













































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)






























































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)












































































































.png?#)

































_Christophe_Coat_Alamy.jpg?#)
 (1).webp?#)





































































































![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)






























































































































Comparing Execution Plans: MongoDB vs. Compatible APIs
MongoDB is the standard API for document databases, and some cloud providers have created services with a similar API. AWS and Azure call theirs 'DocumentDB', and Oracle provides the MongoDB API as a proxy on top of its SQL database. These databases offer a subset of features from past versions of MongoDB, but user experience and performance are also crucial. Oracle claims better performance, and I will use it to compare the execution plans to see which one minimizes unnecessary reads. TL;DR: MongoDB has better performance, and more indexing possibilities. Document Model (Order - Order Detail) I used a simple schema of orders and order lines, ideal for a document model. I illustrated it with UML notation to distinguish strong and weak entities, representing the association as a composition (⬧-). In a SQL database, a one-to-many relationship between orders and line items requires two tables. In MongoDB, a composition relationship allows the weak entity (Order Detail) to be embedded within the strong entity (Order) as an array, simplifying data management and enhancing performance, as we will see when indexing it. I will insert orders with few attributes. The country and creation date are fields in Order. The line number, product, and quantity are fields of Detail, which is an embedded array in Order: +--------------------------+ | Order | +--------------------------+ | country_id: Number | | created_at: Date | | details: Array | | +----------------------+ | | | Detail | | | +----------------------+ | | | line: Number | | | | product_id: Number | | | | quantity: Number | | | +----------------------+ | +--------------------------+ Sample Data I generated one million documents for my example. I'll focus on predictable metrics like the number of documents examined rather than execution time, so that it can be easily reproduced with a small dataset. To simulate products with fluctuating popularity, I use a randomized logarithmic value to create product IDs: const bulkOps = []; for (let i = 0; i print( ... db.orders.find( { ... country_id: 1, ... order_details: { $elemMatch: { product_id: 5 } } ... }).sort({ created_at: -1 }).limit(10) ... .explain("executionStats").executionStats ... ); { executionSuccess: true, nReturned: 10, executionTimeMillis: 0, totalKeysExamined: 10, totalDocsExamined: 10, executionStages: { isCached: false, stage: 'LIMIT', nReturned: 10, executionTimeMillisEstimate: 0, works: 11, advanced: 10, needTime: 0, needYield: 0, saveState: 0, restoreState: 0, isEOF: 1, limitAmount: 10, inputStage: { stage: 'FETCH', filter: { order_details: { '$elemMatch': { product_id: { '$eq': 5 } } } }, nReturned: 10, executionTimeMillisEstimate: 0, works: 10, advanced: 10, needTime: 0, needYield: 0, saveState: 0, restoreState: 0, isEOF: 0, docsExamined: 10, alreadyHasObj: 0, inputStage: { stage: 'IXSCAN', nReturned: 10, executionTimeMillisEstimate: 0, works: 10, advanced: 10, needTime: 0, needYield: 0, saveState: 0, restoreState: 0, isEOF: 0, keyPattern: { country_id: 1, 'order_details.product_id': 1, created_at: -1 }, indexName: 'country_id_1_order_details.product_id_1_created_at_-1', isMultiKey: true, multiKeyPaths: { country_id: [], 'order_details.product_id': [ 'order_details' ], created_at: [] }, isUnique: false, isSparse: false, isPartial: false, indexVersion: 2, direction: 'forward', indexBounds: { country_id: [ '[1, 1]' ], 'order_details.product_id': [ '[5, 5]' ], created_at: [ '[MaxKey, MinKey]' ] }, keysExamined: 10, seeks: 1, dupsTested: 10, dupsDropped: 0 } } } } Here MongoDB didn't read more rows than necessary: Index scan (stage: 'IXSCAN') with a single access (seeks: 1) to the values of the equality condition. Read only the ten index entries (keysExamined: 10) needed for the result. No sort operation, the ten documents (nReturned: 10) are read (stage: 'FETCH') sorted on the index key. This is summarized by: executionSuccess: true, nReturned: 10, totalKeysExamined: 10, totalDocsExamined: 10, When the number of keys examined matches the number of documents returned, it indicates optimal execution with no unnecessary operations. This alignment ensures efficiency in processing, as all examined keys are relevant to the returned documents. You can also l
MongoDB is the standard API for document databases, and some cloud providers have created services with a similar API. AWS and Azure call theirs 'DocumentDB', and Oracle provides the MongoDB API as a proxy on top of its SQL database. These databases offer a subset of features from past versions of MongoDB, but user experience and performance are also crucial.
