












































































































































































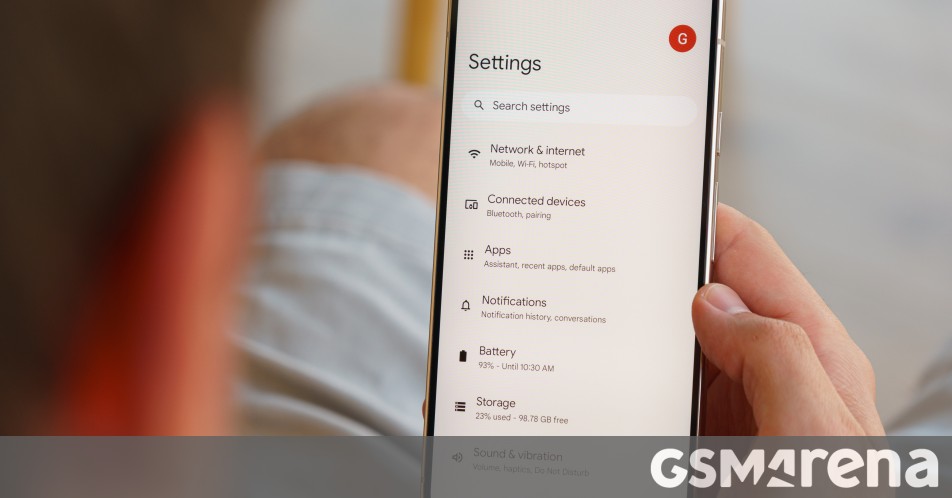
![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)













































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)


































































































.webp?#)


























































































![Here’s the first live demo of Android XR on Google’s prototype smart glasses [Video]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/04/google-android-xr-ted-glasses-demo-3.png?resize=1200%2C628&quality=82&strip=all&ssl=1)













![New Beats USB-C Charging Cables Now Available on Amazon [Video]](https://www.iclarified.com/images/news/97060/97060/97060-640.jpg)

![Apple M4 13-inch iPad Pro On Sale for $200 Off [Deal]](https://www.iclarified.com/images/news/97056/97056/97056-640.jpg)


























































































































DRY (Don't Repeat Yourself): Yazılımda Tekrardan Kaçınmanın Temel İlkesi ve Etkili Uygulama Yöntemleri
Giriş: Yazılımdaki Sessiz Düşman - Tekrar Yazılım geliştirme süreci, karmaşık problemleri çözmek, işlevsellik yaratmak ve kullanıcı ihtiyaçlarını karşılamak üzerine kuruludur. Bu süreçte, geliştiriciler sıklıkla benzer veya aynı mantık parçalarını, veri yapılarını veya yapılandırma bilgilerini kod tabanının farklı yerlerinde kullanma ihtiyacı duyarlar. İlk bakışta, küçük bir kod parçasını kopyalayıp yapıştırmak veya benzer bir mantığı yeniden yazmak en hızlı çözüm gibi görünebilir. Ancak, bu görünüşte zararsız eylem, yazılımın kalitesini, bakımını ve uzun vadeli sağlığını tehdit eden sinsi bir düşmanı besler: Tekrar (Repetition). Kod tekrarı, aynı bilginin veya mantığın birden fazla yerde bulunması durumudur. Bu tekrar, sadece basit kod kopyalama şeklinde olabileceği gibi, aynı işlevi gören ancak farklı şekillerde yazılmış algoritmalar, tekrarlanan yapılandırma değerleri veya tutarsız belgeler şeklinde de ortaya çıkabilir. Tekrarın olduğu yerde, potansiyel sorunlar da filizlenmeye başlar: Bakım Kabusu: Eğer tekrarlanan bir mantıkta bir hata bulunursa veya bir değişiklik yapılması gerekirse, bu mantığın geçtiği her yeri bulup tek tek düzeltmek gerekir. Bir yeri bile gözden kaçırmak, hatalı veya tutarsız davranışlara yol açar. Artan Hata Riski: Manuel olarak yapılan her kopyalama veya yeniden yazma işlemi, hata yapma potansiyelini artırır. Farklı kopyalar zamanla birbirinden farklılaşabilir ve tutarsızlıklar oluşabilir. Şişmiş Kod Tabanı: Tekrarlanan kod, gereksiz yere kod tabanının büyümesine neden olur. Bu, derleme sürelerini uzatabilir, anlaşılabilirliği azaltabilir ve yeni geliştiricilerin sisteme adapte olmasını zorlaştırabilir. Zorlaşan Anlaşılabilirlik: Aynı veya benzer mantığın farklı yerlerde bulunması, kodun genel yapısını ve amacını anlamayı zorlaştırır. Geliştiriciler, hangi versiyonun "doğru" veya "güncel" olduğunu anlamakta zorlanabilirler. İşte bu "sessiz düşman" ile savaşmak için ortaya konmuş temel bir yazılım mühendisliği prensibi vardır: DRY - Don't Repeat Yourself (Kendini Tekrar Etme). Andrew Hunt ve David Thomas tarafından "The Pragmatic Programmer" adlı etkili kitaplarında popülerleştirilen DRY prensibi, yazılım geliştirmenin temel taşlarından biri olarak kabul edilir ve amacı son derece nettir: "Bir sistem içindeki her bilginin tek, belirsiz olmayan, yetkili bir temsili olmalıdır." Bu kapsamlı makalede, DRY prensibinin derinliklerine ineceğiz. DRY'ın sadece kod kopyalamaktan kaçınmak olmadığını, daha geniş anlamda "bilgi tekrarından" kaçınmak anlamına geldiğini açıklayacağız. Bu prensibe uymanın