












































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.png?#)

































_Christophe_Coat_Alamy.jpg?#)
 (1).webp?#)






































































































![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)
![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)





























































































































AI System Makes Breakthrough in Understanding Images and Text Like Humans Do
This is a Plain English Papers summary of a research paper called AI System Makes Breakthrough in Understanding Images and Text Like Humans Do. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Overview R1-Onevision is a multimodal AI system that integrates vision and language Uses a cross-modal reasoning pipeline to standardize reasoning across modalities Introduces "Language-As-Attention" (LAA) to convert linguistic reasoning into visual attention Achieves state-of-the-art performance on diverse multimodal reasoning tasks Demonstrates strong generalization to unseen reasoning tasks and domains Plain English Explanation R1-Onevision tackles a fundamental problem in AI: how to make machines think about text and images in the same way humans do. Current multimodal AI systems often handle text and... Click here to read the full summary of this paper
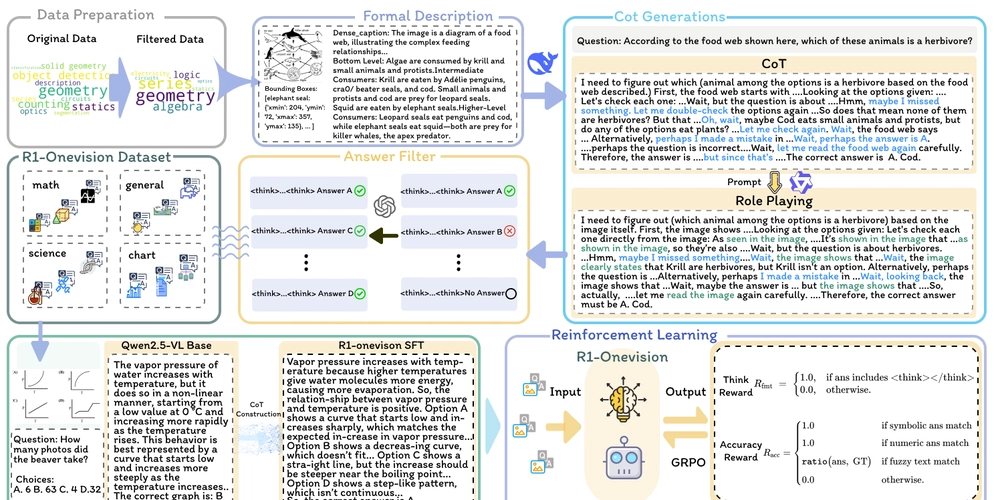
This is a Plain English Papers summary of a research paper called AI System Makes Breakthrough in Understanding Images and Text Like Humans Do. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- R1-Onevision is a multimodal AI system that integrates vision and language
- Uses a cross-modal reasoning pipeline to standardize reasoning across modalities
- Introduces "Language-As-Attention" (LAA) to convert linguistic reasoning into visual attention
- Achieves state-of-the-art performance on diverse multimodal reasoning tasks
- Demonstrates strong generalization to unseen reasoning tasks and domains
Plain English Explanation
R1-Onevision tackles a fundamental problem in AI: how to make machines think about text and images in the same way humans do. Current multimodal AI systems often handle text and...