Oracle claims better performance, and I will use it to compare the execution plans to see which one minimizes unnecessary reads.
TL;DR: MongoDB has better performance, and more indexing possibilities.
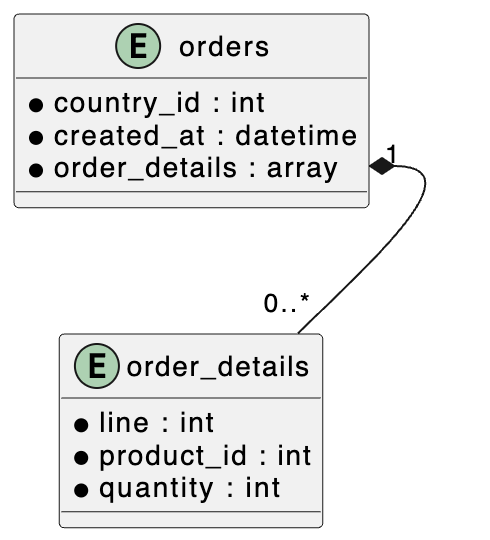
Document Model (Order - Order Detail)
I used a simple schema of orders and order lines, ideal for a document model. I illustrated it with UML notation to distinguish strong and weak entities, representing the association as a composition (⬧-).
In a SQL database, a one-to-many relationship between orders and line items requires two tables. In MongoDB, a composition relationship allows the weak entity (Order Detail) to be embedded within the strong entity (Order) as an array, simplifying data management and enhancing performance, as we will see when indexing it.
I will insert orders with few attributes. The country and creation date are fields in Order. The line number, product, and quantity are fields of Detail, which is an embedded array in Order:
+--------------------------+
| Order |
+--------------------------+
| country_id: Number |
| created_at: Date |
| details: Array |
| +----------------------+ |
| | Detail | |
| +----------------------+ |
| | line: Number | |
| | product_id: Number | |
| | quantity: Number | |
| +----------------------+ |
+--------------------------+
Sample Data
I generated one million documents for my example. I'll focus on predictable metrics like the number of documents examined rather than execution time, so that it can be easily reproduced with a small dataset. To simulate products with fluctuating popularity, I use a randomized logarithmic value to create product IDs:
const bulkOps = [];
for (let i = 0; i < 1000000; i++) {
const orderDetails = [];
for (let line = 1; line <= 10; line++) {
orderDetails.push({
line: line,
product_id: Math.floor(Math.log2(1 + i * Math.random())),
quantity: Math.floor(100 * Math.random()),
});
}
bulkOps.push({
insertOne: {
document: {
country_id: Math.floor(10 * Math.random()),
created_at: new Date(),
order_details: orderDetails
}
}
});
}
db.orders.bulkWrite(bulkOps).insertedCount;
Access Pattern and ESR Index
Users seek insights into product usage through a query for the most recent orders that include a specific product, in a specific country. Following the ESR rule, I created an index with equality fields in front of the key, followed by the fields for ordering results.