neden bu kadar kritik olduğunu ve sağladığı somut faydaları (bakım kolaylığı, okunabilirlik, daha az hata, tutarlılık) detaylı bir şekilde ele alacağız. Kod tabanımızdaki tekrarı nasıl fark edebileceğimizi (kod kokuları) ve DRY prensibini uygulamak için kullanabileceğimiz pratik teknikleri ve stratejileri (fonksiyonlar, sınıflar, kalıtım, kompozisyon, konfigürasyon yönetimi, veri odaklı yaklaşımlar vb.) inceleyeceğiz. DRY'ın sadece kod için değil, belgeler, testler ve yapılandırmalar gibi diğer alanlar için de geçerli olduğunu göstereceğiz. Ayrıca, her prensipte olduğu gibi, DRY'ı aşırıya kaçırmanın potansiyel tehlikelerini (yanlış soyutlamalar, aşırı karmaşıklık) ve ne zaman tekrara izin vermenin daha mantıklı olabileceğini (WET prensibi bağlamında) tartışacağız. Son olarak, DRY'ın diğer önemli yazılım prensipleriyle (SoC, SRP, KISS, YAGNI) olan ilişkisine değineceğiz. Amacımız, DRY'ın sadece bir slogan olmadığını, aynı zamanda daha temiz, daha verimli, daha sürdürülebilir ve sonuçta daha kaliteli yazılımlar oluşturmak için benimsememiz gereken temel bir düşünce biçimi ve pratikler bütünü olduğunu vurgulamaktır. Bölüm 1: DRY Prensibi Nedir? "Bilginin Tek Temsili" DRY prensibinin tam olarak ne anlama geldiğini kavramak, onu doğru bir şekilde uygulamanın ilk adımıdır. Genellikle "kod tekrarından kaçın" şeklinde basitleştirilse de, DRY'ın özü bundan daha derindir. Temel Tanım: "The Pragmatic Programmer" kitabında belirtildiği gibi, DRY prensibinin temel ifadesi şudur: "Every piece of knowledge must have a single, unambiguous, authoritative representation within a system." (Bir sistem içindeki her bilginin tek, belirsiz olmayan, yetkili bir temsili olmalıdır.) Bu tanımdaki kilit kelime "bilgi" (knowledge)'dir. DRY, sadece aynı kod satırlarının tekrarından değil, aynı kavramsal bilginin veya iş mantığının sistemin farklı yerlerinde yinelenmesinden kaçınmayı hedefler. "Bilgi" Neyi Kapsar? İş Kuralları: Örneğin, bir ürünün minimum sipariş adedi kuralı, bir kullanıcının şifre karmaşıklığı gereksinimi veya bir vergi hesaplama algoritması. Bu kural, sistemin farklı yerlerinde (örneğin, hem kullanıcı arayüzü doğrulaması hem de arka uç servis mantığı) tekrarlanmamalıdır. Algoritmalar: Belirli bir hesaplamayı yapan veya bir süreci yürüten mantıksal adımlar dizisi. Aynı algoritma farklı fonksiyonlarda veya sınıflarda tekrar tekrar yazılmamalıdır. Veri Yapıları: Belirli bir varlığı temsil

Giriş: Yazılımdaki Sessiz Düşman - Tekrar
Yazılım geliştirme süreci, karmaşık problemleri çözmek, işlevsellik yaratmak ve kullanıcı ihtiyaçlarını karşılamak üzerine kuruludur. Bu süreçte, geliştiriciler sıklıkla benzer veya aynı mantık parçalarını, veri yapılarını veya yapılandırma bilgilerini kod tabanının farklı yerlerinde kullanma ihtiyacı duyarlar. İlk bakışta, küçük bir kod parçasını kopyalayıp yapıştırmak veya benzer bir mantığı yeniden yazmak en hızlı çözüm gibi görünebilir. Ancak, bu görünüşte zararsız eylem, yazılımın kalitesini, bakımını ve uzun vadeli sağlığını tehdit eden sinsi bir düşmanı besler: Tekrar (Repetition).
Kod tekrarı, aynı bilginin veya mantığın birden fazla yerde bulunması durumudur. Bu tekrar, sadece basit kod kopyalama şeklinde olabileceği gibi, aynı işlevi gören ancak farklı şekillerde yazılmış algoritmalar, tekrarlanan yapılandırma değerleri veya tutarsız belgeler şeklinde de ortaya çıkabilir. Tekrarın olduğu yerde, potansiyel sorunlar da filizlenmeye başlar:
Bakım Kabusu: Eğer tekrarlanan bir mantıkta bir hata bulunursa veya bir değişiklik yapılması gerekirse, bu mantığın geçtiği her yeri bulup tek tek düzeltmek gerekir. Bir yeri bile gözden kaçırmak, hatalı veya tutarsız davranışlara yol açar.
Artan Hata Riski: Manuel olarak yapılan her kopyalama veya yeniden yazma işlemi, hata yapma potansiyelini artırır. Farklı kopyalar zamanla birbirinden farklılaşabilir ve tutarsızlıklar oluşabilir.
