













































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)






























































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.png?#)


































_Christophe_Coat_Alamy.jpg?#)


.webp?#)






































































































![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)
![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)





























































































































AI-Powered Web Scraping: Unlocking Next-Generation Insights
In a data-intensive environment, the ability to gather and interpret information from the web is critical for many organizations. Traditional web scraping—once a primary method of obtaining online data—now struggles with increasingly dynamic site structures and anti-automation strategies. AI offers a more adaptive, learning-oriented approach that responds to shifts in web content and reveals insights where conventional methods fall short. Why AI Matters in Web Scraping Web scraping has traditionally relied on fixed rules or selector-based parsing to collect data. As websites become more interactive and frequently modify their structures, these rigid methods often fail. Some common obstacles include: Frequent DOM Changes: Sites update their layouts regularly, breaking scrapers that rely on specific HTML element selectors. JavaScript-Heavy Content: Traditional scrapers may not capture asynchronously loaded or user-triggered content. Dynamic Interactions: Pop-ups, infinite scrolling, or multi-step forms can require more advanced navigation strategies. Incorporating AI can help address these issues by making scrapers more adaptive. Through techniques like Natural Language Processing and Computer Vision, an AI-enhanced approach can parse textual meaning, recognize on-page elements, and handle dynamic content more reliably. This reduces the need for frequent manual updates while allowing for deeper, more insightful data extraction. How AI Overcomes These Obstacles: Before & After To understand the leap from rule-based to AI-powered scraping, let’s visualize a simple before-and-after scenario. Before: Rule-Based Scrapers Brittle Selectors: If a website changes minor HTML tags or rearranges containers, your scraper likely breaks. Surface-Level Data: Text-based matches capture only explicit elements; interactive or visually-embedded data remains untouched. High Maintenance: Developers must constantly update code, dealing with recurring site changes. After: AI-Powered Scrapers Adaptive Learning: Machine learning models parse structure and context, reducing breaks when DOMs shift. Expanded Reach: With NLP and Computer Vision, scrapers can detect text in images, parse user-generated content, or handle dynamic elements. Lower Maintenance: Systems self-adjust to new patterns, freeing you from constant patchwork fixes. The Road Ahead: A Roadmap for Intelligent Scraping AI-driven web scraping is no mere patch; it’s a stepping stone to a broader, more intelligent data ecosystem. Below is a conceptual roadmap highlighting emerging approaches and evolutions you can expect in the field. Generative Models for Real-Time Adaptation Large Language Models can analyze evolving or ambiguous site structures without relying on strictly defined rules. This allows a scraper to “read” the site’s content, locate relevant sections as they appear, and even interpret instructions such as “click the ‘Show More’ button to load reviews.” Multi-Modal Understanding Modern websites often include images, videos, and other visual elements in addition to text. Computer Vision can detect product photos, brand logos, or text within images, while NLP focuses on user comments and discussions. Together, these methods build a more complete picture of the data available on any