db.orders.createIndex( {
"country_id": 1,
"order_details.product_id": 1,
"created_at": -1
});
Query the 10 last orders for a product / country
I queried the ten last orders in country 1 including product 5:
print(
db.orders.find({
country_id: 1,
order_details: { $elemMatch: { product_id: 5 } }
}).sort({ created_at: -1 }).limit(10)
);
Here was the result:
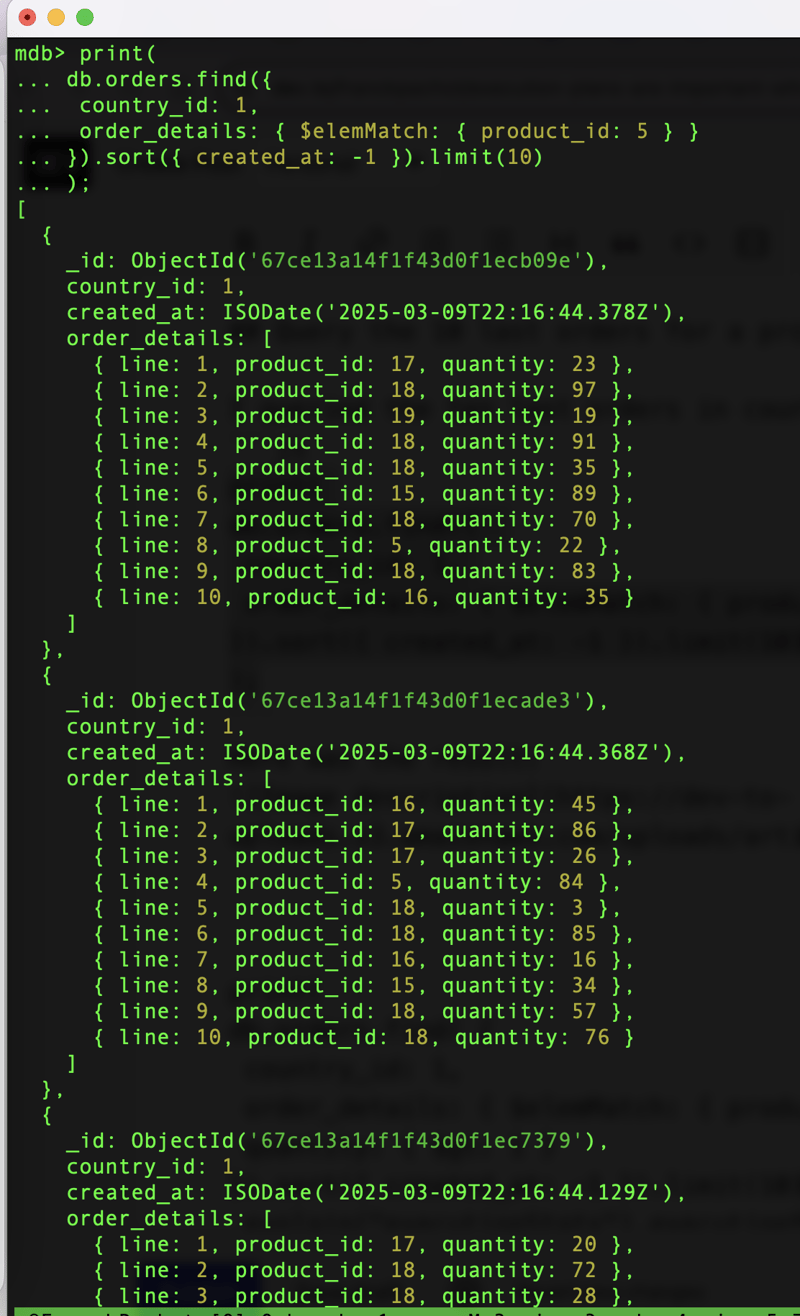
The user can analyze those orders to understand the last order for this product.
Execution plan for MongoDB API on Oracle Database
I query the execution plan for this query:
print(
db.orders.find( {
country_id: 1,
order_details: { $elemMatch: { product_id: 5 } }
}).sort({ created_at: -1 }).limit(10)
.explain("executionStats")
);
When using the "MongoDB API for Oracle Database," the query is re-written to SQL since the collection resides in SQL tables with OSON data type, employing internal functions to simulate MongoDB BSON document. The explain() method reveals the executed queries:
Unfortunately, this does not show execution statistics.