Şişmiş Kod Tabanı: Tekrarlanan kod, gereksiz yere kod tabanının büyümesine neden olur. Bu, derleme sürelerini uzatabilir, anlaşılabilirliği azaltabilir ve yeni geliştiricilerin sisteme adapte olmasını zorlaştırabilir.
Zorlaşan Anlaşılabilirlik: Aynı veya benzer mantığın farklı yerlerde bulunması, kodun genel yapısını ve amacını anlamayı zorlaştırır. Geliştiriciler, hangi versiyonun "doğru" veya "güncel" olduğunu anlamakta zorlanabilirler.
İşte bu "sessiz düşman" ile savaşmak için ortaya konmuş temel bir yazılım mühendisliği prensibi vardır: DRY - Don't Repeat Yourself (Kendini Tekrar Etme). Andrew Hunt ve David Thomas tarafından "The Pragmatic Programmer" adlı etkili kitaplarında popülerleştirilen DRY prensibi, yazılım geliştirmenin temel taşlarından biri olarak kabul edilir ve amacı son derece nettir: "Bir sistem içindeki her bilginin tek, belirsiz olmayan, yetkili bir temsili olmalıdır."
Bu kapsamlı makalede, DRY prensibinin derinliklerine ineceğiz. DRY'ın sadece kod kopyalamaktan kaçınmak olmadığını, daha geniş anlamda "bilgi tekrarından" kaçınmak anlamına geldiğini açıklayacağız. Bu prensibe uymanın neden bu kadar kritik olduğunu ve sağladığı somut faydaları (bakım kolaylığı, okunabilirlik, daha az hata, tutarlılık) detaylı bir şekilde ele alacağız. Kod tabanımızdaki tekrarı nasıl fark edebileceğimizi (kod kokuları) ve DRY prensibini uygulamak için kullanabileceğimiz pratik teknikleri ve stratejileri (fonksiyonlar, sınıflar, kalıtım, kompozisyon, konfigürasyon yönetimi, veri odaklı yaklaşımlar vb.) inceleyeceğiz. DRY'ın sadece kod için değil, belgeler, testler ve yapılandırmalar gibi diğer alanlar için de geçerli olduğunu göstereceğiz. Ayrıca, her prensipte olduğu gibi, DRY'ı aşırıya kaçırmanın potansiyel tehlikelerini (yanlış soyutlamalar, aşırı karmaşıklık) ve ne zaman tekrara izin vermenin daha mantıklı olabileceğini (WET prensibi bağlamında) tartışacağız. Son olarak, DRY'ın diğer önemli yazılım prensipleriyle (SoC, SRP, KISS, YAGNI) olan ilişkisine değineceğiz. Amacımız, DRY'ın sadece bir slogan olmadığını, aynı zamanda daha temiz, daha verimli, daha sürdürülebilir ve sonuçta daha kaliteli yazılımlar oluşturmak için benimsememiz gereken temel bir düşünce biçimi ve pratikler bütünü olduğunu vurgulamaktır.
Bölüm 1: DRY Prensibi Nedir? "Bilginin Tek Temsili"
DRY prensibinin tam olarak ne anlama geldiğini kavramak, onu doğru bir şekilde uygulamanın ilk adımıdır. Genellikle "kod tekrarından kaçın" şeklinde basitleştirilse de, DRY'ın özü bundan daha derindir.
Temel Tanım:
"The Pragmatic Programmer" kitabında belirtildiği gibi, DRY prensibinin temel ifadesi şudur:
"Every piece of knowledge must have a single, unambiguous, authoritative representation within a system."
(Bir sistem içindeki her bilginin tek, belirsiz olmayan, yetkili bir temsili olmalıdır.)
Bu tanımdaki kilit kelime "bilgi" (knowledge)'dir. DRY, sadece aynı kod satırlarının tekrarından değil, aynı kavramsal bilginin veya iş mantığının sistemin farklı yerlerinde yinelenmesinden kaçınmayı hedefler.
"Bilgi" Neyi Kapsar?
İş Kuralları: Örneğin, bir ürünün minimum sipariş adedi kuralı, bir kullanıcının şifre karmaşıklığı gereksinimi veya bir vergi hesaplama algoritması. Bu kural, sistemin farklı yerlerinde (örneğin, hem kullanıcı arayüzü doğrulaması hem de arka uç servis mantığı) tekrarlanmamalıdır.
Algoritmalar: Belirli bir hesaplamayı yapan veya bir süreci yürüten mantıksal adımlar dizisi. Aynı algoritma farklı fonksiyonlarda veya sınıflarda tekrar tekrar yazılmamalıdır.
Veri Yapıları: Belirli bir varlığı temsil eden veri alanları ve bunların ilişkileri (örneğin, bir Musteri nesnesinin yapısı). Bu yapı farklı katmanlarda (veritabanı, iş mantığı, sunum) benzer şekillerde tekrar tanımlanmamalıdır (ancak DTO gibi amaçlı dönüşümler farklıdır).
Sabit Değerler (Constants): "Sihirli sayılar" veya "sihirli string'ler" yerine, belirli anlamları olan sabit değerler (örneğin, KDV oranı, maksimum bağlantı sayısı, bir hata kodu) tek bir yerde tanımlanmalı ve oradan referans alınmalıdır.
Yapılandırma Bilgileri: Veritabanı bağlantı dizeleri, harici servis URL'leri, API anahtarları gibi yapılandırma detayları. Bunlar kodun içine gömülmek yerine merkezi bir yapılandırma kaynağından okunmalıdır.
Belgeleme (Documentation): Bir algoritmanın veya API'nin nasıl çalıştığına dair açıklama. Kodun kendisi ve onunla ilgili belgeler (örneğin, kod içi yorumlar, harici dokümanlar) aynı bilgiyi tutarlı bir şekilde yansıtmalıdır. Bir değişiklik olduğunda her ikisi de güncellenmelidir (idealde, belgeler koddan üretilmelidir).
Test Senaryoları: Benzer test kurulumlarını veya doğrulama mantıklarını tekrarlamak yerine, test yardımcı fonksiyonları veya temel test sınıfları kullanılmalıdır.
