



























![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)













































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)








































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)








































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


























































































![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)





























































































































A Minimal Static Blog Generator in Purescript - My Notes and Code Walkthrough
Intended audience: basic functional programming know-how, Haskell/Purescript newbies/enthusiasts. About two years ago, I decided to move my Tumblr blog to some sort of a custom-made static blog generating tool written in Purescript (a Haskell-inspired language that compiles to JS). I've wanted to chronicle the work on this codebase at various times but never got around to doing it. Somehow, I convinced myself that the write-up would be boring to readers and not of much any value. Nevertheless, I decided that I'll at least jot down some notes from the codebase and maybe someone finds it interesting enough. GitHub source of the project Why another static blog/site generator? And why Purescript? Coming out of Tumblr, I vaguely remember looking at some static site options. Many of them were feature behemoths (Next.js). Smaller, fancy ones like 11ty caught my eye but it still felt ceremonious to get started with them. On the other hand, I was itching to do something in Purescript (I've learnt stuff better by building things). So it was just a matter of wanting to learn a language and also to end up creating a nice little, ultra-minimal static blog generating setup for myself. Too often, people end up in the "do not reinvent the wheel" mentality. This is great mantra for a business/startup. But if you want to learn things, you have to constantly reinvent stuff. What's in a static blog generator? At the very core of static site/blog generators, it is all about generating HTML pages. You run a script and it collects all the data it needs and then writes HTML pages to your disk. You then host these HTML pages as your site/blog. When I started this project, this was my basic, high-level mental model: I will write posts in markdown files that are saved inside a contents folder When I run the script, it will read the contents of each markdown file, convert that into HTML, then use a "template" where it will replace the body with the HTML and save the final result as an HTML file. I will also generate, through the script, an index.html that will render all posts in reverse chronological order. You know, like a blog. The build steps are basically: get a list of markdown files from a folder (these are the blog posts to generate HTML files for) for each file: read the contents, convert markdown into HTML, replace the body from a template string with this HTML, write the final thing to an HTML file. finally, generate an index HTML file (from a template), replacing the body with a list of all posts, linking each post to its HTML file. Eventually, I ended up adding more bits like an RSS feed, an archive page, a more customized index page etc. Building from the smallest unit of work You can either solve things top-down (write the main function first, then fill out the constituent functions) or bottom-up (write functions for the smallest unit of work and then compose upwards). In this one, I went bottom-up for the most part. The smallest unit of work was something like this: read a markdown file convert the contents into HTML replace a template string with that HTML write the updated template string to a file with the same slug/name as the markdown file. The trickiest part was converting markdown to HTML. There is a library in Purescript that does this but I can't remember why I did not use it and instead, used something called an FFI to tap into JS code. I have a JS module that exports a helper function (which takes a markdown string, and converts that into an HTML string, and returns an object of that data). // Utils.js const md2FormattedDataService = new MarkdownIt({ html: true }); const md2RawFormattedData = (string) => { const r = matter(string); return { frontMatter: { ...r.data, date: formatDate("YYYY-MM-DD")(r.data.date), tags: r.data.tags?.split(",") ?? [], status: r.data.status || "published" }, content: md2FormattedDataService.render(r.content), raw: string }; }; This is then imported into my Purescript module (the filename is same as that of the JS file. Utils) as a foreign-function. -- Utils.purs foreign import md2RawFormattedData :: String -> RawFormattedMarkdownData type RawFormattedMarkdownData = { frontMatter :: { title :: String , date :: String , slug :: String , tags :: Array String , status :: String } , content :: String , raw :: String } Now, I can compose a function that does the unit of work: writeHTMLFile :: Template -> FormattedMarkdownData -> Aff Unit writeHTMLFile template pd@{ frontMatter } = do config FormattedMarkdownData -> String replaceContentInTemplate (Template template) pd = replaceAll (Pattern "{{title}}") (Replacement $ "" pd.frontMatter.title "") template # replaceAll (Pattern "{{content}}") (Replacement pd.content) # replaceAll (Pattern "{{date}}") (Replacement $ formatDate "MMM DD, YYYY" pd.frontMatter.date) # replaceAll (Patte
Intended audience: basic functional programming know-how, Haskell/Purescript newbies/enthusiasts.
