













































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)






























































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.png?#)

































_Christophe_Coat_Alamy.jpg?#)
 (1).webp?#)






































































































![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)
![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)





























































































































Using modern AI tools to manage an old "growing" problem
Sharing a personal account of how I managed to regain control of a document management problem, with help from a single Python library and Amazon Q Developer CLI. Hoping you find inspiration, along with a few helpful coding tips to address your next challenge. Amazon Q Developer CLI is a command-line tool that acts like a personal assistant right in your terminal. It's always there and ready to answer your programming questions, or help manage tasks. Here's some of what Q Developer CLI can do: Answer questions about programming concepts, AWS services, and a variety of software development best practices Write and debug code for many popular languages Explain errors, and suggest fixes Interact with many services, and tools through the CLI interface The beauty of Q Developer CLI is you don't need to switch between the terminal and a web browser when coding. Just type q chat and start a conversation from your command line. When finished, type /quit to exit. The Problem Recently, I came to the realization that my catalogue of personal PDF files has become a mess. For years, I've been digitizing my life opting out of paper statements like bank records, invoices, and magazines, converting it all into pile-free electronic euphoria. It has prevented my home from becoming a mountain of paper, plus I'm able to carry documents with me anywhere on my mobile devices. Life was good, until it wasn't anymore. I saw it coming for some time, but pretended it wasn't an issue. Today, my iPad and storage on my PC is the digital equivalent of the paper mountain I worked long and hard to avoid. I tried moving PDFs to the cloud, but that basically created another paper mountain...only this time in the cloud where the mountain rises even higher! The Opportunity It was time to figure out what to do next, and I decided to consolidate the chaos. Storage wasn't the issue, management was. How could I maintain my digital well being in a useful way? Thankfully, I found a convenient, Do-It-Yourself solution that combines months (in some cases years!) of e-docs into a single one. It hasn't solved my problem entirely, but it is REAL progress! The Tools Enter Amazon Q Developer CLI and pypdf. Earlier, I described a few of Q Developer CLI's capabilities. You can find additional details along with a link to installation and setup instructions here. pypdf is a free, open source library for creating and managing PDF documents. Among the many features, consolidating multiple files together is what intrigued me the most. I've done file consolidation before using printer utilities, but that approach is clunky, not very intuitive, or efficient. Make sure you have Python 3.9 or higher installed on your system. Instructions for setting up Python for your operating system can be found here. The Fix After pouring over the pypdf documentation I knew my solution was doable, but to make it more intuitive I thought, "...why not go further and build a simple app that lets me drop files into a browser interface to combine them?!" Works for me because it is also efficient, and it would put me back in control. Not wanting to procrastinate given the opportunity, I launched Q Developer CLI and started my project. q chat to the rescue! Step 1: The Basics First, I needed to familiarize myself with pypdf as this was my first dive into using the library. The docs were helpful, and I was able to write a first program in a few minutes. What I created was a routine that was able to read and extract info from any PDF. With the code below, I created the file get_doc_info.py and then conducted a brief test in the virtual environment created with the steps illustrated. This was simple enough that I didn't seek help from Q Developer CLI, but feel free if you need to on your first attempt! # from PyPDF2 import PdfFileReader from PyPDF2 import PdfReader import sys import os def get_info(path): try: with open(path, 'rb') as f: pdf = PdfReader(f) info = pdf.metadata number_of_pages = len(pdf.pages) print(f"\nInformation for PDF: {path}") print(f"{'=' * 40}") print(info) print(f"Number of pages: {number_of_pages}") author = info.author creator = info.creator producer = info.producer subject = info.subject title = info.title # Print additional extracted information print(f"\nExtracted metadata:") print(f"Title: {title}") print(f"Author: {author}") print(f"Creator: {creator}") print(f"Producer: {producer}") print(f"Subject: {subject}") except Exception as e: print(f"Error processing {path}: {e}") def print_usage(): print(f"Usage: python {os.path.basename(__file__)} [pdf_file2] [pdf_file3] ...") print("Example: python get_doc_info.py document.pdf") if __name__ == '__main__': # Check if any command line argu

Sharing a personal account of how I managed to regain control of a document management problem, with help from a single Python library and Amazon Q Developer CLI. Hoping you find inspiration, along with a few helpful coding tips to address your next challenge.
