



























![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)
















































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)








































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)








































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


































































































![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)





























































































































Beyond Alt-Text: Building a Personalized AI Narrator for Accessibility
What if the way visually impaired users experienced images online wasn't just about basic identification, but about genuine understanding tailored to their world? Imagine, instead of simply hearing 'painting of a woman', an art student could get insights into the brushstrokes and historical context relevant to their studies. Or picture a botanist learning the specific species of a flower in a photo, not just 'flower'. Currently, standard image descriptions and alt-text, while essential, often provide only these basic labels. This limits deeper engagement and can create unequal access to the rich information embedded in visual content, especially for individuals with specialized knowledge or passions. Why should their experience be less informative just because the default description is generic? In this project, I explore that 'What if?'. I introduce the novel 'Personalized AI Narrator': a prototype I built using Google Cloud's powerful Vertex AI Gemini models. My goal is to move beyond generic alt-text by automatically generating image descriptions dynamically tailored to an individual's unique interests, aiming for a future where everyone has the opportunity to connect with visual information in a way that truly resonates with them. Introducing the 'Personalized AI Narrator' So, how did I bridge this gap? The solution I explored in this project is the 'Personalized AI Narrator' prototype. Instead of just one standard description for everyone, the aim is to generate a narration that specifically highlights what you, as an individual user, might find most relevant or interesting in an image. The process involves several steps, orchestrating different AI capabilities on Vertex AI: Detailed Image Understanding: An advanced multimodal Gemini model (gemini-1.5-pro-002) first analyzes the image to generate a rich, detailed base description. Text & Interest Representation: This base description is broken down into sentence chunks. Both chunks and the user's pre-defined interests are then converted into numerical embeddings using a Vertex AI embedding model (text-embedding-004), capturing their semantic meaning. Semantic Relevance Matching: The system calculates cosine similarity between the user's interest embeddings and the description chunk embeddings to find the parts of the description most relevant to the user. Context Selection: The text of the Top N most relevant chunks is selected. Tailored Synthesis (Controlled Generation): Finally, this selected relevant_context and the user's interests are fed to a Gemini text model (gemini-2.0-flash). Guided by a specific prompt I engineered, the model synthesizes these relevant excerpts into a concise, new narrative tailored to the user, ensuring it remains grounded in the selected information. The result? A narration designed to provide deeper insight and a more engaging, informative experience. Powered by Vertex AI Gemini At the heart of this prototype lies Google Cloud's Vertex AI platform, enabling seamless integration of cutting-edge AI. I leveraged the Gemini models for powerful Image understanding (using gemini-1.5-pro-002) and versatile Controlled generation (using gemini-2.0-flash). Vertex AI's Embeddings API (text-embedding-004) provided the numerical representations for semantic matching, and I also used Gemini again for automated Gen AI evaluation. The Vertex AI SDK for Python made orchestrating these capabilities straightforward in my Kaggle Notebook environment. From Generic to Personal: Seeing the Difference But does it truly make a difference? Let's see it in action with an example image: A vibrant butterfly on a red and yellow flower. [https://images.pexels.com/photos/462118/pexels-photo-462118.jpeg] The Base Description (from Gemini Vision) identified key details like: ...Plain Tiger butterfly (Danaus chrysippus)... perched on a Blanket flower (Gaillardia)... wings are a mix of orange, black, and