About two years ago, I decided to move my Tumblr blog to some sort of a custom-made static blog generating tool written in Purescript (a Haskell-inspired language that compiles to JS).
I've wanted to chronicle the work on this codebase at various times but never got around to doing it. Somehow, I convinced myself that the write-up would be boring to readers and not of much any value.
Nevertheless, I decided that I'll at least jot down some notes from the codebase and maybe someone finds it interesting enough.
Why another static blog/site generator? And why Purescript?
Coming out of Tumblr, I vaguely remember looking at some static site options. Many of them were feature behemoths (Next.js). Smaller, fancy ones like 11ty caught my eye but it still felt ceremonious to get started with them.
On the other hand, I was itching to do something in Purescript (I've learnt stuff better by building things).
So it was just a matter of wanting to learn a language and also to end up creating a nice little, ultra-minimal static blog generating setup for myself.
Too often, people end up in the "do not reinvent the wheel" mentality. This is great mantra for a business/startup. But if you want to learn things, you have to constantly reinvent stuff.
What's in a static blog generator?
At the very core of static site/blog generators, it is all about generating HTML pages. You run a script and it collects all the data it needs and then writes HTML pages to your disk. You then host these HTML pages as your site/blog.
When I started this project, this was my basic, high-level mental model:
- I will write posts in markdown files that are saved inside a
contentsfolder - When I run the script, it will read the contents of each markdown file, convert that into HTML, then use a "template" where it will replace the body with the HTML and save the final result as an HTML file.
- I will also generate, through the script, an
index.htmlthat will render all posts in reverse chronological order. You know, like a blog.
The build steps are basically:
- get a list of markdown files from a folder (these are the blog posts to generate HTML files for)
- for each file: read the contents, convert markdown into HTML, replace the body from a template string with this HTML, write the final thing to an HTML file.
- finally, generate an index HTML file (from a template), replacing the body with a list of all posts, linking each post to its HTML file.
Eventually, I ended up adding more bits like an RSS feed, an archive page, a more customized index page etc.
Building from the smallest unit of work
You can either solve things top-down (write the main function first, then fill out the constituent functions) or bottom-up (write functions for the smallest unit of work and then compose upwards).
In this one, I went bottom-up for the most part.
The smallest unit of work was something like this:
- read a markdown file
- convert the contents into HTML
- replace a template string with that HTML
- write the updated template string to a file with the same slug/name as the markdown file.
The trickiest part was converting markdown to HTML. There is a library in Purescript that does this but I can't remember why I did not use it and instead, used something called an FFI to tap into JS code.
I have a JS module that exports a helper function (which takes a markdown string, and converts that into an HTML string, and returns an object of that data).
// Utils.js
const md2FormattedDataService = new MarkdownIt({ html: true });
const md2RawFormattedData = (string) => {
const r = matter(string);
return {
frontMatter: {
...r.data,
date: formatDate("YYYY-MM-DD")(r.data.date),
tags: r.data.tags?.split(",") ?? [],
status: r.data.status || "published"
},
content: md2FormattedDataService.render(r.content),
raw: string
};
};
This is then imported into my Purescript module (the filename is same as that of the JS file. Utils) as a foreign-function.
