









































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)

















































































































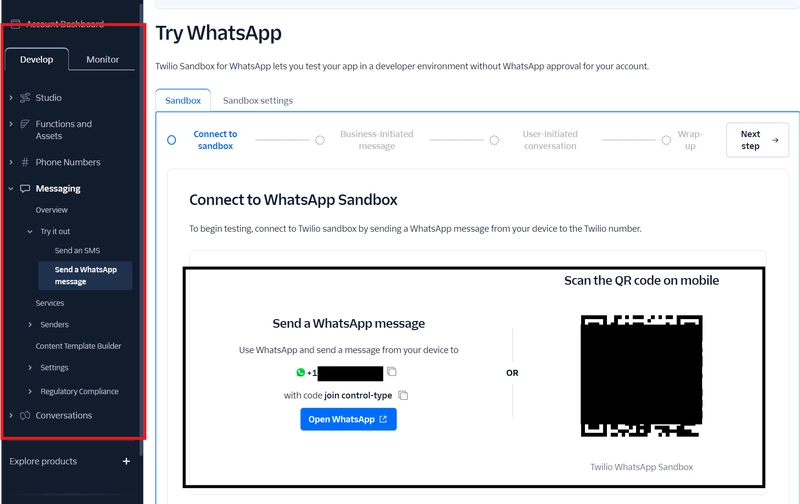













![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)














































-Mario-Kart-World-Hands-On-Preview-Is-It-Good-00-08-36.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)

























































.png?#)






(1).jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)



























_Igor_Mojzes_Alamy.jpg?#)


.webp?#)
.webp?#)






































































































![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)
![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)
























































































































Mastering Parallel Programming in Rust with Rayon: A Performance Guide
As a best-selling author, I invite you to explore my books on Amazon. Don't forget to follow me on Medium and show your support. Thank you! Your support means the world! Parallel programming has always fascinated me. Throughout my career, I've watched how multi-core processing has transformed software development, making it both more powerful and more complex. Rust's Rayon library stands as one of the most elegant solutions I've encountered for parallelism challenges. Rayon offers a remarkably simple approach to parallel computing in Rust. Instead of wrestling with thread management, locks, and synchronization primitives, developers can focus on their algorithms while Rayon handles the parallel execution details. When I first discovered Rayon, I was struck by how it transformed complex parallel programming concepts into accessible patterns that align with Rust's safety guarantees. The library maintains Rust's core principles - safety, performance, and ergonomics - while opening up parallel computation. Understanding Rayon Rayon operates on a work-stealing scheduler model. This design efficiently distributes workloads across available CPU cores, dynamically balancing tasks to ensure optimal processor utilization. Each worker thread takes tasks from a queue, and when its queue is empty, it "steals" work from other busy threads. The core of Rayon's API revolves around parallel iterators. These parallel versions of Rust's standard iterators allow operations to be performed concurrently on collection elements. What makes Rayon especially powerful is how little code needs to change to transform sequential processing into parallel execution. use rayon::prelude::*; fn main() { let numbers = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; // Sequential map operation let squares_sequential: Vec = numbers.iter() .map(|&x| x * x) .collect(); // Parallel map operation - notice the minimal change let squares_parallel: Vec = numbers.par_iter() .map(|&x| x * x) .collect(); assert_eq!(squares_sequential, squares_parallel); } The transition from iter() to par_iter() is often all you need to parallelize operations on collections. This design makes parallel programming accessible even to developers without extensive concurrent programming experience. The Power of Par_iter Parallel iterators are Rayon's most commonly used feature. They support most of the same operations as standard iterators, but execute in parallel: use rayon::prelude::*; fn main() { let data = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; // Parallel filter and sum let sum_of_even: i32 = data.par_iter() .filter(|&&x| x % 2 == 0) .sum(); println!("Sum of even numbers: {}", sum_of_even); // Parallel map and reduce let product: i32 = data.par_iter() .map(|&x| x * 2) .reduce(|| 1, |a, b| a * b); println!("Product of doubled values: {}", product); } I've found this pattern incredibly useful for data processing tasks. The ability to chain operations while maintaining parallelism creates clean, maintainable code that effectively utilizes available hardware. Rayon also provides specialized iterators for common scenarios: use rayon::prelude::*; fn main() { // Parallel iteration over a range let sum: u64 = (1..1_000_000).into_par_iter().sum(); // Parallel iteration over mutable references let mut data = vec![1, 2, 3, 4]; data.par_iter_mut().for_each(|x| *x *= 2); // Parallel enumeration let indexed: Vec = vec![10, 20, 30].into_par_iter() .enumerate() .collect(); } Divide and Conquer with Join For algorithms that don't fit the iterator model, Rayon provides the join function. This enables recursive divide-and-conquer approaches, where a problem is split into smaller sub-problems that can be solved independently. use rayon::prelude::*; fn fibonacci(n: u64) -> u64 { if n f64 { let in_circle = (0..sample_count) .into_par_iter() .map(|_| { let mut rng = rand::thread_rng(); let x: f64 = rng.gen_range(-1.0..1.0); let y: f64 = rng.gen_range(-1.0..1.0); if x*x + y*y bool { if n