given site. Agent-Based Scraping Scraping tools powered by AI agents can replicate user actions, including clicking through pages, scrolling, or filling out forms. This agent-based approach also adapts workflows automatically—retrying or rerouting when confronted with blocks—resulting in more resilient and thorough data extraction. Data Ecosystem Integrations Scraping is frequently just one component of an overarching analytics workflow. Systems can consume real-time data directly from scrapers to power advanced tasks such as dynamic pricing, live sentiment monitoring, or other automated analyses, reducing the need for manual oversight. Hybrid Approaches Some sites remain relatively stable or straightforward, making rule-based scraping methods sufficient. Others require continuous adaptation. A hybrid solution delegates simpler tasks to conventional scrapers while directing AI-driven components at complex or frequently changing sites. As these techniques develop, web scraping is poised to become an increasingly flexible and intelligent means of capturing online information—adapting automatically to changing environments and integrating seamlessly with broader data platforms. Key Takeaways AI Transforms Scraping from Brittle to Adaptive Instead of focusing on fixed HTML patterns, modern solutions learn context, interpret visuals, and maintain high accuracy even amid site changes. Real Possibilities Extend Beyond Traditional Data Extraction With NLP and Computer Vision, your pipeline can delve into areas like brand sentiment, product image recognition, and rich user interactions. The Roadmap is Bigger Than Just “Better Scraping” Expect generative AI, multi-m
In a data-intensive environment, the ability to gather and interpret information from the web is critical for many organizations. Traditional web scraping—once a primary method of obtaining online data—now struggles with increasingly dynamic site structures and anti-automation strategies. AI offers a more adaptive, learning-oriented approach that responds to shifts in web content and reveals insights where conventional methods fall short.
Why AI Matters in Web Scraping
Web scraping has traditionally relied on fixed rules or selector-based parsing to collect data. As websites become more interactive and frequently modify their structures, these rigid methods often fail. Some common obstacles include:
- Frequent DOM Changes: Sites update their layouts regularly, breaking scrapers that rely on specific HTML element selectors.
- JavaScript-Heavy Content: Traditional scrapers may not capture asynchronously loaded or user-triggered content.
- Dynamic Interactions: Pop-ups, infinite scrolling, or multi-step forms can require more advanced navigation strategies.
Incorporating AI can help address these issues by making scrapers more adaptive. Through techniques like Natural Language Processing and Computer Vision, an AI-enhanced approach can parse textual meaning, recognize on-page elements, and handle dynamic content more reliably. This reduces the need for frequent manual updates while allowing for deeper, more insightful data extraction.
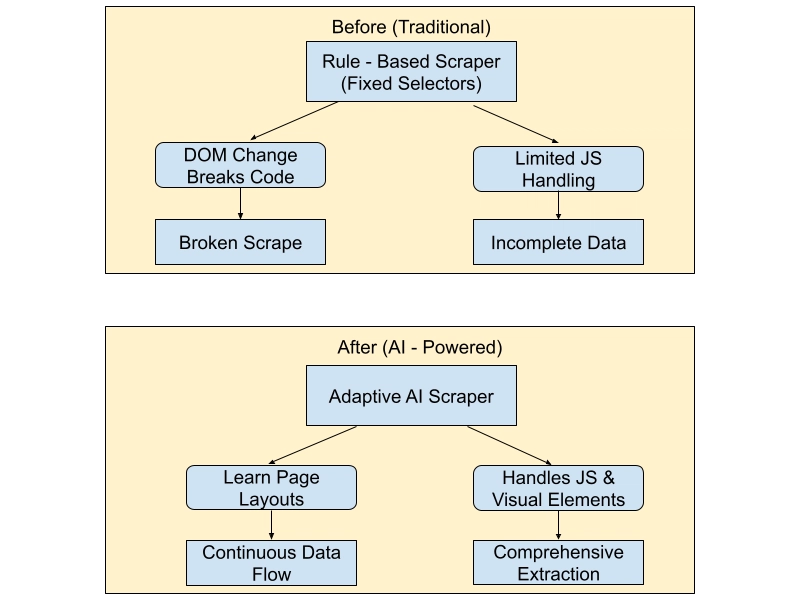
How AI Overcomes These Obstacles: Before & After
To understand the leap from rule-based to AI-powered scraping, let’s visualize a simple before-and-after scenario.
Before: Rule-Based Scrapers
- Brittle Selectors: If a website changes minor HTML tags or rearranges containers, your scraper likely breaks.
- Surface-Level Data: Text-based matches capture only explicit elements; interactive or visually-embedded data remains untouched.
- High Maintenance: Developers must constantly update code, dealing with recurring site changes.
After: AI-Powered Scrapers
- Adaptive Learning: Machine learning models parse structure and context, reducing breaks when DOMs shift.
- Expanded Reach: With NLP and Computer Vision, scrapers can detect text in images, parse user-generated content, or handle dynamic elements.