To gain more insights, I gathered the SQL statement from V$SQL and ran it with the MONITOR hint to generate a SQL Monitor report:
select /*+ FIRST_ROWS(10) MONITOR */ "DATA",rawtohex("RESID"),"ETAG"
from "ORA"."orders"
where JSON_EXISTS("DATA"
,'$?( (@.country_id.numberOnly() == $B0) &&
( exists(@.order_details[*]?( (@.product_id.numberOnly() == $B1) )) ) )' passing 1 as "B0", 5 as "B1" type(strict))
order by JSON_QUERY("DATA", '$.created_at[*].max()') desc nulls last
fetch next 10 rows only
;
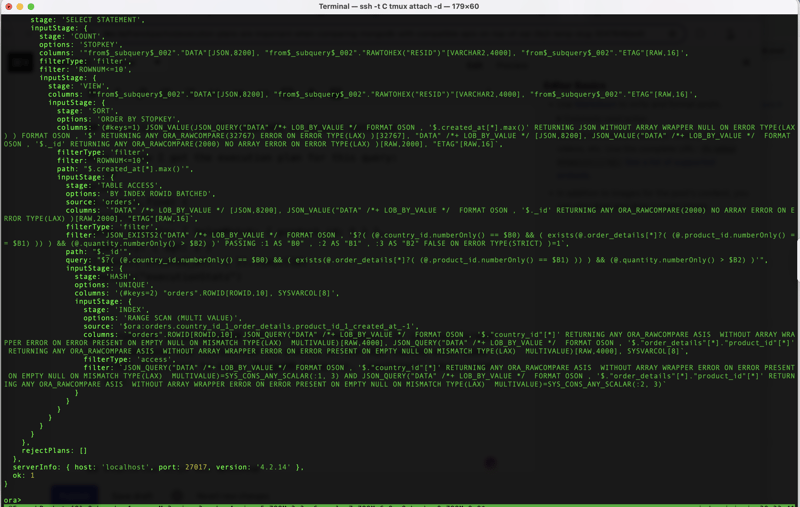
Here is the SQL Monitor report:
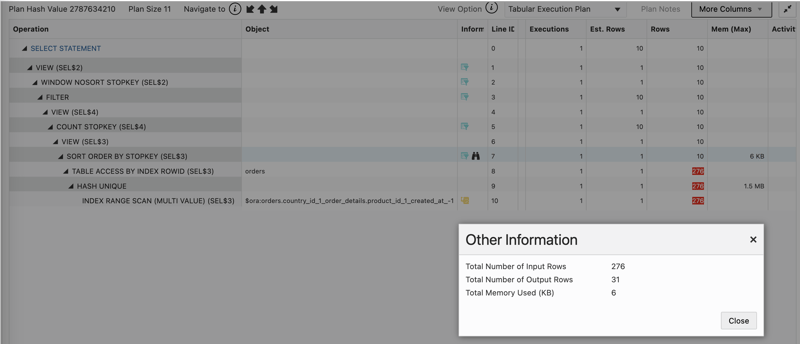
- 276 rows have been read from the index (INDEX RANGE SCAN). The access predicates are internal virtual columns for the equality conditions: "orders"."SYS_NC00005$" = SYS_CONS_ANY_SCALAR(1, 3) AND "orders"."SYS_NC00006$" = SYS_CONS_ANY_SCALAR(5, 3).
- They are deduplicated (HASH UNIQUE).
- 276 documents are fetched (TABLE ACCESS BY ROWID).
- They are sorted for Top-k (SORT ORDER BY STOPKEY) to return 31 documents, from which 10 are fetched.
More operations occur to transform it into MongoDB-compatible documents, but this happens on 10 documents as it occurs after the limit (COUNT STOPKEY). What is problematic is what happens before, on rows that are not needed to get the result.
The index usage does not follow the MongoDB ESR (Equality, Sort, Range) rule. Index scan was used only to filter on the equality predicates, country_id and product_id. Having created_at next to them was useless and didn't help to avoid a blocking sort operation.
The result from Oracle Database is compatible with MongoDB, but the performance and scalability is not.