As a best-selling author, I invite you to explore my books on Amazon. Don't forget to follow me on Medium and show your support. Thank you! Your support means the world!
Parallel programming has always fascinated me. Throughout my career, I've watched how multi-core processing has transformed software development, making it both more powerful and more complex. Rust's Rayon library stands as one of the most elegant solutions I've encountered for parallelism challenges.
Rayon offers a remarkably simple approach to parallel computing in Rust. Instead of wrestling with thread management, locks, and synchronization primitives, developers can focus on their algorithms while Rayon handles the parallel execution details.
When I first discovered Rayon, I was struck by how it transformed complex parallel programming concepts into accessible patterns that align with Rust's safety guarantees. The library maintains Rust's core principles - safety, performance, and ergonomics - while opening up parallel computation.
Understanding Rayon
Rayon operates on a work-stealing scheduler model. This design efficiently distributes workloads across available CPU cores, dynamically balancing tasks to ensure optimal processor utilization. Each worker thread takes tasks from a queue, and when its queue is empty, it "steals" work from other busy threads.
The core of Rayon's API revolves around parallel iterators. These parallel versions of Rust's standard iterators allow operations to be performed concurrently on collection elements. What makes Rayon especially powerful is how little code needs to change to transform sequential processing into parallel execution.
use rayon::prelude::*;
fn main() {
let numbers = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
// Sequential map operation
let squares_sequential: Vec<i32> = numbers.iter()
.map(|&x| x * x)
.collect();
// Parallel map operation - notice the minimal change
let squares_parallel: Vec<i32> = numbers.par_iter()
.map(|&x| x * x)
.collect();
assert_eq!(squares_sequential, squares_parallel);
}
The transition from iter() to par_iter() is often all you need to parallelize operations on collections. This design makes parallel programming accessible even to developers without extensive concurrent programming experience.
The Power of Par_iter
Parallel iterators are Rayon's most commonly used feature. They support most of the same operations as standard iterators, but execute in parallel:
use rayon::prelude::*;
fn main() {
let data = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
// Parallel filter and sum
let sum_of_even: i32 = data.par_iter()
.filter(|&&x| x % 2 == 0)
.sum();
println!("Sum of even numbers: {}", sum_of_even);
// Parallel map and reduce
let product: i32 = data.par_iter()
.map(|&x| x * 2)
.reduce(|| 1, |a, b| a * b);
println!("Product of doubled values: {}", product);
}
I've found this pattern incredibly useful for data processing tasks. The ability to chain operations while maintaining parallelism creates clean, maintainable code that effectively utilizes available hardware.
Rayon also provides specialized iterators for common scenarios:
use rayon::prelude::*;
fn main() {
// Parallel iteration over a range
let sum: u64 = (1..1_000_000).into_par_iter().sum();
// Parallel iteration over mutable references
let mut data = vec![1, 2, 3, 4];
data.par_iter_mut().for_each(|x| *x *= 2);
// Parallel enumeration
let indexed: Vec<(usize, i32)> = vec![10, 20, 30].into_par_iter()
.enumerate()
.collect();
}
Divide and Conquer with Join
