![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)






























































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)












































































































.png?#)

































_Christophe_Coat_Alamy.jpg?#)
 (1).webp?#)





































































































![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)






























































































































Unvibe: A Python Test-Runner that generates valid code
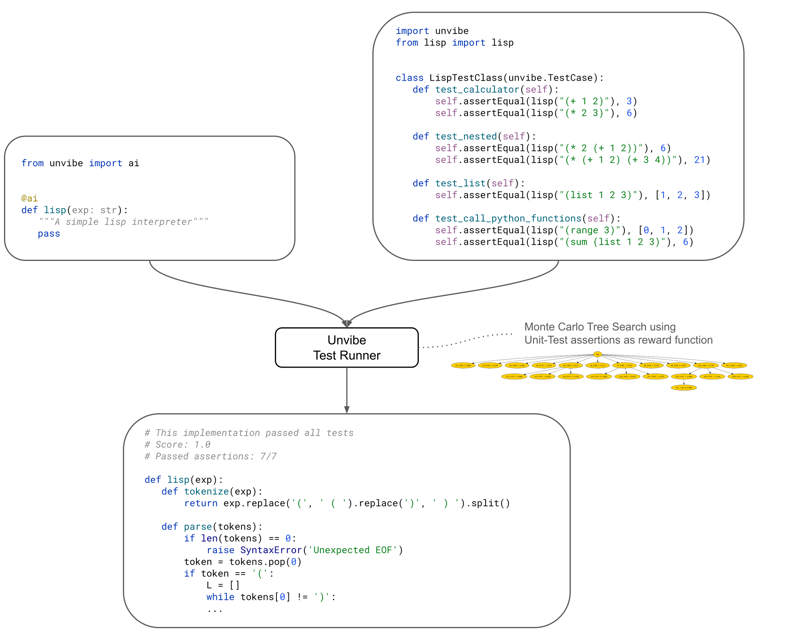
TL;DR Vibe coding is fine for prototypes. When projects get complicated, vibing doesn't work [Unvibe](https://claudio.uk/posts/unvibe.html] is a Python Test Runner that quickly generates many alternative implementations for functions and classes you annotate with @ai, and re-runs your unit-tests until it finds a correct implementation. So you "Vibe the unit-tests", and then search a correct implementation. This scales to larger projects and applies to existing code bases, as long as they are decently unit-tested. A different way to generate code with LLMs In my daily work as consultant, I'm often dealing with large pre-exising code bases. I use GitHub Copilot a lot. It's now basically indispensable, but I use it mostly for generating boilerplate code, or figuring out how to use a library. As the code gets more logically nested though, Copilot crumbles under the weight of complexity. It doesn't know how things should fit together in the project. Other AI tools like Cursor or Devon, are pretty good at generating quickly working prototypes, but they are not great at dealing with large existing codebases, and they have a very low success rate for my kind of daily work. You find yourself in an endless loop of prompt tweaking, and at that point, I'd rather write the code myself with the occasional help of Copilot. Professional coders know what code they want, we can define it with unit-tests, we don't want to endlessly tweak the prompt. Also, we want it to work in the larger context of the project, not just in isolation. In this article I am going to introduce a pretty new approach (at least in literature), and a Python library that implements it: a tool that generates code from unit-tests. My basic intuition was this: shouldn't we be able to drastically speed up the generation of valid programs, while ensuring correctness, by using unit-tests as reward function for a search in the space of possible programs? I looked in the academic literature, it's not new: it's reminiscent of the approach used in DeepMind FunSearch, AlphaProof, AlphaGeometry and other experiments like TiCoder: see Research Chapter for pointers to relevant papers. Writing correct code is akin to solving a mathematical theorem. We are basically proving a theorem using Python unit-tests instead of Lean or Coq as an evaluator. For people that are not familiar with Test-Driven development, read here about TDD and Unit-Tests. How it works I've implemented this idea in a Python library called Unvibe. It implements a variant of Monte Carlo Tree Search that invokes an LLM to generate code for the functions and classes in your code that you have decorated with @ai. Unvibe supports most of the popular LLMs: Ollama, OpenAI, Claude, Gemini, DeepSeek. Unvibe uses the LLM to generate a few alternatives, and runs your unit-tests as a test runner (like pytest or unittest). It then feeds back the errors returned by failing unit-test to the LLMs, in a loop that maximizes the number of unit-test assertions passed. This is done in a sort of tree search, that tries to balance exploitation and exploration. As explained in the DeepMind FunSearch paper, having a rich score function is key for the success of the approach: You can define your tests by inheriting the usual unittests.TestCase class, but if you use unvibe.TestCase instead you get a more precise scoring function (basically we count up the number of assertions passed rather than just the number of tests