![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)






























































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.png?#)


































_Christophe_Coat_Alamy.jpg?#)


.webp?#)






































































































![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)
![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)





























































































































Tiny URL Design
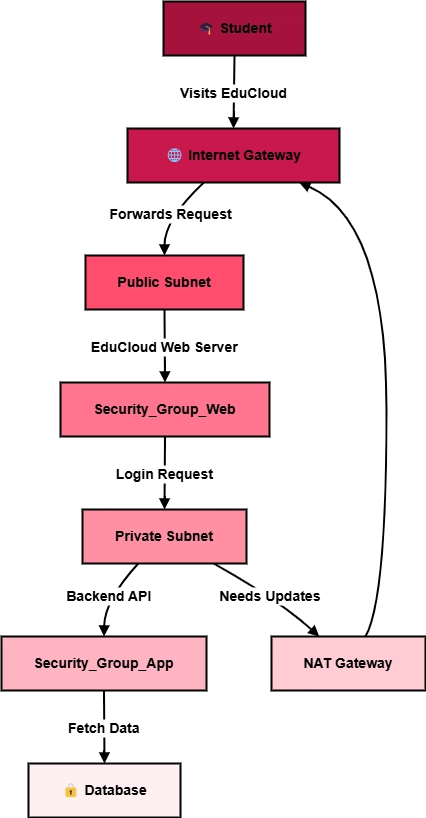
What is a Tiny URL It's a service that takes a long url like https://www.example.com/averylongpathoftheurlthatneedstobeshortened and converts it to something like https://sho.rt/34ssd21. Now whenever someone visits the short URL they will be redirected to the original URL Advantage With short url, it becomes easier to share and remember urls (provided you can define your own endpoint) Disadvantages The one problem that arises with this the risk of now knowing where you are getting redirected to. This can easily be used to phish people. Requirements Generate a short URL for a given long URL. Need to ensure they are unique. If not, then users can visit websites that they were not meant to see (like your portfolio) Be able to see the number of clicks of the short URL generated. Performance Consideration Median URL has 10k clicks and popular URL can have more than million clicks We may have to support 1 trillion short URLs at a time (Yes, its trillion) The average size of the short URL would be in KBs, so total space required would be 1 trillion * 1KB = 1 PB We will optimize for reads since most people would just be reading rather than generating Link generation In order to generate a shorter link for the provided long link, we can use a hash function which would take some parameters and generate a short url for us Example hash function hash(long_url, user_id, upload_timestamp) long_url: The URL that needs to be shorted user_id: The user who is shortening the URL upload_timestamp: The time at which the short url is created Now we need to accommodate a lot of URLs in order to avoid collision between the links, thus we need to determine the length of the short URL (this is the path of the URL i.e https://www.sho.rt/) We will be using lower case alphabets and digits to generate the short URL path. So now we have total 36 characters (10 digits + 26 alphabets). If the length of the short URL path is n then we have 36^n possibilities. In our earlier assumption we have aimed to store 1 Trillion URLs. For n = 8 Number of possibilities = 36 ^ 8 ~= 2 Trillion With n = 8, we have enough possibilities. So our hashed URL would look something like this hash(long_url, user_id, upload_timestamp) = https://www.sho.rt/2fjh7rw6 The length of short url path 2fjh7rw6 is 8 Now what should we do in order to deal with hash collisions, we can look for the next available hash since we would be storing the data in a DB table. Assigning URLs (Writes) Now we will try to decide on strategies to store the generated short URL. Replication We want to maximize our write throughput wherever possible even though our overall system would be optimized for reads. Now let's assume we are using multi leader replication. We have 2 masters. User 1 creates a link with hash abc on Master 1 and User 2 creates the same hash abc on Master 2. After some time both the Masters sync up, in doing so they encounter that hash abc exists on both of them. In order to solve this conflict the system is designed to use Last Write Wins policy. With that the value of abc is stored def.com which was uploaded by User 2 and the value xyz.com which was set by User 1 is lost. When User 3 who is expecting "xyz.com" for hash abc is getting def.com, this leads to confusion. The above issue can cause a lot of confusion and thus we will go with Single Leader Replication for our case With single leader we won't have the data lost issue as described above but we now have a single point of failure but since our system would be more read heavy, we should be find with