- Lower Maintenance: Systems self-adjust to new patterns, freeing you from constant patchwork fixes.
The Road Ahead: A Roadmap for Intelligent Scraping
AI-driven web scraping is no mere patch; it’s a stepping stone to a broader, more intelligent data ecosystem. Below is a conceptual roadmap highlighting emerging approaches and evolutions you can expect in the field.
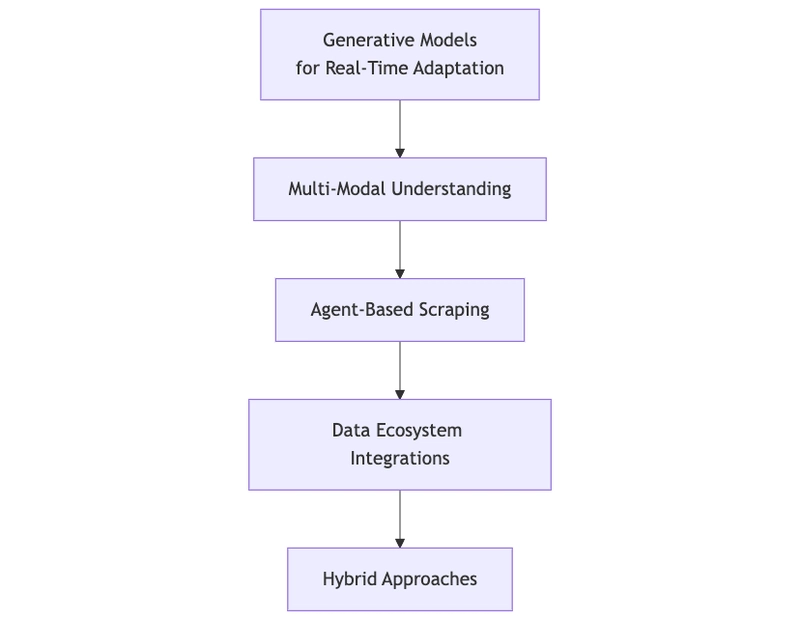
Generative Models for Real-Time Adaptation
Large Language Models can analyze evolving or ambiguous site structures without relying on strictly defined rules. This allows a scraper to “read” the site’s content, locate relevant sections as they appear, and even interpret instructions such as “click the ‘Show More’ button to load reviews.”Multi-Modal Understanding
Modern websites often include images, videos, and other visual elements in addition to text. Computer Vision can detect product photos, brand logos, or text within images, while NLP focuses on user comments and discussions. Together, these methods build a more complete picture of the data available on any given site.Agent-Based Scraping
Scraping tools powered by AI agents can replicate user actions, including clicking through pages, scrolling, or filling out forms. This agent-based approach also adapts workflows automatically—retrying or rerouting when confronted with blocks—resulting in more resilient and thorough data extraction.Data Ecosystem Integrations
Scraping is frequently just one component of an overarching analytics workflow. Systems can consume real-time data directly from scrapers to power advanced tasks such as dynamic pricing, live sentiment monitoring, or other automated analyses, reducing the need for manual oversight.Hybrid Approaches
Some sites remain relatively stable or straightforward, making rule-based scraping methods sufficient. Others require continuous adaptation. A hybrid solution delegates simpler tasks to conventional scrapers while directing AI-driven components at complex or frequently changing sites.
As these techniques develop, web scraping is poised to become an increasingly flexible and intelligent means of capturing online information—adapting automatically to changing environments and integrating seamlessly with broader data platforms.
Key Takeaways
AI Transforms Scraping from Brittle to Adaptive
Instead of focusing on fixed HTML patterns, modern solutions learn context, interpret visuals, and maintain high accuracy even amid site changes.
Real Possibilities Extend Beyond Traditional Data Extraction With NLP and Computer Vision, your pipeline can delve into areas like brand sentiment, product image recognition, and rich user interactions.
The Roadmap is Bigger Than Just “Better Scraping”
Expect generative AI, multi-modal analysis, and agent-based workflows, integrating seamlessly with data lakes, analytics engines, or real-time dashboards.
A Catalyst for Innovation
AI-powered scraping isn’t simply about capturing data faster—it’s about unlocking new product ideas, deep research potential, and dynamic business strategies that thrive on timely, quality insights.
Whether you’re a data engineer exploring new techniques or a product leader seeking deeper data capabilities, combining AI with web scraping introduces a range of practical advantages. As data extraction becomes more adaptive and multi-modal, the opportunities for gaining timely insights and identifying emerging trends increase significantly. By incorporating these approaches, you can enhance your data strategy and continue uncovering new ways to leverage online information.
Ready to Explore Advanced Web Scraping?
If you’d like to learn more, discuss a specific use case, or need help executing a project, I’m here to assist. Feel free to:
Email me at tharian.john@anakin.company
Schedule a 30-minute call: https://calendly.com/tharian-john-anakin/30min
I’m Tharian John from Anakin, and I look forward to helping you unlock new possibilities in web scraping.