DRY vs WET (Write Everything Twice)
DRY prensibinin karşıtı olarak bazen WET (Write Everything Twice - Her Şeyi İki Kez Yaz veya We Enjoy Typing - Yazmaktan Keyif Alırız) kavramından bahsedilir. WET, genellikle DRY'ı aşırıya kaçırmanın tehlikelerine dikkat çekmek veya belirli durumlarda tekrarın kabul edilebilir (hatta gerekli) olabileceğini savunmak için kullanılır (Bölüm 7'de daha detaylı ele alınacak). Ancak temel olarak DRY, verimsizliğe ve hatalara yol açan gereksiz tekrarlardan kaçınmayı hedefler.
Özetle DRY:
DRY, kodun veya bilginin kopyalanıp yapıştırılmasını önlemekten çok daha fazlasıdır. Bir sistemdeki her temel kavramın veya mantığın tek bir kaynaktan yönetilmesini ve diğer tüm parçaların bu tek kaynağa başvurmasını sağlamayı amaçlar. Bu "tek gerçek kaynak" (Single Source of Truth - SSOT) yaklaşımı, sistemin tutarlılığını ve bakımını kolaylaştırmanın anahtarıdır.
Bölüm 2: Neden DRY? Tekrardan Kaçınmanın Somut Faydaları
DRY prensibine uymanın yazılım geliştirme süreci ve ortaya çıkan ürün üzerinde sayısız olumlu etkisi vardır. Bu faydalar, kod kalitesinden geliştirme verimliliğine kadar geniş bir yelpazeyi kapsar.
2.1. Artan Bakım Kolaylığı (Improved Maintainability):
Bu, belki de DRY'ın en önemli faydasıdır.
Nasıl Sağlar? Bir iş kuralı, algoritma veya yapılandırma değeri değiştiğinde, bu değişikliği yapmak için gitmeniz gereken tek bir yer vardır: o bilginin "yetkili temsili". Değişikliği bu tek noktada yaptığınızda, bu bilgiyi kullanan tüm diğer yerler otomatik olarak güncellenmiş olur. Tekrarlanan kodda ise, aynı değişikliği kod tabanındaki potansiyel olarak onlarca veya yüzlerce farklı yerde yapmanız gerekir. Bu hem çok zaman alıcıdır hem de bazı yerleri gözden kaçırma veya yanlış düzeltme riski taşır. DRY, bakım süresini ve maliyetini önemli ölçüde azaltır.
2.2. Azaltılmış Hata Riski (Reduced Risk of Errors):
Tekrar, hataların çoğalması için verimli bir ortam yaratır.
Nasıl Sağlar?
Tutarlılık: Bilgi tek bir yerden geldiği için, sistemin farklı parçalarının aynı konuda farklı veya güncel olmayan bilgilere sahip olma riski ortadan kalkar. Bu, tutarsız davranışları ve hataları önler.
Düzeltme Kolaylığı: Tekrarlanan kodda bir hata bulunduğunda, bu hatanın tüm kopyalarını bulup düzeltmek gerekir. DRY ile hata tek bir yerde düzeltilir ve bu düzeltme her yere yansır. Kopyalayıp yapıştırırken veya yeniden yazarken yapılabilecek manuel hatalar da (örneğin, küçük bir yazım hatası) ortadan kalkar.
2.3. Geliştirilmiş Okunabilirlik ve Anlaşılabilirlik (Improved Readability & Understandability):
DRY prensibine uygun kod genellikle daha temiz, daha kısa ve daha kolay anlaşılır olur.
Nasıl Sağlar? Tekrarlanan kod blokları yerine, iyi isimlendirilmiş fonksiyonlar, metotlar veya sınıflar kullanılır. Bu, kodun amacını daha net bir şekilde ifade eder. Geliştiriciler, belirli bir mantığın nasıl çalıştığını anlamak için sadece ilgili fonksiyonu veya sınıfı inceleyebilirler; aynı mantığın farklı varyasyonlarını farklı yerlerde aramak zorunda kalmazlar. Kod tabanı daha az "gürültülü" hale gelir.
2.4. Daha Hızlı Geliştirme (Potansiyel Olarak) (Potentially Faster Development):
Başlangıçta soyutlama yapmak biraz zaman alsa da, uzun vadede DRY geliştirme sürecini hızlandırabilir.
Nasıl Sağlar?
Yeniden Kullanım: Mevcut fonksiyonları, sınıfları veya modülleri yeniden kullanmak, aynı kodu tekrar tekrar yazmaktan daha hızlıdır.
Daha Az Hata Ayıklama: Daha az hata, hata ayıklamaya harcanan zamanın azalması anlamına gelir.
Daha Hızlı Bakım: Değişikliklerin tek bir yerden yapılması, bakım süreçlerini hızlandırır.
2.5. Tutarlılık (Consistency):
DRY, sistem genelinde tutarlı bir davranış ve görünüm sağlamaya yardımcı olur.
Nasıl Sağlar? Örneğin, tüm tarih formatlama işlemleri tek bir yardımcı fonksiyondan geçiyorsa, uygulama genelinde tarihlerin tutarlı bir şekilde gösterilmesi sağlanır. Benzer şekilde, tüm doğrulama kuralları merkezi bir yerden uygulanıyorsa, kullanıcı deneyimi daha tutarlı olur.
2.6. Daha Küçük Kod Tabanı (Smaller Codebase):
Tekrarlanan kodun ortadan kaldırılması, doğal olarak kod tabanının boyutunu küçültür. Bu, derleme sürelerini kısaltabilir, depolama alanından tasarruf sağlayabilir ve genel sistem karmaşıklığını azaltabilir.
Özetle, DRY prensibi sadece "iyi bir pratik" olmanın ötesinde, yazılımın kalitesini, sürdürülebilirliğini ve geliştirme verimliliğini doğrudan etkileyen temel bir mühendislik ilkesidir. Tekrardan kaçınmak, daha sağlam, daha esnek ve yönetimi daha kolay sistemler oluşturmanın anahtarıdır.