Single leader replication Caching We can use cache in order to speed up our writes by first writing to our cache and then flush those values to our data base. This approach has the same issue of same hash being generated on both caches. So, using a cache would not make much sense here Partitioning It is an important aspect of our design since we can use it to improve our reads and writes by distributing the load across different nodes Since we have generated a short URL which is a hash we can use range based hashing reason being that the short URLs generated should be relatively even. Now if a hash is generated against a long URL and it is being stored in one of the nodes but that node already has the generated short URL entry, then we can use probing to deal with this. The advantage of probing is that similar hashes will be present in the same node. We also need to keep track of consistent hashing ring on coordination service, minimize reshuffling on cluster size change Single Node (Master Node) In single leader replication, we have a single write node. In this scenario there could be cases where 2 users end up generating the same hashes, What should be done in that situation ? We could use locking but the hash entry does not exist in the DB yet
What is a Tiny URL
It's a service that takes a long url like https://www.example.com/averylongpathoftheurlthatneedstobeshortened and converts it to something like https://sho.rt/34ssd21. Now whenever someone visits the short URL they will be redirected to the original URL
Advantage
With short url, it becomes easier to share and remember urls (provided you can define your own endpoint)
Disadvantages
The one problem that arises with this the risk of now knowing where you are getting redirected to. This can easily be used to phish people.
Requirements
- Generate a short URL for a given long URL. Need to ensure they are unique. If not, then users can visit websites that they were not meant to see (like your portfolio)
- Be able to see the number of clicks of the short URL generated.
Performance Consideration
- Median URL has 10k clicks and popular URL can have more than million clicks
- We may have to support 1 trillion short URLs at a time (Yes, its trillion)
- The average size of the short URL would be in KBs, so total space required would be
1 trillion * 1KB = 1 PB - We will optimize for reads since most people would just be reading rather than generating
Link generation
In order to generate a shorter link for the provided long link, we can use a hash function which would take some parameters and generate a short url for us
Example hash function
hash(long_url, user_id, upload_timestamp)
- long_url: The URL that needs to be shorted
- user_id: The user who is shortening the URL
- upload_timestamp: The time at which the short url is created
Now we need to accommodate a lot of URLs in order to avoid collision between the links, thus we need to determine the length of the short URL (this is the path of the URL i.e https://www.sho.rt/)
We will be using lower case alphabets and digits to generate the short URL path. So now we have total 36 characters (10 digits + 26 alphabets).
If the length of the short URL path is n then we have 36^n possibilities. In our earlier assumption we have aimed to store 1 Trillion URLs.
For n = 8
Number of possibilities = 36 ^ 8 ~= 2 Trillion
With n = 8, we have enough possibilities.
So our hashed URL would look something like this
hash(long_url, user_id, upload_timestamp) = https://www.sho.rt/2fjh7rw6
The length of short url path 2fjh7rw6 is 8
Now what should we do in order to deal with hash collisions, we can look for the next available hash since we would be storing the data in a DB table.
Assigning URLs (Writes)
Now we will try to decide on strategies to store the generated short URL.
Replication
We want to maximize our write throughput wherever possible even though our overall system would be optimized for reads.
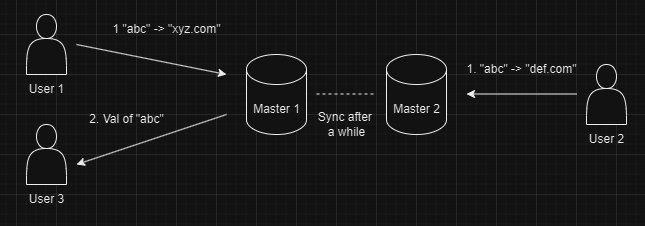
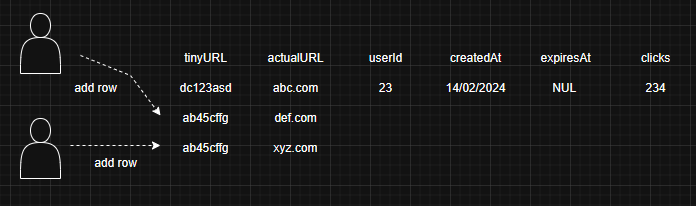
Now let's assume we are using multi leader replication. We have 2 masters.
User 1 creates a link with hash abc on Master 1 and User 2 creates the same hash abc on Master 2.