Execution plan for MongoDB
Here is the execution plan on a real MongoDB database - I've run it on an Atlas free cluster:
db> print(
... db.orders.find( {
... country_id: 1,
... order_details: { $elemMatch: { product_id: 5 } }
... }).sort({ created_at: -1 }).limit(10)
... .explain("executionStats").executionStats
... );
{
executionSuccess: true,
nReturned: 10,
executionTimeMillis: 0,
totalKeysExamined: 10,
totalDocsExamined: 10,
executionStages: {
isCached: false,
stage: 'LIMIT',
nReturned: 10,
executionTimeMillisEstimate: 0,
works: 11,
advanced: 10,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
limitAmount: 10,
inputStage: {
stage: 'FETCH',
filter: {
order_details: { '$elemMatch': { product_id: { '$eq': 5 } } }
},
nReturned: 10,
executionTimeMillisEstimate: 0,
works: 10,
advanced: 10,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 0,
docsExamined: 10,
alreadyHasObj: 0,
inputStage: {
stage: 'IXSCAN',
nReturned: 10,
executionTimeMillisEstimate: 0,
works: 10,
advanced: 10,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 0,
keyPattern: {
country_id: 1,
'order_details.product_id': 1,
created_at: -1
},
indexName: 'country_id_1_order_details.product_id_1_created_at_-1',
isMultiKey: true,
multiKeyPaths: {
country_id: [],
'order_details.product_id': [ 'order_details' ],
created_at: []
},
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: {
country_id: [ '[1, 1]' ],
'order_details.product_id': [ '[5, 5]' ],
created_at: [ '[MaxKey, MinKey]' ]
},
keysExamined: 10,
seeks: 1,
dupsTested: 10,
dupsDropped: 0
}
}
}
}
Here MongoDB didn't read more rows than necessary:
- Index scan (
stage: 'IXSCAN') with a single access (seeks: 1) to the values of the equality condition. - Read only the ten index entries (
keysExamined: 10) needed for the result. - No sort operation, the ten documents (nReturned: 10) are read (stage: 'FETCH') sorted on the index key.
This is summarized by:
executionSuccess: true,
nReturned: 10,
totalKeysExamined: 10,
totalDocsExamined: 10,
When the number of keys examined matches the number of documents returned, it indicates optimal execution with no unnecessary operations.
This alignment ensures efficiency in processing, as all examined keys are relevant to the returned documents.
You can also look at the visual execution plan in MongoDB Compass:
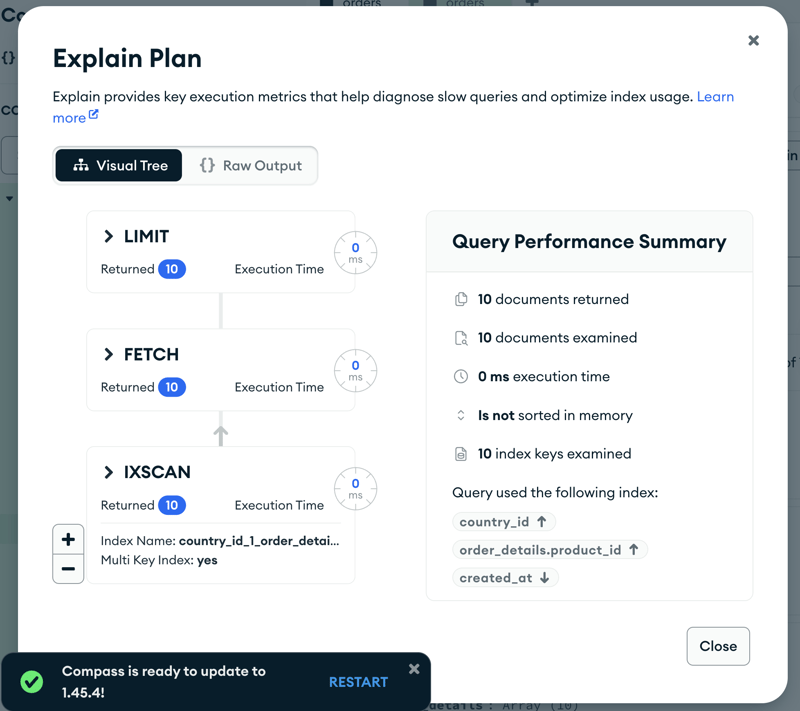
Using document data modeling and MongoDB indexes allows you to access only the necessary data, ensuring that query costs are directly related to the results obtained.
Conclusion on Documents (vs. relational) and MongoDB (vs. emulations)
In a SQL database, the Orders - Order Details example requires two tables and a join to filter results. The join itself may not be too expensive, but SQL databases lack multi-table indexes. They do unnecessary work reading and joining rows that will be discarded later.
The document model, with embedded entities, allows for comprehensive indexing, offering optimal access unlike normalized tables in relational databases. MongoDB shines with indexes that follow Equality, Sort, and Range, and they can cover documents and sub-documents, with multiple keys per document.
While some SQL databases have copied the MongoDB API for its user-friendly experience, they do not gain the same benefits as MongoDB, provide fewer indexing possibilities, and incur additional operations when executing queries.