Bölüm 3: Tekrarı Fark Etmek - DRY İhlallerinin İzini Sürmek
DRY prensibini uygulayabilmek için öncelikle kod tabanımızdaki tekrarı fark edebilmemiz gerekir. Tekrar her zaman bariz kod kopyalama şeklinde olmayabilir. İşte yaygın DRY ihlallerini gösteren bazı "kod kokuları" (code smells):
Kopyala-Yapıştır Kodu (Copy-Pasted Code): En bariz ihlaldir. Bir kod bloğunun (birkaç satır veya daha uzun) seçilip, küçük değişikliklerle veya hiç değişiklik yapmadan başka bir yere yapıştırılması. Bu bloklarda bir hata varsa veya mantık değişirse, tüm kopyaları bulup düzeltmek gerekir.
Benzer Mantık Farklı Yerlerde: Tamamen aynı olmasa da, çok benzer adımları izleyen veya aynı temel algoritmayı farklı değişken isimleri veya küçük varyasyonlarla uygulayan kod blokları. Bu durum, ortak mantığın bir fonksiyona veya metoda çıkarılması gerektiğini gösterir.
Paralel Değişiklik İhtiyacı: Bir yerde bir değişiklik yaptığınızda, hemen ardından başka bir veya daha fazla yerde de benzer bir değişiklik yapmanız gerektiğini fark ediyorsanız, bu genellikle altta yatan bir bilginin veya mantığın tekrarlandığının işaretidir.
Sihirli Sayılar ve String'ler (Magic Numbers and Strings): Kodun içine doğrudan gömülmüş, anlamı hemen belli olmayan sayılar veya metinler. Örneğin, if (userStatus == 2) veya borderColor = "#FFC300". Bu değerlerin ne anlama geldiği belirsizdir ve aynı değer farklı yerlerde kullanılıyorsa, değiştirilmesi gerektiğinde tüm kullanımları bulmak zorlaşır. Bunlar, anlamlı isimlere sahip sabitler (constants) olarak tanımlanmalıdır.
Yapısal Tekrar (Structural Duplication): Benzer veri yapıları veya sınıf tanımlarının farklı yerlerde tekrar etmesi. Örneğin, bir veritabanı tablosunu temsil eden bir sınıf ile API yanıtını temsil eden başka bir sınıfın neredeyse aynı alanlara sahip olması (DTO kullanımı bu durumu yönetebilir, ancak gereksiz tekrar olup olmadığına bakılmalıdır).
Paralel Kalıtım Hiyerarşileri: Bir kalıtım hiyerarşisinde değişiklik yaptığınızda (örneğin, yeni bir alt sınıf eklediğinizde), başka bir kalıtım hiyerarşisinde de buna karşılık gelen bir değişiklik yapmanız gerekiyorsa (örneğin, o alt sınıf için bir "fabrika" veya "işleyici" sınıfı eklemek), bu da bir tür tekrarın işareti olabilir (belki farklı bir tasarım deseni daha uygun olabilir).
Açıklama Tekrarı (Comment Duplication): Çok benzer veya aynı açıklamaların farklı kod blokları için tekrar tekrar yazılması. Bu, ya kodun yeterince açık olmadığını ya da ortak bir mantığın soyutlanması gerektiğini gösterebilir. İdealde kod, kendini açıklamalıdır.
Bilgi Çatallanması (Knowledge Forking): Aynı temel bilginin (örneğin, bir iş kuralı) birden fazla yerde farklı şekillerde kodlanması veya ifade edilmesi. Zamanla bu farklı temsiller birbirinden uzaklaşabilir ve tutarsızlığa yol açabilir.
Bu kokuları fark etmek, kod incelemeleri (code reviews) sırasında veya kod yazarken aktif olarak dikkat edilmesi gereken bir konudur. Tekrarı erken aşamada tespit etmek ve refaktör etmek, teknik borcun birikmesini önler.
Bölüm 4: DRY Uygulama Teknikleri - Tekrarı Ortadan Kaldırma Yolları
Tekrarı fark ettikten sonraki adım, onu ortadan kaldırmak için uygun teknikleri kullanmaktır. İşte DRY prensibini uygulamak için yaygın olarak kullanılan bazı yöntemler:
4.1. Fonksiyonlar ve Metotlar (Functions & Methods):
En temel ve en yaygın tekniktir. Tekrarlanan bir kod bloğu fark edildiğinde, bu blok ortak bir fonksiyona veya metoda çıkarılır. Tekrarlanan yerlerde artık bu fonksiyon/metot çağrılır.
Nasıl Uygulanır: Benzer kod bloklarını belirle, ortak mantığı yeni bir fonksiyona taşı, farklılıkları parametreler aracılığıyla fonksiyona geçir, eski kod bloklarını yeni fonksiyon çağrılarıyla değiştir.
Örnek: İki farklı yerde kullanıcı girdisini doğrulayan benzer kod blokları varsa, bu doğrulama mantığı validateUserInput(String input) gibi tek bir fonksiyona taşınır.
4.2. Sınıflar ve Nesne Yönelimli Programlama (Classes & OOP):
OOP, veriyi (alanlar) ve bu veri üzerinde çalışan davranışı (metotlar) sınıflar içinde bir araya getirerek bilginin ve mantığın kapsüllenmesini sağlar.
Nasıl Uygulanır: Belirli bir kavramla (örneğin, Musteri, Siparis) ilgili veri ve işlemler, o kavrama ait tek bir sınıfta toplanır. Bu sınıfın nesneleri, ihtiyaç duyulan yerlerde kullanılır. Bu, müşteri bilgilerini veya sipariş işlemlerini tekrarlamayı önler.
4.3. Kalıtım (Inheritance):
Ortak özelliklere ve davranışlara sahip sınıflar arasında "is-a" ilişkisi varsa, ortak kısımlar bir temel (üst) sınıfta tanımlanabilir ve alt sınıflar bunları miras alabilir.
Nasıl Uygulanır: Ortak alanları ve metotları bir üst sınıfa taşı, alt sınıfları bu üst sınıftan türet (extends).
