











































































































































































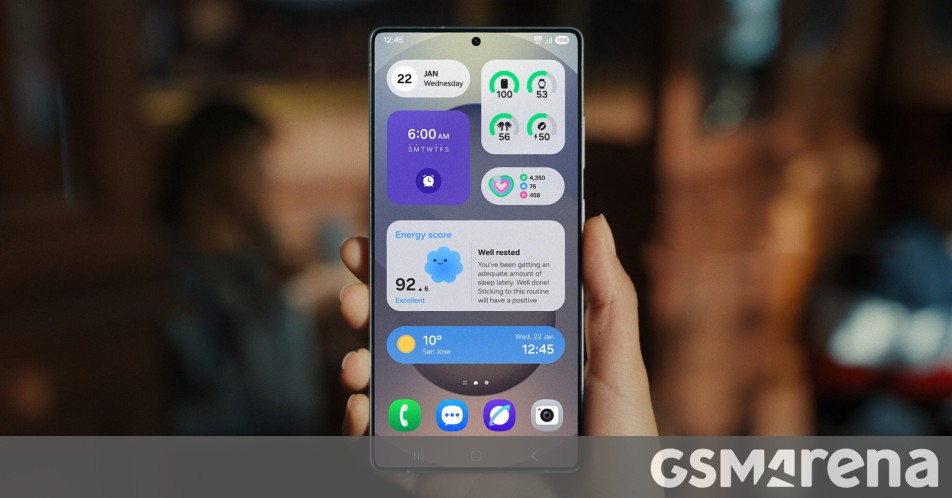
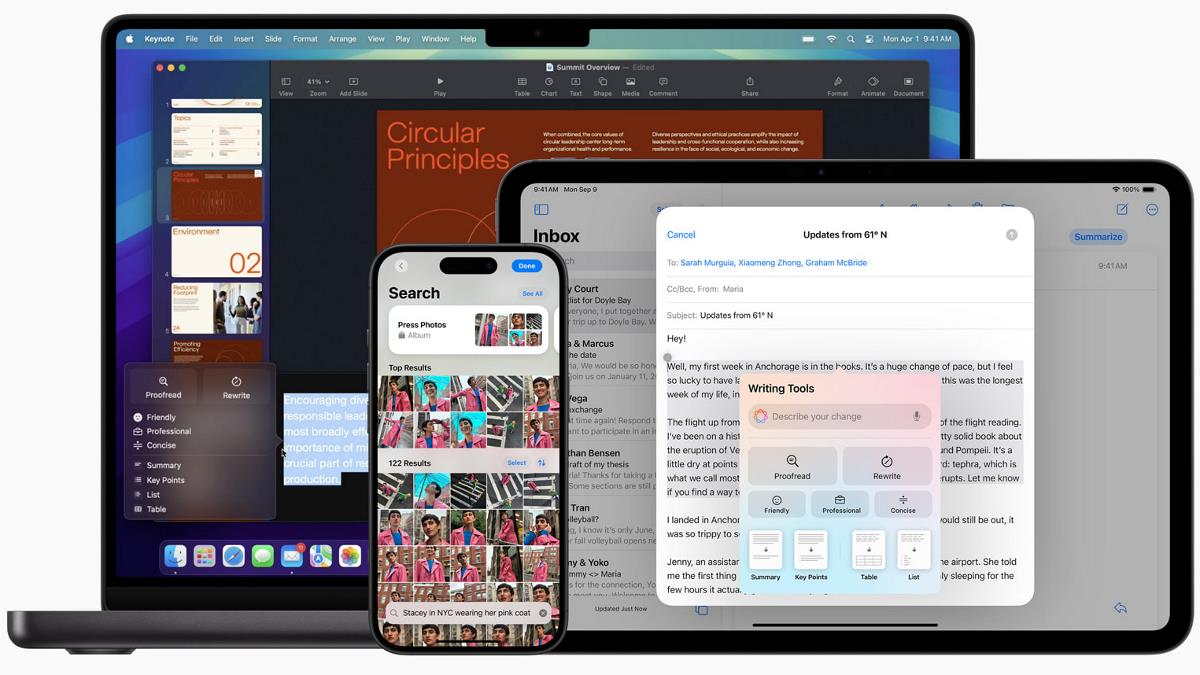
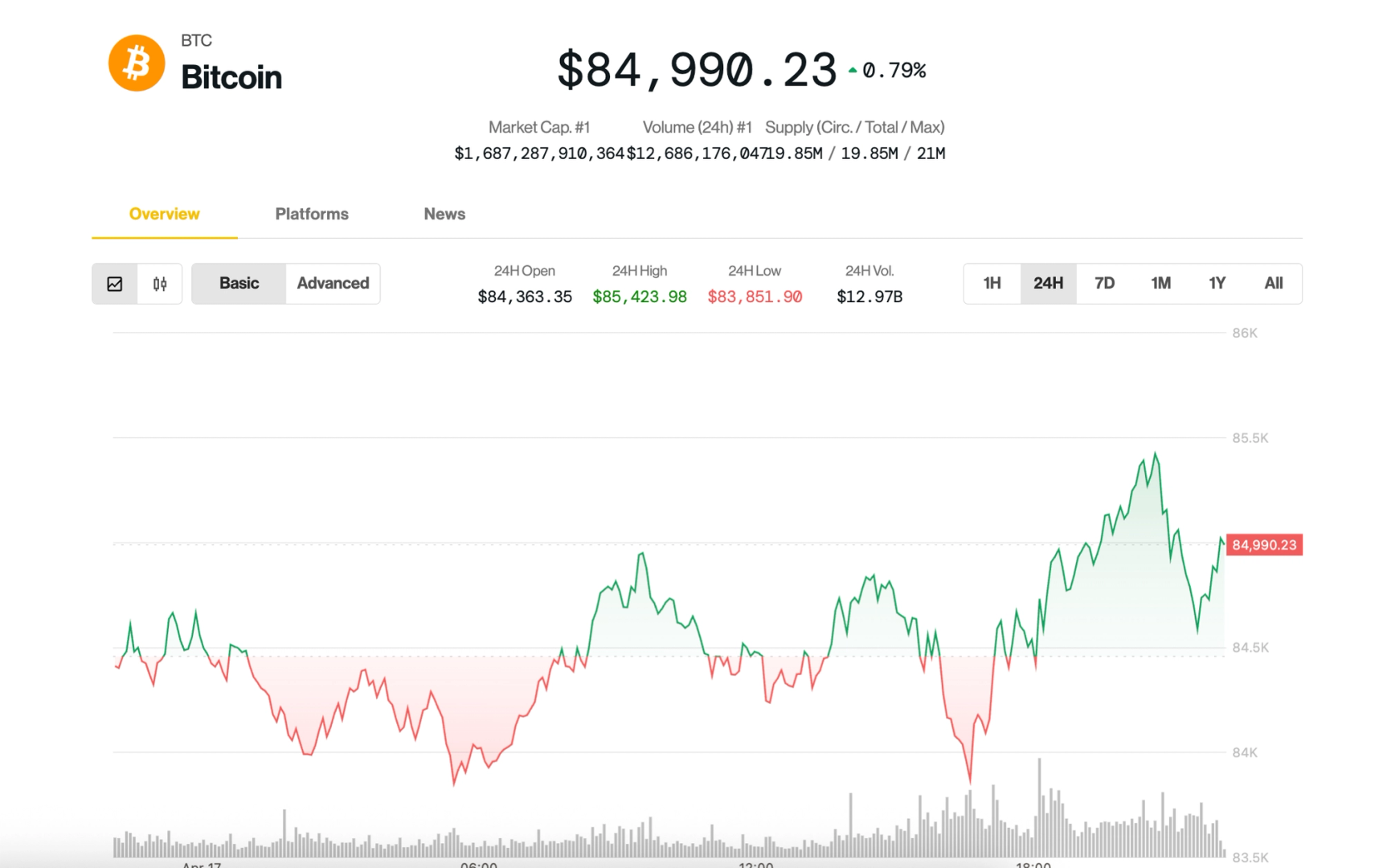
![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)







































































































































































































![GrandChase tier list of the best characters available [April 2025]](https://media.pocketgamer.com/artwork/na-33057-1637756796/grandchase-ios-android-3rd-anniversary.jpg?#)








































































.webp?#)






































































































![New Beats USB-C Charging Cables Now Available on Amazon [Video]](https://www.iclarified.com/images/news/97060/97060/97060-640.jpg)

![Apple M4 13-inch iPad Pro On Sale for $200 Off [Deal]](https://www.iclarified.com/images/news/97056/97056/97056-640.jpg)


























































































































How to Extract Links from a Sitemap
Sitemaps provide an organized map of a website's content, making them invaluable for SEO analysis, content auditing, and web scraping. In this guide, we'll show you how to extract links from a sitemap using Node.js and XML parsing libraries, then demonstrate how CaptureKit API offers a simpler alternative. Method 1: Extracting Sitemap Links with Node.js Sitemaps are XML files that list all the important URLs on a website. To extract links from a sitemap, we'll need to: Find the sitemap URL (usually at /sitemap.xml) Fetch and parse the XML content Extract the links from the parsed XML Here's a complete solution using Node.js with axios and xml2js: import axios from 'axios'; import { parseStringPromise } from 'xml2js'; // Maximum number of links to fetch const MAX_LINKS = 100; // Main function to find and extract sitemap links async function extractSitemapLinks(url) { try { // Step 1: Find the sitemap URL const sitemapUrl = await getSitemapUrl(url); if (!sitemapUrl) { console.log('No sitemap found for this website'); return []; } // Step 2: Fetch links from the sitemap const links = await fetchSitemapLinks(sitemapUrl); return links; } catch (error) { console.error('Error extracting sitemap links:', error); return []; } } // Function to determine the sitemap URL export async function getSitemapUrl(url) { try { const { origin, fullPath } = formatUrl(url); // If the URL already points to an XML file, verify if it's a valid sitemap if (fullPath.endsWith('.xml')) { const isValidSitemap = await verifySitemap(fullPath); return isValidSitemap ? fullPath : null; } // Common sitemap paths to check in order of popularity const commonSitemapPaths = [ '/sitemap.xml', '/sitemap_index.xml', '/sitemap-index.xml', '/sitemaps.xml', '/sitemap/sitemap.xml', '/sitemaps/sitemap.xml', '/sitemap/index.xml', '/wp-sitemap.xml', // WordPress '/sitemap_news.xml', // News specific '/sitemap_products.xml', // E-commerce '/post-sitemap.xml', // Blog specific '/page-sitemap.xml', // Page specific '/robots.txt', // Sometimes sitemap URL is in robots.txt ]; // Try each path in order for (const path of commonSitemapPaths) { // If we're checking robots.txt, we need to extract the sitemap URL from it if (path === '/robots.txt') { try { const robotsUrl = `${origin}${path}`; const robotsResponse = await axios.get(robotsUrl); const robotsContent = robotsResponse.data; // Extract sitemap URL from robots.txt const sitemapMatch = robotsContent.match(/Sitemap:\s*(.+)/i); if (sitemapMatch && sitemapMatch[1]) { const robotsSitemapUrl = sitemapMatch[1].trim(); const isValid = await verifySitemap(robotsSitemapUrl); if (isValid) return robotsSitemapUrl; } } catch (e) { // If robots.txt check fails, continue to the next option continue; } } else { const sitemapUrl = `${origin}${path}`; const isValidSitemap = await verifySitemap(sitemapUrl); if (isValidSitemap) return sitemapUrl; } } return null; } catch (error) { console.error('Error determining sitemap URL:', error); return null; } } // Verify if a URL is a valid sitemap export async function verifySitemap(sitemapUrl) { try { const response = await axios.get(sitemapUrl); const parsedSitemap = await parseStringPromise(response.data); // Check for or tags return Boolean(parsedSitemap.urlset || parsedSitemap.sitemapindex); } catch (e) { console.error(`Invalid sitemap at ${sitemapUrl}`); return false; } } // Format URL to ensure it has proper scheme and structure export function formatUrl(url) { if (!url.startsWith('http')) { url = `https://${url}`; } const { origin, pathname } = new URL(url.replace('http:', 'https:')); return { origin, fullPath: `${origin}${pathname}`.replace(/\/$/, ''), }; } // Fetch