passed). It turns out that this approach works very well in practice, even in large existing code bases, provided that the project is decently unit-tested. This is now part of my daily workflow: Use Copilot to generate boilerplate code Define the complicated functions/classes I know Copilot can't handle Define unit-tests for those complicated functions/classes (quick-typing with GitHub Copilot) Use Unvibe to generate valid code that pass those unit-tests It also happens quite often that Unvibe find solutions that pass most of the tests but not 100%: often it turns out some of my unit-tests were misconceived, and it helps figure out what I really wanted. Example: how to use unvibe pip install unvibe Decorate the functions/classes you want to generate with @ai. Type annotations and proper comments will help the LLM figure out what you want. For example # list.py from unvibe import ai @ai def lisp(expr: str): """A simple lisp interpreter implemented in plain Python""" pass Now let's define a few unit-tests to specify the behaviour of the function. Here Copilot can help us come up quickly with a few test cases. As you can see, we are looking to implement a Lisp interpreter that supports basic python functions (e.g. range) and returns python-compatible lists. This simple Lisp interpreter is a good example because it's the sort of function that LLMs (even reasoning models) cannot generate from scratch, but they can get there with U
TL;DR
- Vibe coding is fine for prototypes. When projects get complicated, vibing doesn't work
- [Unvibe](https://claudio.uk/posts/unvibe.html] is a Python Test Runner that quickly generates many alternative implementations for functions
and classes you annotate with
@ai, and re-runs your unit-tests until it finds a correct implementation. - So you "Vibe the unit-tests", and then search a correct implementation.
- This scales to larger projects and applies to existing code bases, as long as they are decently unit-tested.
A different way to generate code with LLMs
In my daily work as consultant, I'm often dealing with large pre-exising code bases.
I use GitHub Copilot a lot.
It's now basically indispensable, but I use it mostly for generating boilerplate code, or figuring out how to use a library.
As the code gets more logically nested though, Copilot crumbles under the weight of complexity. It doesn't know how things should fit together in the project.
Other AI tools like Cursor or Devon, are pretty good at generating quickly working prototypes,
but they are not great at dealing with large existing codebases, and they have a very low success rate for my kind of daily work.
You find yourself in an endless loop of prompt tweaking, and at that point, I'd rather write the code myself with
the occasional help of Copilot.
Professional coders know what code they want, we can define it with unit-tests, we don't want to endlessly tweak the prompt.
Also, we want it to work in the larger context of the project, not just in isolation.
In this article I am going to introduce a pretty new approach (at least in literature), and a Python library that implements it:
a tool that generates code from unit-tests.
My basic intuition was this: shouldn't we be able to drastically speed up the generation of valid programs, while
ensuring correctness, by using unit-tests as reward function for a search in the space of possible programs?
I looked in the academic literature, it's not new: it's reminiscent of the
approach used in DeepMind FunSearch, AlphaProof, AlphaGeometry and other experiments like TiCoder: see Research Chapter for pointers to relevant papers.
Writing correct code is akin to solving a mathematical theorem. We are basically proving a theorem
using Python unit-tests instead of Lean or Coq as an evaluator.
For people that are not familiar with Test-Driven development, read here about TDD
and Unit-Tests.
How it works
I've implemented this idea in a Python library called Unvibe. It implements a variant of Monte Carlo Tree Search
that invokes an LLM to generate code for the functions and classes in your code that you have
decorated with @ai.
Unvibe supports most of the popular LLMs: Ollama, OpenAI, Claude, Gemini, DeepSeek.