Dikkat: Kalıtım sıkı bağımlılık yaratabilir. Sadece gerçek "is-a" ilişkisi varsa ve LSP'ye uygunsa dikkatli kullanılmalıdır. (Bkz. Kalıtım vs Kompozisyon)
4.4. Kompozisyon (Composition):
Bir sınıfın, başka sınıfların nesnelerini kullanarak ("has-a" ilişkisi) işlevsellik oluşturmasıdır. Genellikle kalıtıma göre daha esnek bir kod yeniden kullanma yöntemidir.
Nasıl Uygulanır: Tekrarlanan işlevselliği ayrı bir sınıfa (bileşen) taşı. Ana sınıf, bu bileşenin bir örneğini kendi içinde tutar ve ilgili görevleri ona delege eder. Bağımlılık Enjeksiyonu ile birlikte kullanıldığında çok güçlüdür.
Örnek: Farklı sınıflarda benzer loglama mantığı varsa, bu mantık bir Logger sınıfına taşınır ve diğer sınıflar bir Logger nesnesi kullanarak loglama yapar.
4.5. Yardımcı/Araç Sınıfları (Helper/Utility Classes):
Belirli bir alana özgü olmayan, genel amaçlı, tekrarlanan görevler (örneğin, string işleme, tarih formatlama, matematiksel hesaplamalar) genellikle statik metotlar içeren yardımcı sınıflarda toplanır.
Nasıl Uygulanır: Ortak, durumsuz (stateless) fonksiyonları bir Utils veya Helper sınıfı içinde static metotlar olarak tanımla. İhtiyaç duyulan yerlerden StringUtils.isEmpty(str) gibi çağır.
4.6. Sabitler ve Yapılandırma Yönetimi (Constants & Configuration Management):
"Sihirli sayılar" ve "sihirli string'ler" yerine, anlamlı isimlere sahip sabitler (genellikle public static final veya const) tanımlanır ve kullanılır. Uygulama genelindeki yapılandırma değerleri (veritabanı bağlantıları, API URL'leri vb.) kodun içine gömülmek yerine harici yapılandırma dosyalarından (properties, YAML, JSON) veya ortam değişkenlerinden okunur.
Nasıl Uygulanır: Sabitleri merkezi bir sınıfta veya arayüzde tanımla. Yapılandırma değerleri için bir yapılandırma yönetimi mekanizması kullan (framework'lerin genellikle desteği vardır).
4.7. Veri Odaklı Yaklaşımlar (Data-Driven Approaches):
Benzer yapıdaki işlemler veya kurallar, kod içinde ayrı ayrı if-else blokları veya switch case'leri ile tekrarlanmak yerine, bir veri yapısında (örneğin, bir Map, Liste veya veritabanı tablosu) saklanabilir ve bu veri üzerinden genel bir mantık çalıştırılabilir.
Örnek: Farklı kullanıcı tiplerine göre farklı indirim oranları uygulamak için uzun bir if-else zinciri yazmak yerine, kullanıcı tipi ile indirim oranını eşleştiren bir Map kullanmak ve indirim hesaplama fonksiyonunda bu map'ten ilgili oranı almak.
4.8. Şablon Motorları (Templating Engines):
Özellikle UI katmanında (HTML, e-posta vb.) veya kod üretiminde, tekrarlanan yapıları ve metinleri dinamik verilerle birleştirmek için kullanılır. Ortak şablonlar tanımlanır ve değişken kısımlar parametrelerle doldurulur.
Nasıl Uygulanır: Web framework'lerindeki template engine'ler (Thymeleaf, Jinja2, Handlebars), e-posta şablonları, rapor oluşturma araçları.
4.9. Kod Üretimi (Code Generation):
Çok fazla tekrarlayan ve kurala dayalı kod yazılması gereken durumlarda (örneğin, basit CRUD operasyonları için sınıflar oluşturmak, veri modellerinden API kontratları üretmek), kod üreten araçlar kullanılabilir.
Dikkat: Kod üretimi güçlü olabilir ancak dikkatli kullanılmalıdır. Üretilen kodun yönetimi, güncellenmesi ve anlaşılması zorlaşabilir. Genellikle son çare olarak düşünülmelidir.
4.10. Framework'ler ve Kütüphaneler:
İyi tasarlanmış framework'ler ve kütüphaneler, belirli alanlardaki yaygın tekrarlanan görevleri (örneğin, web isteklerini işleme, veritabanı erişimi, kimlik doğrulama) soyutlayarak DRY prensibini uygulamamıza yardımcı olur. Tekerleği yeniden icat etmek yerine mevcut çözümleri kullanmak önemlidir.
Doğru tekniği seçmek, tekrarın doğasına ve bağlama bağlıdır. Amaç her zaman, bilginin veya mantığın tek, yetkili bir temsilini oluşturmak ve diğer yerlerden buna başvurmaktır.
Bölüm 5: DRY Sadece Kod Değildir: Prensibin Geniş Kapsamı
DRY prensibinin gücü, sadece uygulama koduyla sınırlı değildir. Aynı "bilginin tek temsili" fikri, yazılım geliştirme yaşam döngüsünün diğer birçok alanında da geçerlidir ve uygulanmalıdır.
Belgeleme (Documentation):
Tekrar: Bir API'nin nasıl çalıştığı hem kod içi yorumlarda hem de harici bir Wiki sayfasında ayrı ayrı anlatılıyorsa, bir değişiklik olduğunda ikisini de güncellemek gerekir ve tutarsızlık riski doğar.
DRY Yaklaşımı: Belgeleri mümkün olduğunca koddan üretin (örneğin, Javadoc, DocFx, Swagger/OpenAPI kullanarak). Kodun kendisini açık ve anlaşılır yazarak yorum ihtiyacını azaltın. Tek bir merkezi "gerçek kaynak" (örneğin, bir Wiki veya sürüm kontrollü Markdown dosyaları) belirleyin ve diğer tüm referansları oraya yönlendirin.
Testler (Testing):
Tekrar: Farklı test metotlarında aynı test verisi kurulumu (test fixture) veya aynı doğrulama (assertion) mantığı tekrarlanıyorsa.