After some time both the Masters sync up, in doing so they encounter that
hash abc exists on both of them. In order to solve this conflict the system is designed to use Last Write Wins policy. With that the value of abc is stored def.com which was uploaded by User 2 and the value xyz.com which was set by User 1 is lost.
When User 3 who is expecting "xyz.com" for hash abc is getting def.com, this leads to confusion.
The above issue can cause a lot of confusion and thus we will go with Single Leader Replication for our case
With single leader we won't have the data lost issue as described above but we now have a single point of failure but since our system would be more read heavy, we should be find with Single leader replication
Caching
We can use cache in order to speed up our writes by first writing to our cache and then flush those values to our data base.
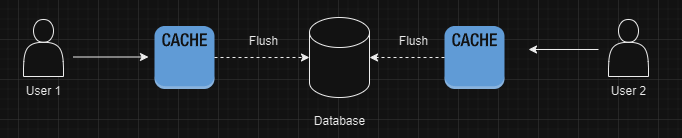
This approach has the same issue of same hash being generated on both caches.
So, using a cache would not make much sense here
Partitioning
It is an important aspect of our design since we can use it to improve our reads and writes by distributing the load across different nodes
Since we have generated a short URL which is a hash we can use range based hashing reason being that the short URLs generated should be relatively even.
Now if a hash is generated against a long URL and it is being stored in one of the nodes but that node already has the generated short URL entry, then we can use probing to deal with this. The advantage of probing is that similar hashes will be present in the same node.
We also need to keep track of consistent hashing ring on coordination service, minimize reshuffling on cluster size change
Single Node (Master Node)
In single leader replication, we have a single write node. In this scenario there could be cases where 2 users end up generating the same hashes, What should be done in that situation ? We could use locking but the hash entry does not exist in the DB yet
To deal with this we have some workarounds
Predicate Locks
What are predicate locks ? This is a shared lock on row based on some condition that is satisfied.
For example,
We have the below query
SELECT * FROM urls WHERE shorturl = 'dgf4221d'
Now user1 is trying to run this query and in the meanwhile user2 is already utilizing the conditions mentioned in the above query then user1 needs to wait for user2 to finish.
Now we can lock the rows that don't exist yet and then insert the required row. If another user wants to create the same entry they will not be able to do so, since there is a predicate lock on the row because of the first user.
Example query to create a lock on the row (For Postgres)
BEGIN TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- Check if the user exists (this will acquire a predicate lock)
SELECT * FROM users WHERE email = 'user@example.com';
-- If no rows are found, insert
INSERT INTO users (email, name) VALUES ('user@example.com', 'John Doe');
COMMIT;
In order to improve the speed of the queries we can index on the short url column would make the predicate query much faster(O(n) vs O(logN))
We can also use stored procedure to deal with hash collision. If a user receives a collision then we can use probing to store the long url in the next available hash for the user.
Materializing conflicts
We can populate all the DB with all the possible rows so that users can lock onto row when they are trying to write.
Let's calculate the total space required to store 2 trillion short urls
No. of rows = 2 trillion
Size of 1 character = 1 byte
Length of each short url = 8
Total Space required = 2 trillion * 1 byte * 8 characters = 16 TB
16TB is not a lot of storage since we have personal PC with 1 TB storages
When a user is updating an existing entry, the DB will lock that row and if another user tries to update the same row then they would be incapable of doing so
Engine Implementation
We don't need range-based queries since we are going to mostly query a single row while reading or writing. So, a hash index would be much faster. We cannot use a in memory DB since we have 16 TB of data.
We have 2 choices - LSM tree + SS Table and BTree