For algorithms that don't fit the iterator model, Rayon provides the join function. This enables recursive divide-and-conquer approaches, where a problem is split into smaller sub-problems that can be solved independently.
use rayon::prelude::*;
fn fibonacci(n: u64) -> u64 {
if n <= 1 {
return n;
}
let (a, b) = rayon::join(
|| fibonacci(n - 1),
|| fibonacci(n - 2)
);
a + b
}
fn main() {
let result = fibonacci(40);
println!("Fibonacci(40) = {}", result);
}
While this specific example may not be the most efficient due to the overhead of spawning tasks for small computations, it demonstrates the pattern. For more complex divide-and-conquer algorithms like merge sort or tree traversals, this approach can yield significant performance improvements.
Real-World Applications
Image processing is an area where I've seen Rayon excel. Operations like blurring, edge detection, or color transformations are ideal candidates for parallelization:
use rayon::prelude::*;
use image::{GenericImageView, DynamicImage, Rgba};
fn apply_blur(img: &DynamicImage) -> DynamicImage {
let (width, height) = img.dimensions();
let mut output = DynamicImage::new_rgb8(width, height);
// Process pixels in parallel
(0..width).into_par_iter().for_each(|x| {
for y in 0..height {
let mut r_total = 0;
let mut g_total = 0;
let mut b_total = 0;
let mut count = 0;
// Simple box blur
for dx in -1..=1 {
for dy in -1..=1 {
let nx = x as i32 + dx;
let ny = y as i32 + dy;
if nx >= 0 && nx < width as i32 && ny >= 0 && ny < height as i32 {
let pixel = img.get_pixel(nx as u32, ny as u32);
r_total += pixel[0] as u32;
g_total += pixel[1] as u32;
b_total += pixel[2] as u32;
count += 1;
}
}
}
output.put_pixel(x, y, Rgba([
(r_total / count) as u8,
(g_total / count) as u8,
(b_total / count) as u8,
255
]));
}
});
output
}
I've also applied Rayon to numerical simulations and data analysis tasks. For example, a Monte Carlo simulation becomes significantly faster with parallel execution:
use rayon::prelude::*;
use rand::Rng;
fn estimate_pi(sample_count: usize) -> f64 {
let in_circle = (0..sample_count)
.into_par_iter()
.map(|_| {
let mut rng = rand::thread_rng();
let x: f64 = rng.gen_range(-1.0..1.0);
let y: f64 = rng.gen_range(-1.0..1.0);
if x*x + y*y <= 1.0 { 1 } else { 0 }
})
.sum::<usize>();
4.0 * (in_circle as f64 / sample_count as f64)
}
fn main() {
let pi_estimate = estimate_pi(10_000_000);
println!("π ≈ {}", pi_estimate);
}
Thread Pool Management
Rayon automatically manages thread pools based on the available CPU cores. However, you can also configure it manually:
use rayon::ThreadPoolBuilder;
fn main() {
// Create a custom thread pool with 4 threads
let pool = ThreadPoolBuilder::new()
.num_threads(4)
.build()
.unwrap();
// Run a computation in the custom pool
pool.install(|| {
(0..1000).into_par_iter()
.map(|i| i * i)
.sum::<i32>()
});
}
This can be useful in environments where you need precise control over resource allocation or when working within larger systems that already manage threading.
Performance Considerations
While Rayon makes parallelism more accessible, achieving optimal performance still requires consideration of several factors:
use rayon::prelude::*;
use std::time::Instant;
fn main() {
// Create a large vector for testing
let data: Vec<i32> = (0..10_000_000).collect();
// Measure sequential performance
let start = Instant::now();
let seq_result: i64 = data.iter()
.map(|&x| x as i64 * x as i64)
.sum();
let seq_duration = start.elapsed();
// Measure parallel performance
let start = Instant::now();
