com/releases/phoronix-test-suite-10.8.4.tar.gz
tar xvfz phoronix-test-suite-10.8.4.tar.gz
cd phoronix-test-suite
./install-sh
To run the benchmarks I used:
phoronix-test-suite benchmark compress-7zip
phoronix-test-suite benchmark build-linux-kernel
phoronix-test-suite benchmark openssl
FFmpeg compression test
# For ARM instances - replace 'arm64' with 'amd64' for x86:
wget https://johnvansickle.com/ffmpeg/releases/ffmpeg-release-arm64-static.tar.xz
tar -xJf ffmpeg-release-arm64-static.tar.xz --wildcards --no-anchored 'ffmpeg' -O > /usr/bin/ffmpeg
chmod +x /usr/bin/ffmpeg
wget https://download.blender.org/peach/bigbuckbunny_movies/big_buck_bunny_720p_h264.mov
time ffmpeg -i big_buck_bunny_720p_h264.mov -c:v libx264 -threads 1 out264a.mp4
time ffmpeg -i big_buck_bunny_720p_h264.mov -c:v libx264 -threads 2 out264b.mp4