-- Utils.purs
foreign import md2RawFormattedData :: String -> RawFormattedMarkdownData
type RawFormattedMarkdownData =
{ frontMatter ::
{ title :: String
, date :: String
, slug :: String
, tags :: Array String
, status :: String
}
, content :: String
, raw :: String
}
Now, I can compose a function that does the unit of work:
writeHTMLFile :: Template -> FormattedMarkdownData -> Aff Unit
writeHTMLFile template pd@{ frontMatter } = do
config <- askConfig
res <- try $ writeTextFile UTF8 (tmpFolder <> "/" <> frontMatter.slug <> ".html") (replaceContentInTemplate template pd)
_ <- case res of
Left err -> log $ Logs.logError $ "Could not write " <> frontMatter.slug <> ".md to html (" <> show err <> ")"
Right _ -> log $ Logs.logSuccess $ "Wrote: " <> config.contentFolder <> "/" <> frontMatter.slug <> ".md -> " <> tmpFolder <> "/" <> frontMatter.slug <> ".html"
pure unit
replaceContentInTemplate :: Template -> FormattedMarkdownData -> String
replaceContentInTemplate (Template template) pd =
replaceAll (Pattern "{{title}}") (Replacement $ "\"./" <> pd.frontMatter.slug <> "\">" <> pd.frontMatter.title <> "") template
# replaceAll (Pattern "{{content}}") (Replacement pd.content)
# replaceAll (Pattern "{{date}}") (Replacement $ formatDate "MMM DD, YYYY" pd.frontMatter.date)
# replaceAll (Pattern "{{page_title}}") (Replacement pd.frontMatter.title)
The replaceContentInTemplate function is a pure, side-effect-less function which replaces marked slots (like {{content}}) in a string template with the right data, producing a final HTML string.
In the writeHTMLFile function, I just try and write the file with the contents thus produced.
What's worth noting is that the function is designed never to fail. It always returns unit (via pure unit) because if things go wrong, they should not crash the building. (That is to say, if one post does not get converted into an HTML file for whatever reason, it should not prevent others from getting converted).
To do this, I use a try which takes a function that could throw, and converts it into an Either value — that is, if the function throws, you will get a Left value. If not, a Right value.
A part that's missing in the code snippet is the md2rawFormattedData function:
readFileToData :: String -> Aff FormattedMarkdownData
readFileToData filePath = do
contents <- readTextFile UTF8 filePath
let
fd = md2FormattedData contents
fdraw = md2RawFormattedData contents
if fd.frontMatter.status == InvalidStatus then
throwError $ error $ "Invalid status in " <> filePath <> "." <> "Found -> status: " <> fdraw.frontMatter.status
else
pure fd
As it turns out, the script (at the time of writing this) reads all markdown files and converts them in a different step and then passes that list of converted data through the script.
Parallel processing in Purescript
There are a bunch of options in Purescript to do parallel computation. I faced this need quite early.
The whole deal is about processing a bunch of files. That is, running them through the same functions.
So once I had a set of functions that could process one file, I could simply traverse through them. Traverse is functional-programming-speak for looping through data (typically, list-like/array) and performing some action every time on the data while also accumulating the results. Think of JS's map but imagine each item is not just transformed but you do some side-effectful action as well.
For example:
filePathsToProcessedData :: Config -> Array String -> Aff (Array FormattedMarkdownData)
filePathsToProcessedData config fpaths = parTraverse (\f -> readFileToData $ config.contentFolder <> "/" <> f) fpaths
Here, I am trying to work through an array of file paths (Array String). Each file path is passed to the readFileToData (which converts a markdown file to its HTML equivalent, see above). And I can do this in parallel trivially by using the parTraverse function.
In parTraverse the result of each computation is retained and returned in the same data structure that was passed. So, passing an array would result in returning an array of values corresponding to each application/computation of readFileToData. That's why you see this:
readFileToData :: String -> Aff FormattedMarkdownData
filePathsToProcessedData :: Config -> Array String -> Aff (Array FormattedMarkdownData)
That is, the filePathsToProcessedData function, which uses parTraverse returns an array (inside an Aff context, which denotes some side-effectful action) of FormattedMarkdownData.