let par_result: i64 = data.par_iter()
.map(|&x| x as i64 * x as i64)
.sum();
let par_duration = start.elapsed();
println!("Sequential: {:?}", seq_duration);
println!("Parallel: {:?}", par_duration);
println!("Speedup: {:.2}x", seq_duration.as_secs_f64() / par_duration.as_secs_f64());
}
In my experience, operations need to be computationally intensive enough to benefit from parallelization. For simple operations on small datasets, the overhead of task distribution might outweigh the benefits.
The ideal workload for Rayon has these characteristics:
- Computationally intensive operations
- Minimal data dependencies between items
- Sufficient data volume to justify parallelization
- Operations that don't require ordering guarantees
Handling Mutable State
While Rayon focuses on data parallelism, sometimes you need to collect or aggregate results. Rayon provides safe approaches for this:
use rayon::prelude::*;
use std::sync::Mutex;
fn main() {
let data = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
// Using fold and reduce for aggregation
let sum: i32 = data.par_iter()
.fold(|| 0, |acc, &x| acc + x)
.reduce(|| 0, |a, b| a + b);
println!("Sum: {}", sum);
// If you need to collect results into a shared structure
let histogram = Mutex::new(vec![0; 11]);
data.par_iter().for_each(|&x| {
let mut hist = histogram.lock().unwrap();
hist[x as usize] += 1;
});
println!("Histogram: {:?}", histogram.lock().unwrap());
}
The pattern of using fold followed by reduce is particularly powerful, as it allows efficient local aggregation before combining results.
Advanced Usage Patterns
As I've worked with Rayon, I've developed several patterns for more complex scenarios:
Custom Thread Pools for Nested Parallelism
use rayon::prelude::*;
fn process_data_chunks(data: &[Vec<i32>]) -> Vec<i32> {
// Outer parallelism processes chunks
data.par_iter().flat_map(|chunk| {
// Inner parallelism processes elements within chunks
chunk.par_iter().map(|&x| x * x).collect::<Vec<_>>()
}).collect()
}
Parallel Collection Building
use rayon::prelude::*;
use std::collections::HashMap;
fn build_index(documents: &[String]) -> HashMap<String, Vec<usize>> {
let intermediate: Vec<(String, usize)> = documents.par_iter()
.enumerate()
.flat_map(|(doc_id, text)| {
// Extract all words from the document
text.split_whitespace()
.map(|word| (word.to_lowercase(), doc_id))
.collect::<Vec<_>>()
})
.collect();
// Convert to HashMap (this part runs sequentially)
let mut index = HashMap::new();
for (word, doc_id) in intermediate {
index.entry(word).or_insert_with(Vec::new).push(doc_id);
}
index
}
Adaptive Chunking
use rayon::prelude::*;
fn compute_with_adaptive_chunking<T: Send>(data: &[T], work_fn: fn(&T) -> u64) -> u64 {
// For very large datasets, we chunk to improve load balancing
if data.len() > 10_000 {
data.par_chunks(1000)
.map(|chunk| chunk.par_iter().map(work_fn).sum::<u64>())
.sum()
} else {
// For smaller datasets, process directly
data.par_iter().map(work_fn).sum()
}
}
Troubleshooting and Common Pitfalls
Through my experience with Rayon, I've encountered several common issues:
Too Fine-Grained Parallelism
use rayon::prelude::*;
use std::time::Instant;
fn main() {
let data = vec![1; 1_000_000];
// Too fine-grained - overhead dominates
let start = Instant::now();
let sum1: i32 = data.par_iter().map(|&x| x + 1).sum();
println!("Fine-grained: {:?}", start.elapsed());
// Better - more work per task
let start = Instant::now();
let sum2: i32 = data.par_chunks(1000)
.map(|chunk| chunk.iter().map(|&x| x + 1).sum::<i32>())
.sum();