DRY Yaklaşımı: Ortak kurulum kodunu @BeforeEach/Setup metotlarına taşıyın. Tekrarlanan doğrulama mantığını özel yardımcı (helper) metotlara veya özel assertion sınıflarına çıkarın. Benzer test senaryoları için parametreli testler (parameterized tests) kullanın. Testler için temel sınıflar (base test classes) oluşturarak ortak altyapıyı paylaşın.
Yapılandırma (Configuration):
Tekrar: Aynı veritabanı bağlantı dizesi veya API anahtarı hem geliştirme ortamı yapılandırmasında hem de üretim ortamı yapılandırmasında ayrı ayrı (ve potansiyel olarak farklı) tanımlanıyorsa. Veya aynı değer kodun içine gömülüyorsa.
DRY Yaklaşımı: Ortak yapılandırma değerlerini temel bir dosyada tanımlayın ve ortama özgü değerlerle bunları geçersiz kılın (override). Yapılandırmayı merkezi bir yerden (yapılandırma sunucusu, ortam değişkenleri, yapılandırma dosyaları) yönetin ve kodun bu kaynağa başvurmasını sağlayın.
Veritabanı Şeması (Database Schema):
Tekrar: Aynı bilgi (örneğin, bir müşterinin adresi) birden fazla tabloda normalleştirilmemiş bir şekilde saklanıyorsa.
DRY Yaklaşımı: Veritabanı normalizasyon tekniklerini kullanarak veri tekrarını en aza indirin. Bilgiyi tek bir "yetkili" tabloda saklayın ve diğer tabloların bu tabloya referans vermesini (foreign keys) sağlayın. (Ancak bazen performans nedenleriyle denormalizasyon bilinçli bir tercih olabilir).
Derleme ve Dağıtım Süreçleri (Build & Deployment Scripts):
Tekrar: Farklı ortamlar (geliştirme, test, üretim) için derleme veya dağıtım adımları büyük ölçüde aynıysa ancak küçük farklılıklarla ayrı script'lerde tekrarlanıyorsa.
DRY Yaklaşımı: Ortak adımları parametrelendirilebilir fonksiyonlara veya şablonlara taşıyın. Ortama özgü farklılıkları parametreler veya yapılandırma dosyaları aracılığıyla yönetin. CI/CD (Sürekli Entegrasyon / Sürekli Dağıtım) araçlarının şablonlama ve yeniden kullanılabilir iş akışı özelliklerinden yararlanın.
DRY prensibini geliştirme sürecinin tüm yönlerine uygulamak, genel tutarlılığı artırır, hataları azaltır ve tüm sistemin bakımını kolaylaştırır.
Bölüm 6: Aşırı DRY'laştırmanın Tehlikeleri - Ne Zaman Tekrar Kabul Edilebilir?
Her güçlü prensip gibi, DRY da aşırıya kaçırıldığında veya yanlış anlaşıldığında zararlı olabilir. "Her türlü tekrar kötüdür" şeklindeki katı bir yorum, gereksiz karmaşıklığa ve yanlış soyutlamalara yol açabilir. Buna bazen "Over-DRYing" veya "Yanlış Soyutlama" (Wrong Abstraction) denir.
Aşırı DRY'laştırmanın Riskleri:
Yanlış Soyutlamalar (Wrong Abstractions): Görünüşte benzer olan ancak kavramsal olarak farklı olan iki kod parçasını tek bir soyutlama altında birleştirmeye çalışmak. Bu iki parça gelecekte farklı yönlerde evrilecekse, oluşturulan ortak soyutlama her iki durumu da desteklemek için karmaşıklaşır veya birini kısıtlar. Ayrık kalmaları daha iyi olabilirdi.
Örnek: Hem "Müşteri Adresi" hem de "Tedarikçi Adresi" için tek bir Adres sınıfı kullanmak başlangıçta mantıklı görünebilir. Ancak gelecekte müşteri adresine özel bir alan (örneğin, "Sadakat Puanı Bölgesi") eklenmesi gerekirse, bu alan Tedarikçi Adresi için anlamsız olur ve soyutlama bozulur.
Gereksiz Karmaşıklık (Unnecessary Complexity): Çok küçük veya basit bir tekrarı ortadan kaldırmak için karmaşık bir soyutlama katmanı veya tasarım deseni eklemek. Eklenen soyutlamanın maliyeti (anlaşılabilirlik, bakım yükü), ortadan kaldırılan tekrarın maliyetinden daha fazla olabilir.
Erken Soyutlama (Premature Abstraction): Henüz tam olarak anlaşılmamış veya gelecekte nasıl değişeceği belli olmayan bir kod parçası için hemen soyutlama yapmaya çalışmak. Bu genellikle yanlış soyutlamalara yol açar.
Bağlam Kaybı (Loss of Context): Kod aşırı derecede küçük fonksiyonlara veya sınıflara bölündüğünde, belirli bir işlevin genel bağlamını ve akışını takip etmek zorlaşabilir.
Ne Zaman Tekrar Kabul Edilebilir? (WET Olmanın Yeri)
Bazı durumlarda, küçük miktarda tekrar, yanlış bir soyutlamadan daha iyi olabilir:
AHA Prensibi (Avoid Hasty Abstractions - Aceleci Soyutlamalardan Kaçın): Sandi Metz tarafından popülerleştirilen bu yaklaşım, bir soyutlama yapmadan önce kodun farklı bağlamlarda nasıl kullanılacağını veya nasıl değişeceğini daha iyi anlamayı önerir. Yanlış soyutlama yapmaktansa, başlangıçta biraz tekrar olmasına izin vermek daha iyi olabilir.
Üç Kuralı (Rule of Three): Bir kod parçasını veya mantığı ilk kez yazdığınızda, sadece yazın. İkinci kez benzer bir şeye ihtiyaç duyduğunuzda, tekrar etmeye direnin ama yine de kopyalayabilirsiniz. Ancak üçüncü kez ihtiyaç duyduğunuzda, bu artık bir desen olduğunu gösterir ve soyutlama yapma (refaktör etme) zamanı gelmiştir. Bu kural, erken soyutlamayı önlemeye yardımcı olur.