There is also a variant of parTraverse where you don't care about the results. It's called parTraverse_. I use that when generating HTML files from the set of converted posts:
generatePostsHTML :: Array FormattedMarkdownData -> Aff Unit
generatePostsHTML fds = do
template <- readPostTemplate
_ <- parTraverse_ (\f -> writeHTMLFile (Template template) f) fds
pure unit
Side-effects, Aff monad, errors and the ExceptT transformer
Side effects in languages like Haskell and Purescript are usually of the type IO or Eff/Aff (Aff is asynchronous, whereas Eff is synchronous).
It took me a while to get used to these. To be clear, it's easy to write a function that uses one of these. What is harder is to then "compose" them in other functions and also to handle errors correctly. With a better understanding of the monadic composition and experience with some transformers (i.e one level higher abstraction over monads), things became a little easier.
The blog generator is peppered with Aff everywhere because there's reading from files and writing to files going on and all of these are side-effects from a functional programming standpoint.
Affs (and IOs and Effs) can throw errors. Unfortunately, this is not explicit in the type information. You just assume that these computations can fail and throw an error, causing your app/script to crash.
One way to handle this is to wrap the computation in a try function; this will change a result from Aff a (where a is any type, called polymorphic type) to Aff (Either e a) (where e = any error type). By converting it to Either, you capture the error as a value.
The downside to this is that composition becomes difficult.
That is, before using try:
doAction1 :: Aff a
doAction2 :: a -> Aff b
-- can be composed easily:
doCombined = do
a <- doAction1
doAction2 a
But with try, in an attempt to catch errors:
doAction1 :: Aff (Either e a)
doAction2 :: a -> Aff (Either e b)
doCombined = do
res <- doAction1
case res of
Left e -> pure (Left e)
Right a -> doAction2 a
That is, I have to pattern match and extract. This gets harder and complex when more functions are involved in the computation/combination.
To circumvent this issue, we can use something called monad transformers. Specifically for our case, ExceptT. (all monad transformers are idiomatically typed with an ending capital T — ExceptT, EitherT, ReaderT, etc.)
I can now rewrite this as:
doAction1 :: ExceptT e Aff a
doAction2 :: a -> ExceptT e Aff b
doCombined :: ExceptT e Aff b
doCombined = do
a <- doAction1
doAction2 a
-- and then to actually run the computation:
doCombinedRun :: Aff (Either e b)
doCombinedRun = runExceptT doCombined
ExceptT allows me to retain the simple, straight-forward coding style without using try and pattern matching the Either value, but it bakes error-handling in for free.
Things of type ExceptT are really actions to be done. That is, they have to be run. To do this, we have runExceptT which is of this type:
runExceptT :: ExceptT e m a -> m (Either e a)
-- or more concretely in my case
runExceptT :: ExceptT e Aff a -> Aff (Either e a)
It takes an ExceptT and "runs" it, and if it threw an error, you get an Aff (Left e) and if it ran the computation successfully, it returns an Aff (Right a).
Armed with this information, and excited that now I can simplify the app, I converted a lot of functions to be ExceptTs. But this posed a new problem: I had to unwrap actions (ie, run them) a few times at different places. That re-introduced the pattern matching code.
Eventually, I figured a way to not do that and instead, just have a top-level ExceptT instead.
So, the app's core functions — eg, building the site (buildSite) — are of the ExceptT type but all the functions that go into composing the buildSite and other core functions are just Affs. They can throw errors, sure, but they'll all be caught in the top-level, core functions.
As an example:
buildSite :: Config -> ExceptT Error Aff Unit
buildSite config = ExceptT $ try $ do
-- a lot of `Aff a` functions go here
And in the main:
launchAff_
$ do
config <- askConfig
res <- runExceptT $ buildSite config
case res of
Left err -> log $ Logs.logError $ "Error when building the site: " <> show err
Right _ -> log $ Logs.logSuccess "Site built and available in the " <> config.outputFolder <> " folder."