Unvibe uses the LLM to generate a few alternatives, and runs your unit-tests as a test runner (like pytest or unittest).
It then feeds back the errors returned by failing unit-test to the LLMs, in a loop that maximizes the number
of unit-test assertions passed. This is done in a sort of tree search, that tries to balance
exploitation and exploration.
As explained in the DeepMind FunSearch paper, having a rich score function is key for the success of the approach:
You can define your tests by inheriting the usual unittests.TestCase class, but if you use unvibe.TestCase instead
you get a more precise scoring function (basically we count up the number of assertions passed rather than just the number
of tests passed).
It turns out that this approach works very well in practice, even in large existing code bases,
provided that the project is decently unit-tested. This is now part of my daily workflow:
Use Copilot to generate boilerplate code
Define the complicated functions/classes I know Copilot can't handle
Define unit-tests for those complicated functions/classes (quick-typing with GitHub Copilot)
Use Unvibe to generate valid code that pass those unit-tests
It also happens quite often that Unvibe find solutions that pass most of the tests but not 100%:
often it turns out some of my unit-tests were misconceived, and it helps figure out what I really wanted.
Example: how to use unvibe
pip install unvibe- Decorate the functions/classes you want to generate with
@ai. Type annotations and proper comments will help the LLM figure out what you want. For example
# list.py
from unvibe import ai
@ai
def lisp(expr: str):
"""A simple lisp interpreter implemented in plain Python"""
pass
Now let's define a few unit-tests to specify the behaviour of the function.
Here Copilot can help us come up quickly with a few test cases.
As you can see, we are looking to implement a Lisp interpreter that supports basic
python functions (e.g. range) and returns python-compatible lists.
This simple Lisp interpreter is a good example because it's the sort
of function that LLMs (even reasoning models) cannot generate from scratch, but they can
get there with Unvibe:
# test_lisp.py
import unvibe
from lisp import lisp
# Here you can instead inherit unvibe.TestCase, to get a more granular scoring function
class LispInterpreterTestClass(unvibe.TestCase):
def test_calculator(self):
self.assertEqual(lisp("(+ 1 2)"), 3)
self.assertEqual(lisp("(* 2 3)"), 6)
def test_nested(self):
self.assertEqual(lisp("(* 2 (+ 1 2))"), 6)
self.assertEqual(lisp("(* (+ 1 2) (+ 3 4))"), 21)
def test_list(self):
self.assertEqual(lisp("(list 1 2 3)"), [1, 2, 3])
def test_call_python_functions(self):
self.assertEqual(lisp("(list (range 3)"), [0, 1, 2])
self.assertEqual(lisp("(sum (list 1 2 3)"), 6)
3) Now run unvibe and let it search for a valid implementation that passes all the tests:
$ python -m unvibe lisp.py test_lisp.py
Unvibe will run until it reaches a maximum number of iterations or until it finds a solution that passes all the tests, in which case it will stop early.
The output will be written to a local file unvibe_lisp_:
# Unvibe Execution output.
# This implementation passed all tests
# Score: 1.0
# Passed assertions: 7/7
def lisp(exp):
def tokenize(exp):
return exp.replace('(', ' ( ').replace(')', ' ) ').split()
def parse(tokens):
if len(tokens) == 0:
raise SyntaxError('Unexpected EOF')
token = tokens.pop(0)
if token == '(':
L = []
while tokens[0] != ')':
L.append(parse(tokens))
tokens.pop(0) # Remove ')'
return L
elif token == ')':
raise SyntaxError('Unexpected )')
else:
try:
return int(token)
except ValueError:
return token
def evaluate(x):
if isinstance(x, list):
op = x[0]
args = x[1:]
if op == '+':
return sum(evaluate(arg) for arg in args)
elif op == '*':
result = 1
for arg in args:
result *= evaluate(arg)
return result
elif op == 'list':
return [evaluate(arg) for arg in args]
else:
# Call Python functions
return globals()[op](*[evaluate(arg) for arg in args])
return x
tokens = tokenize(exp)
return evaluate(parse(tokens))
As you can see, Unvibe has found a valid implementation. At this point, in my typical workflow, I would now add more tests
and eventually let Unvibe find other solutions.