Amazon Q Developer CLI is a command-line tool that acts like a personal assistant right in your terminal. It's always there and ready to answer your programming questions, or help manage tasks. Here's some of what Q Developer CLI can do:
- Answer questions about programming concepts, AWS services, and a variety of software development best practices
- Write and debug code for many popular languages
- Explain errors, and suggest fixes
- Interact with many services, and tools through the CLI interface
The beauty of Q Developer CLI is you don't need to switch between the terminal and a web browser when coding. Just type q chat and start a conversation from your command line. When finished, type /quit to exit.
The Problem
Recently, I came to the realization that my catalogue of personal PDF files has become a mess. For years, I've been digitizing my life opting out of paper statements like bank records, invoices, and magazines, converting it all into pile-free electronic euphoria. It has prevented my home from becoming a mountain of paper, plus I'm able to carry documents with me anywhere on my mobile devices. Life was good, until it wasn't anymore.
I saw it coming for some time, but pretended it wasn't an issue. Today, my iPad and storage on my PC is the digital equivalent of the paper mountain I worked long and hard to avoid. I tried moving PDFs to the cloud, but that basically created another paper mountain...only this time in the cloud where the mountain rises even higher!
The Opportunity
It was time to figure out what to do next, and I decided to consolidate the chaos. Storage wasn't the issue, management was. How could I maintain my digital well being in a useful way? Thankfully, I found a convenient, Do-It-Yourself solution that combines months (in some cases years!) of e-docs into a single one. It hasn't solved my problem entirely, but it is REAL progress!
The Tools
Enter Amazon Q Developer CLI and pypdf. Earlier, I described a few of Q Developer CLI's capabilities. You can find additional details along with a link to installation and setup instructions here. pypdf is a free, open source library for creating and managing PDF documents. Among the many features, consolidating multiple files together is what intrigued me the most. I've done file consolidation before using printer utilities, but that approach is clunky, not very intuitive, or efficient.
Make sure you have Python 3.9 or higher installed on your system. Instructions for setting up Python for your operating system can be found here.

The Fix
After pouring over the pypdf documentation I knew my solution was doable, but to make it more intuitive I thought,
"...why not go further and build a simple app that lets me drop files into a browser interface to combine them?!"
Works for me because it is also efficient, and it would put me back in control. Not wanting to procrastinate given the opportunity, I launched Q Developer CLI and started my project. q chat to the rescue!
Step 1: The Basics
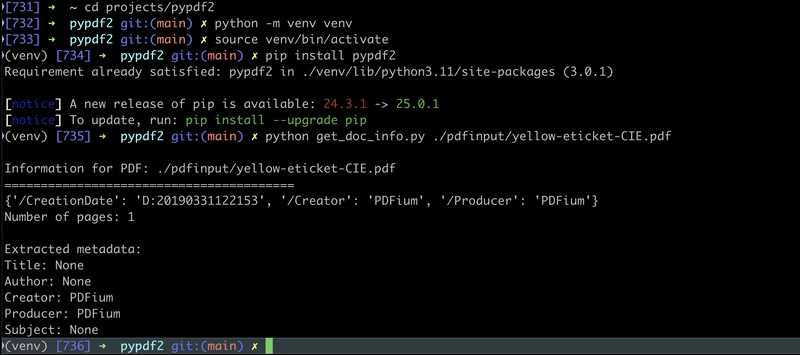
First, I needed to familiarize myself with pypdf as this was my first dive into using the library. The docs were helpful, and I was able to write a first program in a few minutes. What I created was a routine that was able to read and extract info from any PDF. With the code below, I created the file get_doc_info.py and then conducted a brief test in the virtual environment created with the steps illustrated. This was simple enough that I didn't seek help from Q Developer CLI, but feel free if you need to on your first attempt!