Where a function throwing an error should not be bubbled up, I do an in-place try and catch the errors early:
writeHTMLFile :: Template -> FormattedMarkdownData -> Aff Unit
writeHTMLFile template pd@{ frontMatter } = do
config <- askConfig
res <- try $ writeTextFile UTF8 (tmpFolder <> "/" <> frontMatter.slug <> ".html") (replaceContentInTemplate template pd)
_ <- case res of
Left err -> log $ Logs.logError $ "Could not write " <> frontMatter.slug <> ".md to html (" <> show err <> ")"
Right _ -> log $ Logs.logSuccess $ "Wrote: " <> config.contentFolder <> "/" <> frontMatter.slug <> ".md -> " <> tmpFolder <> "/" <> frontMatter.slug <> ".html"
pure unit
Passing global config around
In recent times, I've been trying to make my blog generator as much configurable as possible. The templates folder, the contents folder etc. that had been historically hard-coded are now customizable through environment variables (shell env).
This meant that all the functions that used these hard-coded values would now need to depend on a global config. So, I'd either have to pass the config as another function parameter/argument, or make these functions read from the global config somehow.
There are two approaches possible:
- initialize the global config at the start of the app (typically, the
mainfunction) and then pass the config object down the wire to all functions. This would lead to what React devs call prop-drilling. - or, use the
ReaderTmonad transformer pattern where functions can "ask" for the config object and then use it, but the moment functions do this, they become side-effectful functions (if they already weren't).
I decided that for my script, I did not have to go all the way to a ReaderT, and I could just get away with a simple askConfig function like this:
askConfig :: Aff Config
askConfig = liftEffect $ do
templateFolder <- lookupEnv "TEMPLATE_DIR" >>= (pure <$> fromMaybe defaultTemplateFolder)
outputFolder <- lookupEnv "OUTPUT_DIR" >>= (pure <$> fromMaybe defaultOutputFolder)
contentFolder <- lookupEnv "POSTS_DIR" >>= (pure <$> fromMaybe defaultContentFolder)
totalRecentPosts <- lookupEnv "RECENT_POSTS" >>= (pure <$> fn)
pure $ { templateFolder: templateFolder, outputFolder: outputFolder, contentFolder: contentFolder, newPostTemplate: defaultBlogpostTemplate templateFolder, totalRecentPosts: totalRecentPosts }
where
fn :: Maybe String -> Int
fn x = fromMaybe defaultTotalRecentPosts $ (x >>= fromString)
For functions that already are Aff a, I can get the config without disturbing the function's type. For those that are "pure", I just pass the config as the first argument.
This refactor was simple but I also remember feeling happy for the guarantees of the Purescript compiler in making sure I was refactoring things without breaking them in the process.
Adding a simple cache mechanism to optimize build times
A full (cache-less) build of the site with ~140 posts takes ~3 seconds so there is really no need for a caching mechanism but it's one of those niceties to have, so I added that in.
Figuring out a simple cache logic was interesting. The goal was to know what files got modified and what didn't and using system commands (stat) made it quite easy.
Each file can then be mapped to its modification datetime and stored as some kind of key-value thing in a file:
a-breeze-of-wisdom::Feb 28 14:18:11 2025 Feb 28 14:18:11 2025
a-naive-thought::Mar 1 11:54:00 2025 Mar 1 11:54:00 2025
a-vengeful-society-vs-a-corrective-society::Feb 28 14:18:11 2025 Feb 28 14:18:11 2025
aaji::Feb 28 14:18:11 2025 Feb 28 14:18:11 2025
At the time of building the site, I just read from this file, check the last modified datetime value of the file and compare it with current, and decide if the file needs a re-build.
The getStat function helps get the stat data which is then used for the cache generation. A parTraverse helps compose getStat over a list/array of files:
getStat :: FilePath -> String -> Aff ({ slug :: String, stat :: String })
getStat contentsFolder slug = do
buf <- try $ liftEffect $ execSync ("stat -f \"%Sm %Sc\" -n " <> contentsFolder <> "/" <> slug <> ".md") defaultExecSyncOptions
case buf of
Left _ -> pure $ { slug, stat: "" }
Right buffer -> do
b <- try $ liftEffect $ toString UTF8 buffer
case b of
Right s -> pure { slug, stat: s }
Left _ -> pure { slug, stat: "" }
getStatAll :: Array String -> Aff (Array { slug :: String, stat :: String })
getStatAll slugs = do
config <- askConfig
parTraverse (getStat config.contentFolder) slugs
More commands!
For a long time, invoking the blog generator script would immediately start building the blog. But CLI tools usually have dedicated commands that print help, version etc.