and process links from the sitemap export async function fetchSitemapLinks(sitemapUrl, maxLinks = MAX_LINKS) { const links = []; try { const response = await axios.get(sitemapUrl); const sitemapContent = response.data; const parsedSitemap = await parseStringPromise(sitemapContent); // Handle sitemaps with if (parsedSitemap.urlset?.url) { for (const urlObj of parsedSitemap.urlset.url) { try { if (links.length >= maxLinks) break; links.push(urlObj.loc[0]); } catch (e) { console.error('Error parsing sitemap:', e); } } } // Handle nested sitemaps with if (parsedSitemap.sitemapindex?.sitemap) { for (const sitemapObj of parsedSitemap.sitemapindex.sitemap) { try { if (links.length >= maxLinks) break; // Stop pro

Sitemaps provide an organized map of a website's content, making them invaluable for SEO analysis, content auditing, and web scraping. In this guide, we'll show you how to extract links from a sitemap using Node.js and XML parsing libraries, then demonstrate how CaptureKit API offers a simpler alternative.
Method 1: Extracting Sitemap Links with Node.js
Sitemaps are XML files that list all the important URLs on a website. To extract links from a sitemap, we'll need to:
- Find the sitemap URL (usually at
/sitemap.xml) - Fetch and parse the XML content
- Extract the links from the parsed XML
Here's a complete solution using Node.js with axios and xml2js:
import axios from 'axios';
import { parseStringPromise } from 'xml2js';
// Maximum number of links to fetch
const MAX_LINKS = 100;
// Main function to find and extract sitemap links
async function extractSitemapLinks(url) {
try {
// Step 1: Find the sitemap URL
const sitemapUrl = await getSitemapUrl(url);
if (!sitemapUrl) {
console.log('No sitemap found for this website');
return [];
}
// Step 2: Fetch links from the sitemap
const links = await fetchSitemapLinks(sitemapUrl);
return links;
} catch (error) {
console.error('Error extracting sitemap links:', error);
return [];
}
}
// Function to determine the sitemap URL
export async function getSitemapUrl(url) {
try {
const { origin, fullPath } = formatUrl(url);
// If the URL already points to an XML file, verify if it's a valid sitemap
if (fullPath.endsWith('.xml')) {
const isValidSitemap = await verifySitemap(fullPath);
return isValidSitemap ? fullPath : null;
}
// Common sitemap paths to check in order of popularity
const commonSitemapPaths = [
'/sitemap.xml',
'/sitemap_index.xml',
'/sitemap-index.xml',
'/sitemaps.xml',
'/sitemap/sitemap.xml',
