













































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)






























































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.png?#)


































_Christophe_Coat_Alamy.jpg?#)


.webp?#)






































































































![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)
![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)





























































































































AI Learns Like Humans: Easier Tasks First Leads to Better Math and Logic Performance
This is a Plain English Papers summary of a research paper called AI Learns Like Humans: Easier Tasks First Leads to Better Math and Logic Performance. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Overview Research examines staged reinforcement learning approach for enhancing reasoning in LLMs Uses difficulty-aware training method that progresses from simple to complex problems Introduces DA-SRL (Difficulty-Aware Staged Reinforcement Learning) to improve reasoning Shows significant performance gains across multiple reasoning benchmarks Leverages both supervised fine-tuning and reinforcement learning techniques Most effective when starting with easier examples before tackling harder ones Plain English Explanation Imagine teaching a child math. You wouldn't start with calculus—you'd begin with addition, then multiplication, and gradually move to more complex concepts. This paper applies this same principle to training AI models. The researchers developed a method called [Difficulty-Awar... Click here to read the full summary of this paper
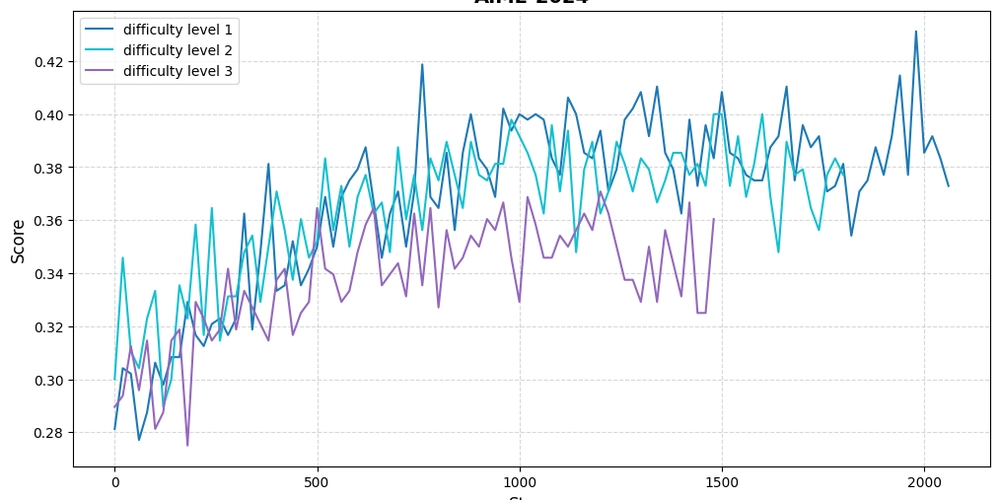
This is a Plain English Papers summary of a research paper called AI Learns Like Humans: Easier Tasks First Leads to Better Math and Logic Performance. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- Research examines staged reinforcement learning approach for enhancing reasoning in LLMs
- Uses difficulty-aware training method that progresses from simple to complex problems
- Introduces DA-SRL (Difficulty-Aware Staged Reinforcement Learning) to improve reasoning
- Shows significant performance gains across multiple reasoning benchmarks
- Leverages both supervised fine-tuning and reinforcement learning techniques
- Most effective when starting with easier examples before tackling harder ones
Plain English Explanation
Imagine teaching a child math. You wouldn't start with calculus—you'd begin with addition, then multiplication, and gradually move to more complex concepts. This paper applies this same principle to training AI models.
The researchers developed a method called [Difficulty-Awar...