Farklı Bağlamlar (Different Contexts): İki kod parçası görünüşte aynı olsa bile, farklı iş bağlamlarına veya farklı değişim nedenlerine hizmet ediyorlarsa, onları birleştirmek yerine ayrı tutmak daha mantıklı olabilir (SRP ile ilgilidir). Örneğin, iki farklı modüldeki benzer doğrulama kodu, gelecekte farklı kurallara tabi olabilir.
Okunabilirlik: Çok karmaşık bir soyutlama yerine, basit ve kendini açıklayan küçük bir tekrar bazen daha okunabilir olabilir (ancak bu nadir bir durumdur ve dikkatli değerlendirilmelidir).
Denge Anahtardır: DRY prensibi körü körüne uygulanmamalıdır. Amaç, gereksiz ve zararlı tekrardan kaçınmaktır. Tekrarı ortadan kaldırmak için yapılacak soyutlamanın getireceği fayda, maliyetinden (karmaşıklık, potansiyel yanlışlık) daha fazla olmalıdır. Deneyim ve bağlamı değerlendirme yeteneği, doğru dengeyi bulmada kritik rol oynar.
Bölüm 7: DRY ve Diğer Yazılım Prensipleri Arasındaki İlişki
DRY, diğer birçok temel yazılım tasarım prensibiyle yakından ilişkilidir ve genellikle onları destekler veya onlarla birlikte çalışır:
SoC (Separation of Concerns - Sorumlulukların Ayrılması): SoC, sistemi farklı sorumluluk alanlarına ayırmayı hedefler. DRY, belirli bir sorumluluğa (bilgiye veya mantığa) ait kodun tek bir yerde toplanmasını sağlayarak SoC'yi destekler. Örneğin, tüm veritabanı erişim mantığını tek bir Veri Erişim Katmanı'nda toplamak hem SoC hem de DRY uygulamasıdır.
SRP (Single Responsibility Principle - Tek Sorumluluk Prensibi): Bir sınıfın değişmek için tek bir nedeni olması gerektiğini söyler. DRY, bir bilginin veya mantığın tek bir yetkili temsilini savunarak, o bilginin veya mantığın değişmesi gerektiğinde sadece tek bir yerin (ve dolayısıyla genellikle tek bir sınıfın veya modülün) değiştirilmesini teşvik eder. Bu, SRP'ye ulaşmaya yardımcı olur.
KISS (Keep It Simple, Stupid - Basit Tut Aptalca): Mümkün olduğunca basit tasarımları hedefler. DRY, gereksiz tekrarları ortadan kaldırarak kod tabanını basitleştirmeye yardımcı olur. Ancak aşırı DRY'laştırma KISS prensibini ihlal edebilir (gereksiz karmaşıklık yaratarak).
YAGNI (You Ain't Gonna Need It - Ona İhtiyacın Olmayacak): Şu an gerekmeyen işlevselliği veya soyutlamayı eklememeyi öğütler. DRY uygularken yapılan soyutlamaların YAGNI prensibine aykırı olmamasına dikkat etmek gerekir. Yani, soyutlamayı sadece gelecekte belki ihtiyaç duyulur diye değil, mevcut veya makul ölçüde öngörülebilir bir tekrarı çözmek için yapmak gerekir.
Bu prensipler genellikle birbirini tamamlar ve birlikte kullanıldıklarında daha sağlam, esnek ve bakımı kolay yazılımlar ortaya çıkar.
Sonuç: DRY - Temiz Kodun ve Sürdürülebilirliğin DNA'sı
DRY (Don't Repeat Yourself) prensibi, yazılım geliştirmenin temel direklerinden biridir. "Her bilginin tek, belirsiz olmayan, yetkili bir temsili olması gerektiği" fikri, sadece kod tekrarını önlemekten öte, sistemlerimizin tutarlılığını, bakımını ve anlaşılabilirliğini temelden iyileştiren güçlü bir yaklaşımdır.
Tekrarın olduğu yerde hatalar gizlenir, bakım zorlaşır ve kod tabanı gereksiz yere şişer. DRY prensibini benimseyerek, bu sorunları kaynağında çözmeyi hedefleriz. Fonksiyonlar, sınıflar, kompozisyon, yapılandırma yönetimi gibi çeşitli tekniklerle tekrarı ortadan kaldırarak daha temiz, daha modüler ve daha sağlam kodlar yazarız. Bu prensibin sadece uygulama koduyla sınırlı olmadığını; belgelerden testlere, yapılandırmadan veritabanı şemalarına kadar geliştirme sürecinin birçok alanında geçerli olduğunu unutmamak gerekir.
Ancak DRY, körü körüne uygulanacak bir dogma değildir. Aşırıya kaçıldığında, yanlış soyutlamalara ve gereksiz karmaşıklığa yol açabilir. Doğru dengeyi bulmak, bağlamı anlamak, "Üç Kuralı" gibi pratik rehberleri kullanmak ve soyutlamanın maliyetini ve faydasını dikkatlice tartmak önemlidir. Bazen küçük bir tekrar, yanlış bir soyutlamadan daha iyi olabilir.
Nihayetinde DRY, sadece bir teknikler listesi değil, bir düşünce biçimidir. Kod yazarken veya tasarlarken sürekli olarak "Bu bilgiyi veya mantığı daha önce başka bir yerde ifade ettim mi?" ve "Bunun tek, yetkili bir kaynağı var mı?" diye sormaktır. Bu zihniyeti benimsemek, bizi doğal olarak daha iyi tasarım kararları almaya ve yazılım mühendisliği zanaatımızı geliştirmeye yönlendirir. DRY, temiz kodun DNA'sıdır ve sürdürülebilir, kaliteli yazılımlar oluşturma yolculuğumuzda bize rehberlik eden temel bir ışıktır.
Abdulkadir Güngör - Kişisel WebSite
Abdulkadir Güngör - Kişisel WebSite
Abdulkadir Güngör - Özgeçmiş
Github
Linkedin