# from PyPDF2 import PdfFileReader
from PyPDF2 import PdfReader
import sys
import os
def get_info(path):
try:
with open(path, 'rb') as f:
pdf = PdfReader(f)
info = pdf.metadata
number_of_pages = len(pdf.pages)
print(f"\nInformation for PDF: {path}")
print(f"{'=' * 40}")
print(info)
print(f"Number of pages: {number_of_pages}")
author = info.author
creator = info.creator
producer = info.producer
subject = info.subject
title = info.title
# Print additional extracted information
print(f"\nExtracted metadata:")
print(f"Title: {title}")
print(f"Author: {author}")
print(f"Creator: {creator}")
print(f"Producer: {producer}")
print(f"Subject: {subject}")
except Exception as e:
print(f"Error processing {path}: {e}")
def print_usage():
print(f"Usage: python {os.path.basename(__file__)} [pdf_file2] [pdf_file3] ...")
print("Example: python get_doc_info.py document.pdf")
if __name__ == '__main__':
# Check if any command line arguments were provided
if len(sys.argv) < 2:
print("Error: No PDF files specified.")
print_usage()
sys.exit(1)
# Process each PDF file provided as an argument
for pdf_path in sys.argv[1:]:
get_info(pdf_path)
The following steps are as follows,
$ cd project_dir/
$ python -m venv venv
$ source venv/bin/activate
$ pip install pypdf2
# To run the program
$ python get_doc_info.py [your_file].PDF
Everything works...great! Now we can move on to the next task.
Step 2: Add more features
With the first hurdle cleared, I began focusing on addressing the reason I started this journey...merging my PDFs. A lot of the files are saved by month, quarter, or year. For example, bank statements are arranged in a folder structure like this,
.
├── bank_name
│ └── YYYY
│ └── statement-Jan.pdf
│ └── statement-Feb.pdf
│ :
│ └── statement-Dec.pdf
Some directory structures include 7+ years of statements. What I wanted to do was take a year's worth of statements, and merge those PDFs into one. In other words turn,
.
├── bank_name
│ └── 2021
│ └── statement-Jan-2021.pdf
│ └── statement-Feb-2021.pdf
│ :
│ └── statement-Dec-2021.pdf
into a single bank_name/2021/statements-2021.pdf file. For my needs, combining transaction records from four years ago into a single doc shouldn't be a problem.
The same logic can be applied to practically any set of docs. They could be utility bills, medical records, or school transcripts. As owner of the docs, you get to decide what's best for your management style.
Here is where I started to ask Q Developer CLI for help. Before I proceed with more details, please note that I don't want to take away from your own experience with Q Developer CLI and have kept that in mind with the descriptions and screen captures provided! It's plenty to help you progress, but I'm confident you'll get the most benefit out of witnessing the magic first hand!
I began by launching q chat and entering my first prompt,
>analyze the get_info_doc.py file and develop a new program. This new program should leverage the pypdf2 library and identify one or more PDF files, and consolidate those files into a single document. Make the program as efficient as possible.
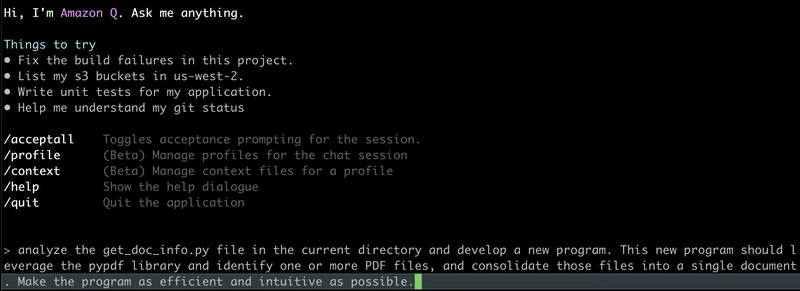
And off Q Developer CLI goes! In a nutshell here are the steps the tool executed in the development of the next program,
- Reads and examines
get_doc_info.pyto understand its functionality, coding style, and how the pypdf library was being used. - Drafted a version of
pdf_merger.pyadding functionality for merging PDFs, handling command line arguments, errors, and implementing a file output directory structure. - Made recommendations for testing and refinement.
- Documented the code with instructions for how to setup and run the pdf_merger.py program. If it doesn't do it for you automatically, be sure to ask Q Developer CLI to document the project. You'll be glad you did!