'/sitemaps/sitemap.xml',
'/sitemap/index.xml',
'/wp-sitemap.xml', // WordPress
'/sitemap_news.xml', // News specific
'/sitemap_products.xml', // E-commerce
'/post-sitemap.xml', // Blog specific
'/page-sitemap.xml', // Page specific
'/robots.txt', // Sometimes sitemap URL is in robots.txt
];
// Try each path in order
for (const path of commonSitemapPaths) {
// If we're checking robots.txt, we need to extract the sitemap URL from it
if (path === '/robots.txt') {
try {
const robotsUrl = `${origin}${path}`;
const robotsResponse = await axios.get(robotsUrl);
const robotsContent = robotsResponse.data;
// Extract sitemap URL from robots.txt
const sitemapMatch = robotsContent.match(/Sitemap:\s*(.+)/i);
if (sitemapMatch && sitemapMatch[1]) {
const robotsSitemapUrl = sitemapMatch[1].trim();
const isValid = await verifySitemap(robotsSitemapUrl);
if (isValid) return robotsSitemapUrl;
}
} catch (e) {
// If robots.txt check fails, continue to the next option
continue;
}
} else {
const sitemapUrl = `${origin}${path}`;
const isValidSitemap = await verifySitemap(sitemapUrl);
if (isValidSitemap) return sitemapUrl;
}
}
return null;
} catch (error) {
console.error('Error determining sitemap URL:', error);
return null;
}
}
// Verify if a URL is a valid sitemap
export async function verifySitemap(sitemapUrl) {
try {
const response = await axios.get(sitemapUrl);
const parsedSitemap = await parseStringPromise(response.data);
// Check for or tags
return Boolean(parsedSitemap.urlset || parsedSitemap.sitemapindex);
} catch (e) {
console.error(`Invalid sitemap at ${sitemapUrl}`);
return false;
}
}
// Format URL to ensure it has proper scheme and structure
export function formatUrl(url) {
if (!url.startsWith('http')) {
url = `https://${url}`;
}
const { origin, pathname } = new URL(url.replace('http:', 'https:'));
return {
origin,
fullPath: `${origin}${pathname}`.replace(/\/$/, ''),
};
}
// Fetch and process links from the sitemap
export async function fetchSitemapLinks(sitemapUrl, maxLinks = MAX_LINKS) {
const links = [];
try {
const response = await axios.get(sitemapUrl);
const sitemapContent = response.data;
const parsedSitemap = await parseStringPromise(sitemapContent);
// Handle sitemaps with How It Works
This code handles several important aspects of sitemap processing:
-
Sitemap Discovery: It checks multiple common sitemap locations, including
robots.txt. - Sitemap Validation: It verifies that XML files are valid sitemaps by checking for standard sitemap elements.