white... flower... exhibits a gradient of red and yellow petals... background... bokeh effect... green stems and leaves... bright and even lighting... natural scene of pollination... (A detailed starting point, rich with potential context). Personalized for Evelyn (Botanist) (Using Top 5 relevant sentences): Evelyn, the image features Blanket flowers (likely Gaillardia) displaying a fascinating gradient of red and yellow petals, with the red deepening towards the brownish-red center of the blooms. Note how one flower, slightly behind the main subject, shows a more even split of red and yellow hues, while glimpses of green stems and leaves add ecological context to the vibrant blossoms. (Result: Excellent focus on flower specifics, color gradients, and ecological context – details directly present in relevant base description chunks). AI Evaluation Score: An automated AI check rated this Score: 4/5, justifying that it effectively highlighted grounded details like the flower's color variations and ecological conte
What if the way visually impaired users experienced images online wasn't just about basic identification, but about genuine understanding tailored to their world? Imagine, instead of simply hearing 'painting of a woman', an art student could get insights into the brushstrokes and historical context relevant to their studies. Or picture a botanist learning the specific species of a flower in a photo, not just 'flower'.
Currently, standard image descriptions and alt-text, while essential, often provide only these basic labels. This limits deeper engagement and can create unequal access to the rich information embedded in visual content, especially for individuals with specialized knowledge or passions. Why should their experience be less informative just because the default description is generic?
In this project, I explore that 'What if?'. I introduce the novel 'Personalized AI Narrator': a prototype I built using Google Cloud's powerful Vertex AI Gemini models. My goal is to move beyond generic alt-text by automatically generating image descriptions dynamically tailored to an individual's unique interests, aiming for a future where everyone has the opportunity to connect with visual information in a way that truly resonates with them.
Introducing the 'Personalized AI Narrator'
So, how did I bridge this gap? The solution I explored in this project is the 'Personalized AI Narrator' prototype. Instead of just one standard description for everyone, the aim is to generate a narration that specifically highlights what you, as an individual user, might find most relevant or interesting in an image.
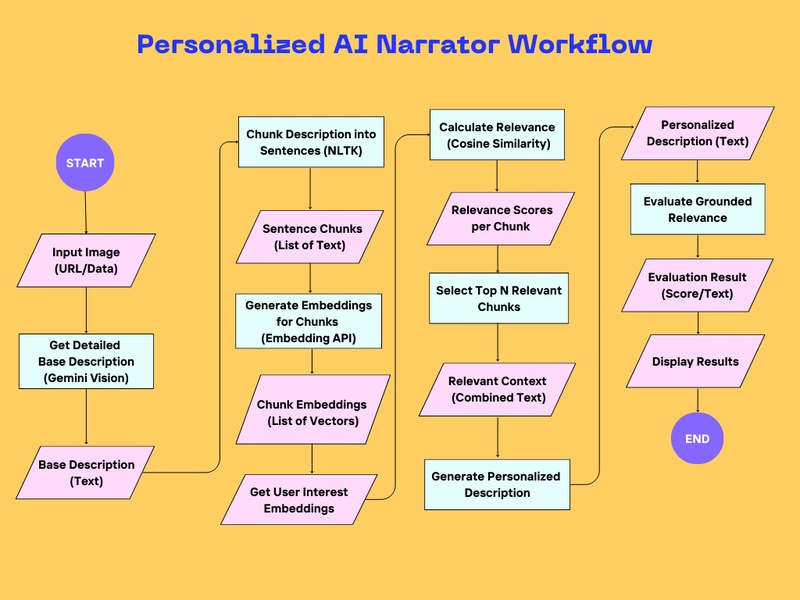
The process involves several steps, orchestrating different AI capabilities on Vertex AI:
Detailed Image Understanding: An advanced multimodal Gemini model (gemini-1.5-pro-002) first analyzes the image to generate a rich, detailed base description.
Text & Interest Representation: This base description is broken down into sentence chunks. Both chunks and the user's pre-defined interests are then converted into numerical embeddings using a Vertex AI embedding model (text-embedding-004), capturing their semantic meaning.
Semantic Relevance Matching: The system calculates cosine similarity between the user's interest embeddings and the description chunk embeddings to find the parts of the description most relevant to the user.
Context Selection: The text of the Top N most relevant chunks is selected.
Tailored Synthesis (Controlled Generation): Finally, this selected relevant_context and the user's interests are fed to a Gemini text model (gemini-2.0-flash). Guided by a specific prompt I engineered, the model synthesizes these relevant excerpts into a concise, new narrative tailored to the user, ensuring it remains grounded in the selected information.
The result? A narration designed to provide deeper insight and a more engaging, informative experience.
Powered by Vertex AI Gemini
At the heart of this prototype lies Google Cloud's Vertex AI platform, enabling seamless integration of cutting-edge AI. I leveraged the Gemini models for powerful Image understanding (using gemini-1.5-pro-002) and versatile Controlled generation (using gemini-2.0-flash). Vertex AI's Embeddings API (text-embedding-004) provided the numerical representations for semantic matching, and I also used Gemini again for automated Gen AI evaluation. The Vertex AI SDK for Python made orchestrating these capabilities straightforward in my Kaggle Notebook environment.
From Generic to Personal: Seeing the Difference
But does it truly make a difference? Let's see it in action with an example image:

A vibrant butterfly on a red and yellow flower.
[https://images.pexels.com/photos/462118/pexels-photo-462118.jpeg]
-
The Base Description (from Gemini Vision) identified key details like:
...Plain Tiger butterfly (Danaus chrysippus)... perched on a Blanket flower (Gaillardia)... wings are a mix of orange, black, and white... flower... exhibits a gradient of red and yellow petals... background... bokeh effect... green stems and leaves... bright and even lighting... natural scene of pollination...(A detailed starting point, rich with potential context).
-
Personalized for Evelyn (Botanist) (Using Top 5 relevant sentences):
Evelyn, the image features Blanket flowers (likely Gaillardia) displaying a fascinating gradient of red and yellow petals, with the red deepening towards the brownish-red center of the blooms. Note how one flower, slightly behind the main subject, shows a more even split of red and yellow hues, while glimpses of green stems and leaves add ecological context to the vibrant blossoms.(Result: Excellent focus on flower specifics, color gradients, and ecological context – details directly present in relevant base description chunks).
AI Evaluation Score: An automated AI check rated this Score: 4/5, justifying that it effectively highlighted grounded details like the flower's color variations and ecological context relevant to botany. -
Personalized for Anya (Art Student) (Using Top 5 relevant sentences):
Anya, imagine a vibrant close-up photograph reminiscent of Renaissance portraiture, where a butterfly takes center stage against a softly blurred background of flowers. The bright, even lighting enhances the vivid colors, creating a depth of field that subtly emphasizes the delicate interaction between the butterfly and its floral perch, much like the sfumato technique used to soften edges and focus attention.(Result: Attempts to link visual elements like lighting and depth of field to Renaissance concepts).
AI Evaluation Score: The AI evaluation gave this a lower Score: 2/5. The justification highlighted that the connections to Renaissance art were superficial and weakly supported by the base description's mention of 'blurred background' and 'vivid colors.'
Code Snippet - The Prompt's Core: How did I guide the AI for personalization? Through prompt engineering based on the selected context:
personalization_prompt = f"""Act as [Role: Expert Narrator]...
User Profile: Name: {persona_name}, Interests: {interests_string}
Relevant Context:
---
{relevant_context} #<-- The Top 5 selected sentences
---
Task: Synthesize context concisely focusing on interests, grounded ONLY in context provided..."""
(This snippet demonstrates the core instruction guiding the controlled generation based on selected context).
This comparison using the actual results clearly shows the potential for tailoring with the semantic approach (getting a good score for Evelyn where relevant details existed) but also honestly demonstrates the current limitations related to grounding when source details are sparse (reflected in Anya's score), a finding objectively confirmed by the AI evaluation step.
Notebook Output:
1. Evelyn:



2. Anya :



The Potential: Towards Richer Digital Accessibility
The need for better digital accessibility is immense. The World Health Organization (WHO) estimates that for at least 1 billion people globally, existing vision impairment could have been prevented or has yet to be addressed. This staggering figure underscores the urgency for innovative solutions. Tools like the Personalized AI Narrator demonstrate how AI can contribute, aiming to create more inclusive and equitable digital experiences. By generating descriptions that resonate with individual interests, I believe this approach can help users move beyond basic labeling towards deeper understanding and engagement with visual content.
As my results showed, a key limitation of the current grounded approach (even with semantic chunk selection) is its dependency on the initial image analysis. To overcome this and provide truly rich context, future work should focus on integrating external knowledge sources (using RAG - Retrieval Augmented Generation). Developing seamless integration with screen readers is another vital next step for real-world usability.
Conclusion: A Step Towards More Personal AI Narration
The Personalized AI Narrator prototype I built showcases a novel application of Vertex AI Gemini for enhancing accessibility. By tailoring image descriptions to individual interests, it offers a glimpse into a future where visual content is not just described, but truly brought to life for everyone, respecting individual perspectives. While challenges remain, particularly around balancing relevance with groundedness when source details are sparse, the potential for using AI to foster greater digital inclusion is immense.
Thanks for reading, and have a great day!
Explore the full implementation I developed and try it yourself in the Kaggle Notebook here:[https://www.kaggle.com/code/yogesmohan/personalized-ai-narrator-for-visual-accessibility]


{kind=link}