Here is the generated code for pdf_merger.py,
#!/usr/bin/env python3
# pdf_merger.py
from PyPDF2 import PdfMerger
import sys
import os
import datetime
def merge_pdfs(input_paths, output_path):
"""
Merge multiple PDF files into a single PDF file
Args:
input_paths (list): List of paths to input PDF files
output_path (str): Path where the merged PDF will be saved
"""
try:
merger = PdfMerger()
# Add each PDF to the merger
for pdf_path in input_paths:
print(f"Adding {pdf_path} to merger...")
merger.append(pdf_path)
# Create output directory if it doesn't exist
os.makedirs(os.path.dirname(output_path), exist_ok=True)
# Write the merged PDF to the output file
print(f"Writing merged PDF to {output_path}")
merger.write(output_path)
merger.close()
print(f"\nSuccessfully merged {len(input_paths)} PDF files into {output_path}")
print(f"Output file size: {os.path.getsize(output_path) / 1024:.2f} KB")
except Exception as e:
print(f"Error merging PDFs: {e}")
return False
return True
def print_usage():
print(f"Usage: python {os.path.basename(__file__)} [pdf_file2] [pdf_file3] ...")
print("Example: python pdf_merger.py document1.pdf document2.pdf")
print("Output will be saved to ./pdfoutput/merged_YYYYMMDD_HHMMSS.pdf")
if __name__ == '__main__':
# Check if any command line arguments were provided
if len(sys.argv) < 2:
print("Error: No PDF files specified.")
print_usage()
sys.exit(1)
# Get input PDF files from command line arguments
input_files = sys.argv[1:]
# Validate that all input files exist
invalid_files = [f for f in input_files if not os.path.exists(f)]
if invalid_files:
print("Error: The following files do not exist:")
for file in invalid_files:
print(f" - {file}")
sys.exit(1)
# Generate output filename with timestamp
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
output_file = f"./pdfoutput/merged_{timestamp}.pdf"
# Merge the PDFs
if merge_pdfs(input_files, output_file):
print("\nPDF merging completed successfully!")
else:
print("\nPDF merging failed.")
sys.exit(1)
To test, I used a few PDFs from some online exams I had taken awhile ago and executed pdf_merger.py inside the virtual environment configured earlier,
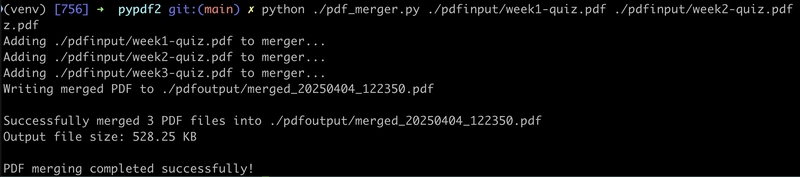
Great, another functioning program. The needs of the solution are now met, but we still want to create that intuitive interface.
Step 3: Build a web interface
This next step should be pretty self-explanatory, so I'll jump right into the details and show some of the exciting results. First, I asked Q Developer CLI to write the interface,
>expand the project by creating a browser inteface that can handle file uploads. process the selected PDFs as arguments to pdf_merger.py, and provide a download utility for storing the merged files. Be sure to include all of the basic error handling, file validation, and list needs. Use HTML, css, and javascript in an efficient manner.
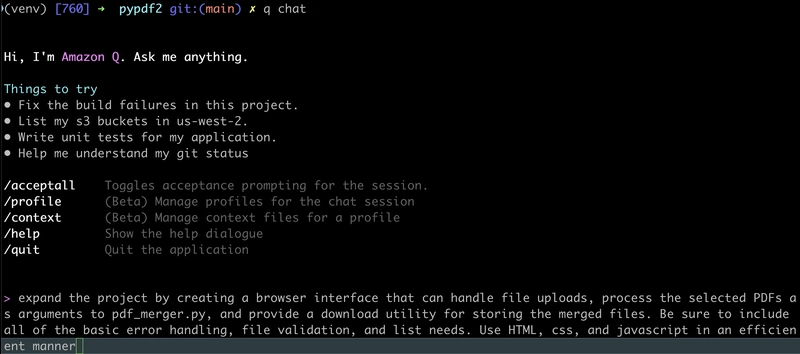
Thinking through and executing on those prompt details, Q Developer CLI exceeded most of my expectations. The result was a browser interface using Flask that delivered on the requirements. The lone exception (which I'm currently working at the moment!) is fixing the drag feature in the drag & drop capabilities. I can drop files, but can't drag them yet. Not worried though as I'm confident I'll get it resolved. If anyone beats me to the punch, feel free to include a comment to this article on how you fixed it!