So I modified the code to do some of those things.
Going for an arg-parsing library for this (in Haskell, something like optparse-applicative, in Purescript, something like the yargs library?) seemed overkill so I went with a simple pattern match that took the args, and then converted it into a Command type:
data Command
= Build
| ShowVersion
| Help
| NewPost String
| Invalid
mkCommand :: Array String -> Command
mkCommand xs = case head (drop 2 xs) of
Just "version" -> ShowVersion
Just "help" -> Help
Just "build" -> Build
Just "new" -> case head $ drop 3 xs of
Just slug -> NewPost slug
_ -> Invalid
_ -> Invalid
main = do
args <- argv
cmd <- pure $ mkCommand args
case cmd of
Help -> log $ helpText
-- ...rest of the code
The "NewPost" was a recent addition: it allowed me to create a new blogpost using a template so that I didn't have to type out all the metadata.
The complexities of using TailwindCSS
The project uses/supports use of Tailwind CSS classes and directives so I could pepper my templates and stylesheets and even markdown with Tailwind's CSS classes.
The tricky bit comes where I have to use Tailwind generate the final, compiled CSS file.
I generate the site in a dedicated temporary folder — so all rendered HTML files are put there, along with copied JS/CSS/image files in respective folders. Then, I run Tailwind to compile the final CSS output. And once all that is done, I just copy over everything into a public folder which can then be used to host/serve.
Here, I have two options: use Tailwind CLI to compile it, or use Tailwind via NPM to do the same.
Using Tailwind via NPM means installing tailwindcss and then invoking npx @tailwind/cli. This creates a node_modules folder, a package.json and a package-lock.json which I have to then cleanup. An older version of the generator did precisely all this.
In the new version, the script assumes that you have the Tailwind CLI standalone installed on your machine, and is invokable as a simple tailwindcss command.
Eventually, I'd like to improve logging and customization around this. For example, if you do not rely on Tailwind classes and roll your own, you should be able to set a flag or something to disable my script from running the Tailwind command.
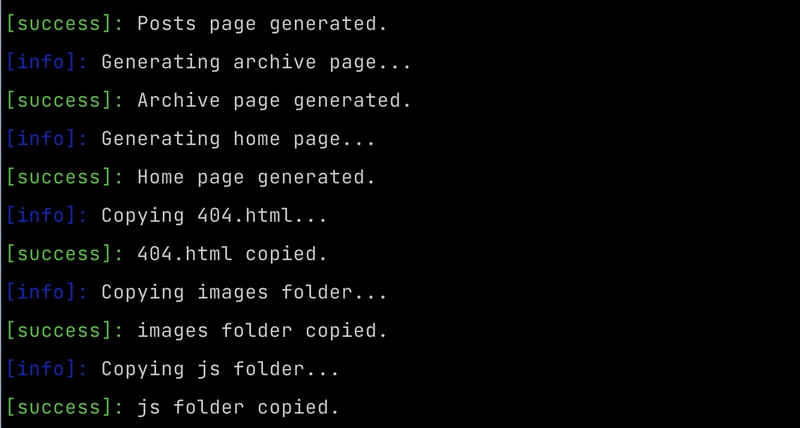
Simple, colorful logging
On another project for testing Steampipe queries, I use a simple pattern for logging with colors for success, error and warning/info. I decided to use that in this project too.
The logging looks like this:
And this is just a bunch of simple functions:
red :: String -> String
red s = "\x1b[31m" <> s <> "\x1b[0m"
green :: String -> String
green s = "\x1b[32m" <> s <> "\x1b[0m"
yellow :: String -> String
yellow s = "\x1b[33m" <> s <> "\x1b[0m"
blue :: String -> String
blue s = "\x1b[34m" <> s <> "\x1b[0m"
logSuccess str = green "[SUCCESS]: " <> str
logInfo str = blue "[INFO]: " <> str
logError str = red "[ERROR]: " <> str
logWarning str = yellow "[WARNING]: " <> str
Where to from here?
This is one of those little things that you're proud of and have fun tinkering around with. There are no goals other than just having fun while I improve the functionality and also keep it simple and useful enough.
Of the many side-projects I've worked on the years, this is one of those that I use regularly. That makes this project somewhat special.