- Nested Sitemaps: It processes sitemap indexes that point to other sitemaps.
-
Link Extraction: It extracts the
Handling Different Sitemap Types
Sitemaps come in different forms:
-
Standard Sitemaps: These contain a list of URLs in
-
Sitemap Indexes: These contain links to other sitemaps in
- Specialized Sitemaps: Some sites have separate sitemaps for news, products, images, or videos.
Our code handles all these cases by:
- Checking for both
- Recursively processing nested sitemaps
- Limiting the total number of links to avoid memory issues
Method 2: Using CaptureKit API
While the Node.js approach is flexible, it requires handling HTTP requests, XML parsing, error handling, and recursive sitemap traversal. CaptureKit API offers a simpler solution that handles all these complexities for you.
Here's how to use CaptureKit API to extract sitemap data:
curl "https://api.capturekit.dev/content?url=https://example.com&access_key=YOUR_ACCESS_KEY&include_sitemap=true"
The API response includes organized sitemap data along with other useful website information:
{
"success": true,
"data": {
"metadata": {
"title": "Example Website",
"description": "Example website description",
"favicon": "https://example.com/favicon.ico",
"ogImage": "https://example.com/og-image.png"
},
"sitemap": {
"source": "https://example.com/sitemap.xml",
"totalLinks": 150,
"links": [
"https://example.com/",
"https://example.com/page-content",
"https://example.com/ai"
// More links here...
]
}
}
}
Benefits of Using CaptureKit
- Simplicity: One API call instead of dozens of lines of code
- Reliability: Handles all edge cases, redirects, and error conditions
- Performance: Optimized for speed and efficiency
- Additional Data: Get website metadata alongside sitemap information
- No Maintenance: No need to update your code when sitemap formats change
Conclusion
Extracting links from sitemaps is essential for many web scraping and SEO tasks. While our Node.js solution provides a comprehensive approach with full control, CaptureKit API offers a more convenient alternative that handles the complexities for you.
Choose the method that best fits your needs:
- Use the Node.js solution if you need full control over the extraction process
- Use CaptureKit API if you want a quick, reliable solution with minimal code
By leveraging sitemaps, you can efficiently access a website's structure and content without having to crawl every page manually, saving time and resources while ensuring you don't miss important content.