#!/usr/bin/env python3
# app.py - Web interface for PDF merger
from flask import Flask, render_template, request, redirect, url_for, flash, send_from_directory
import os
import datetime
from werkzeug.utils import secure_filename
from pdf_merger import merge_pdfs
app = Flask(__name__)
app.secret_key = 'pdf_merger_secret_key' # Required for flash messages
# Configure upload folder
UPLOAD_FOLDER = 'uploads'
OUTPUT_FOLDER = 'pdfoutput'
ALLOWED_EXTENSIONS = {'pdf'}
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
app.config['MAX_CONTENT_LENGTH'] = 16 * 1024 * 1024 # 16MB max upload size
# Create necessary directories
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
os.makedirs(OUTPUT_FOLDER, exist_ok=True)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
@app.route('/')
def index():
return render_template('index.html')
@app.route('/merge', methods=['POST'])
def merge():
# Check if the post request has the file part
if 'files[]' not in request.files:
flash('No files selected')
return redirect(request.url)
files = request.files.getlist('files[]')
# If user does not select file, browser also
# submit an empty part without filename
if not files or files[0].filename == '':
flash('No files selected')
return redirect(url_for('index'))
# Filter out non-PDF files
pdf_files = [f for f in files if f and allowed_file(f.filename)]
if not pdf_files:
flash('No PDF files selected')
return redirect(url_for('index'))
# Save uploaded files
file_paths = []
for file in pdf_files:
filename = secure_filename(file.filename)
file_path = os.path.join(app.config['UPLOAD_FOLDER'], filename)
file.save(file_path)
file_paths.append(file_path)
# Generate output filename with timestamp
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
output_filename = f"merged_{timestamp}.pdf"
output_path = os.path.join(OUTPUT_FOLDER, output_filename)
# Merge PDFs
success = merge_pdfs(file_paths, output_path)
# Clean up uploaded files
for file_path in file_paths:
try:
os.remove(file_path)
except:
pass
if success:
flash('PDFs merged successfully!')
return redirect(url_for('download_file', filename=output_filename))
else:
flash('Error merging PDFs')
return redirect(url_for('index'))
@app.route('/download/')
def download_file(filename):
return render_template('download.html', filename=filename)
@app.route('/get_file/')
def get_file(filename):
return send_from_directory(OUTPUT_FOLDER, filename, as_attachment=True)
if __name__ == '__main__':
app.run(debug=True)
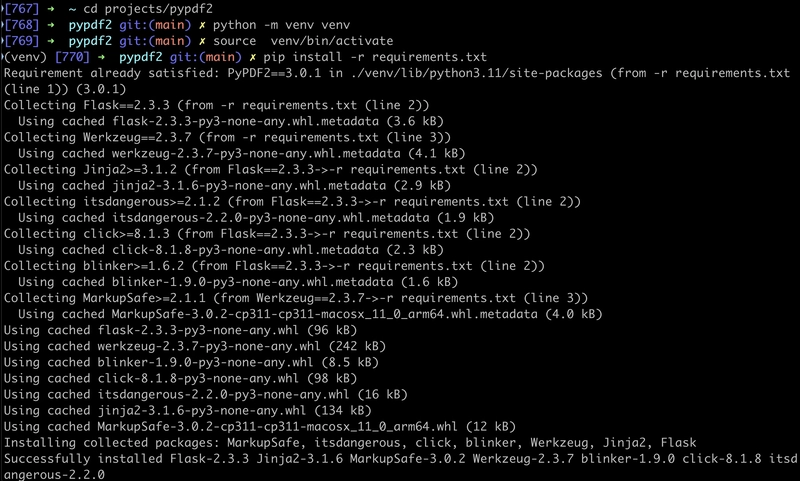
Next, I setup a virtual environment to launch the browser. Note that Q Developer CLI added a requirements.txt file making it easier to load all of the application dependencies.