println!("Chunked: {:?}", start.elapsed());
assert_eq!(sum1, sum2);
}
Deadlocks with Nested Thread Pools
use rayon::ThreadPoolBuilder;
fn main() {
// This pattern can lead to deadlocks
let pool1 = ThreadPoolBuilder::new().num_threads(2).build().unwrap();
let pool2 = ThreadPoolBuilder::new().num_threads(2).build().unwrap();
pool1.install(|| {
// Using pool2 from within pool1 is risky
pool2.install(|| {
// Some work here
});
});
// Better approach: use a single pool with scope
let pool = ThreadPoolBuilder::new().num_threads(4).build().unwrap();
pool.install(|| {
rayon::scope(|s| {
s.spawn(|_| {
// Task 1
});
s.spawn(|_| {
// Task 2
});
});
});
}
Portability Across Platforms
One of Rayon's strengths is its consistent behavior across different operating systems and hardware configurations. I've deployed Rayon-based applications on Linux, macOS, and Windows with minimal platform-specific concerns.
use rayon::prelude::*;
use std::env;
fn main() {
// Rayon automatically adapts to the available cores
println!("Running on {} logical cores", rayon::current_num_threads());
// You can override with environment variables
if let Ok(threads) = env::var("RAYON_NUM_THREADS") {
println!("User requested {} threads", threads);
}
// Processing is portable across platforms
let result = (1..1_000_000)
.into_par_iter()
.filter(|&n| is_prime(n))
.count();
println!("Found {} prime numbers", result);
}
fn is_prime(n: u32) -> bool {
if n <= 1 { return false; }
if n <= 3 { return true; }
if n % 2 == 0 || n % 3 == 0 { return false; }
let mut i = 5;
while i * i <= n {
if n % i == 0 || n % (i + 2) == 0 { return false; }
i += 6;
}
true
}
Conclusion
Rayon has fundamentally changed how I approach computational problems in Rust. The ability to harness multi-core processing power with minimal code changes and strong safety guarantees makes it a standout library in the concurrent programming landscape.
I'm continually impressed by how Rayon balances simplicity with power, enabling safe parallel programming without the typical complexity. The work-stealing scheduler efficiently adapts to workloads, and the API integrates naturally with Rust's iterator patterns.
Whether you're processing large datasets, performing scientific computing, or building responsive applications, Rayon provides a portable, efficient path to parallelism. Its thoughtful design shows how modern programming languages can make concurrent programming both productive and safe.
As processors continue to add cores rather than clock speed, libraries like Rayon become increasingly important. They allow us to effectively utilize the full capability of our hardware while maintaining code clarity and correctness.
101 Books
101 Books is an AI-driven publishing company co-founded by author Aarav Joshi. By leveraging advanced AI technology, we keep our publishing costs incredibly low—some books are priced as low as $4—making quality knowledge accessible to everyone.
Check out our book Golang Clean Code available on Amazon.
Stay tuned for updates and exciting news. When shopping for books, search for Aarav Joshi to find more of our titles. Use the provided link to enjoy special discounts!
Our Creations
Be sure to check out our creations:
Investor Central | Investor Central Spanish | Investor Central German | Smart Living | Epochs & Echoes | Puzzling Mysteries | Hindutva | Elite Dev | JS Schools
We are on Medium
Tech Koala Insights | Epochs & Echoes World | Investor Central Medium | Puzzling Mysteries Medium | Science & Epochs Medium | Modern Hindutva