# requirements.txt
PyPDF2==3.0.1
Flask==2.3.3
Werkzeug==2.3.7
$ cd project_dir/
$ python -m venv venv
$ source venv/bin/activate
$ pip install -r requirements.txt
We're now ready to run flask and launch a web browser,
# To run the program
$ python app.py
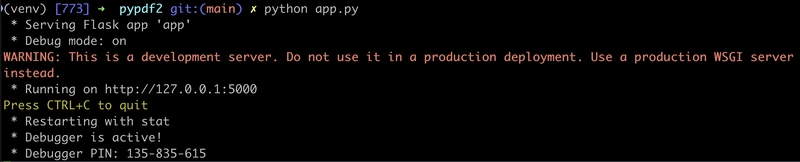
Connect to http://127.0.0.1:5000 and you should see the following PDFMerger interface,
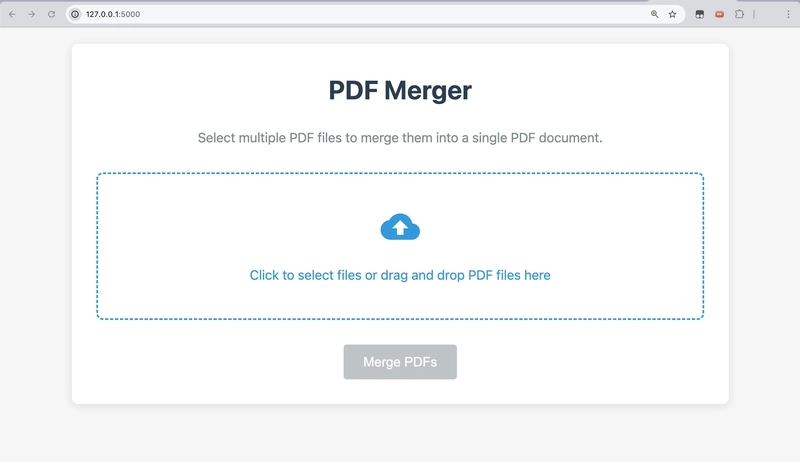
I then conduct another run to merge the test documents using the browser interface this time,
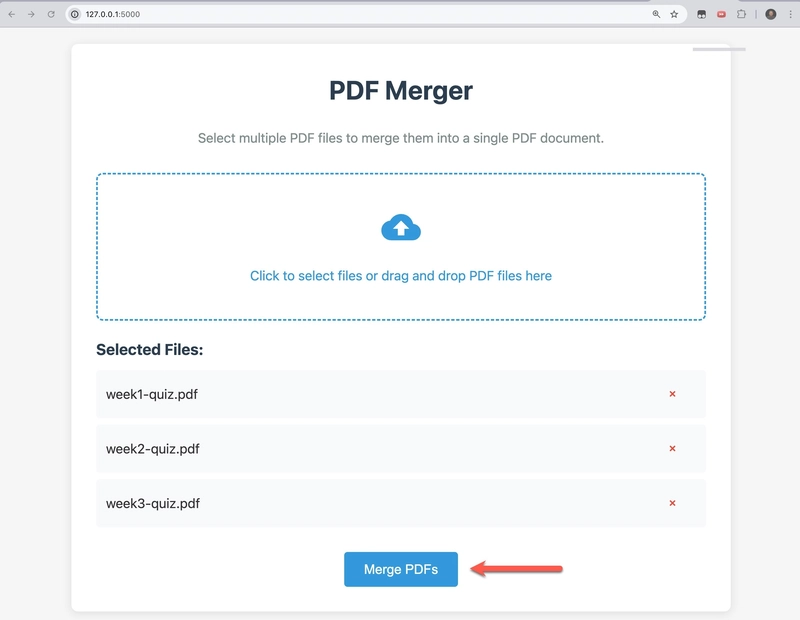
SUCCESS!!!
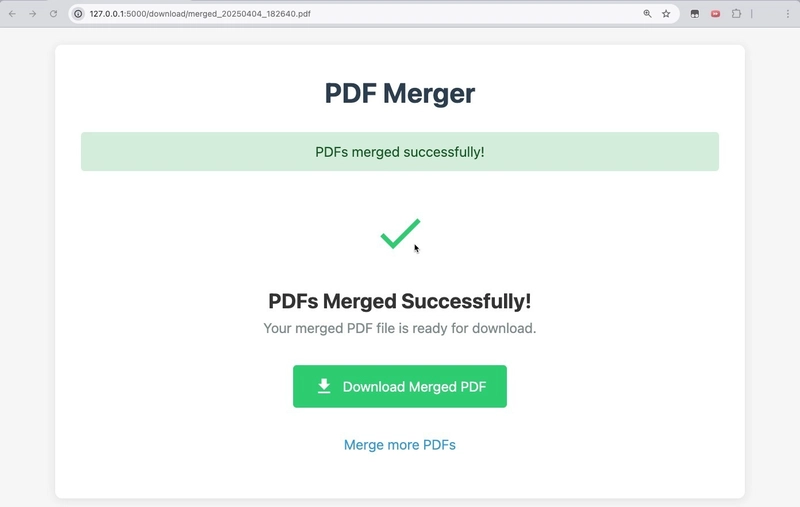
CONCLUSION
Have problem, will travel! I just walked you through an example use case of how Amazon Q Developer CLI with its AI-powered features can help you get things done fast and efficient. If you're a developer that wants to take advantage of the benefits available to you from the command line, I highly recommend that you give this tool a try. Installation instructions and much more can be found in the Q Developer user guide, so have a look and set yourself up for the next great development journey!



